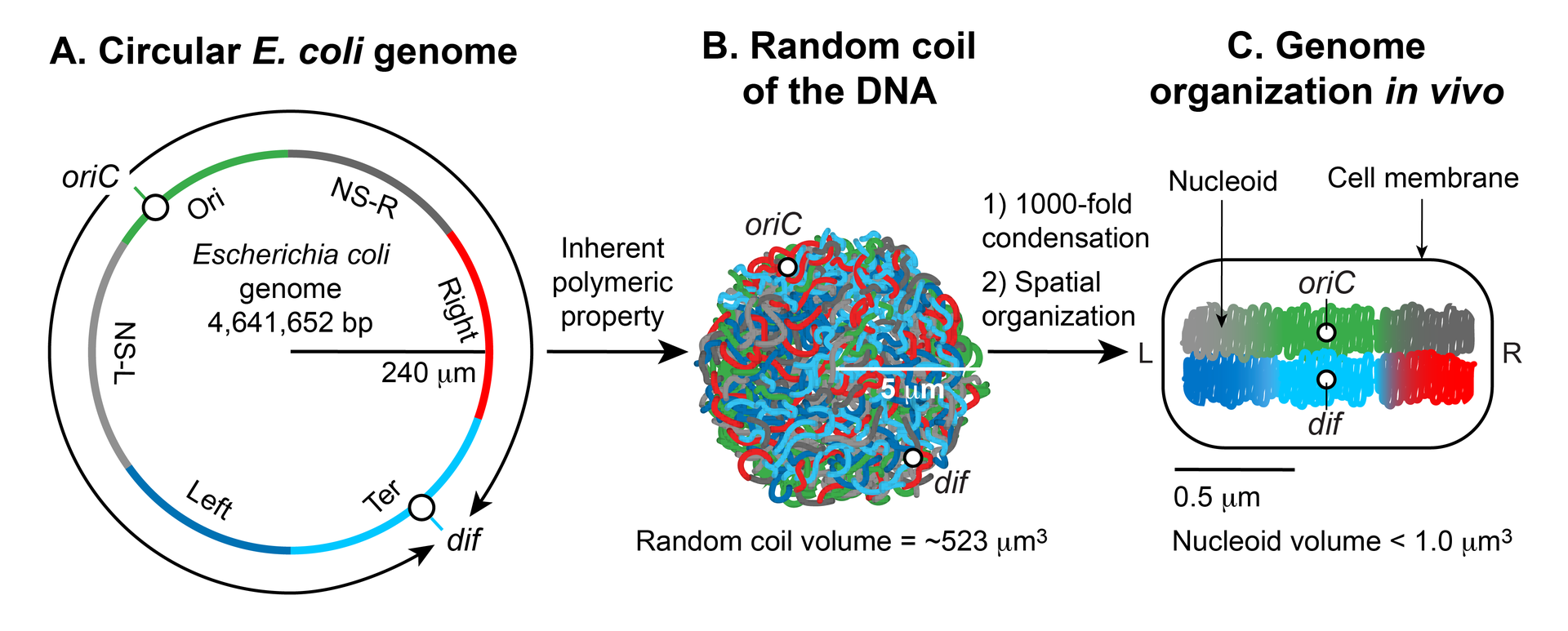
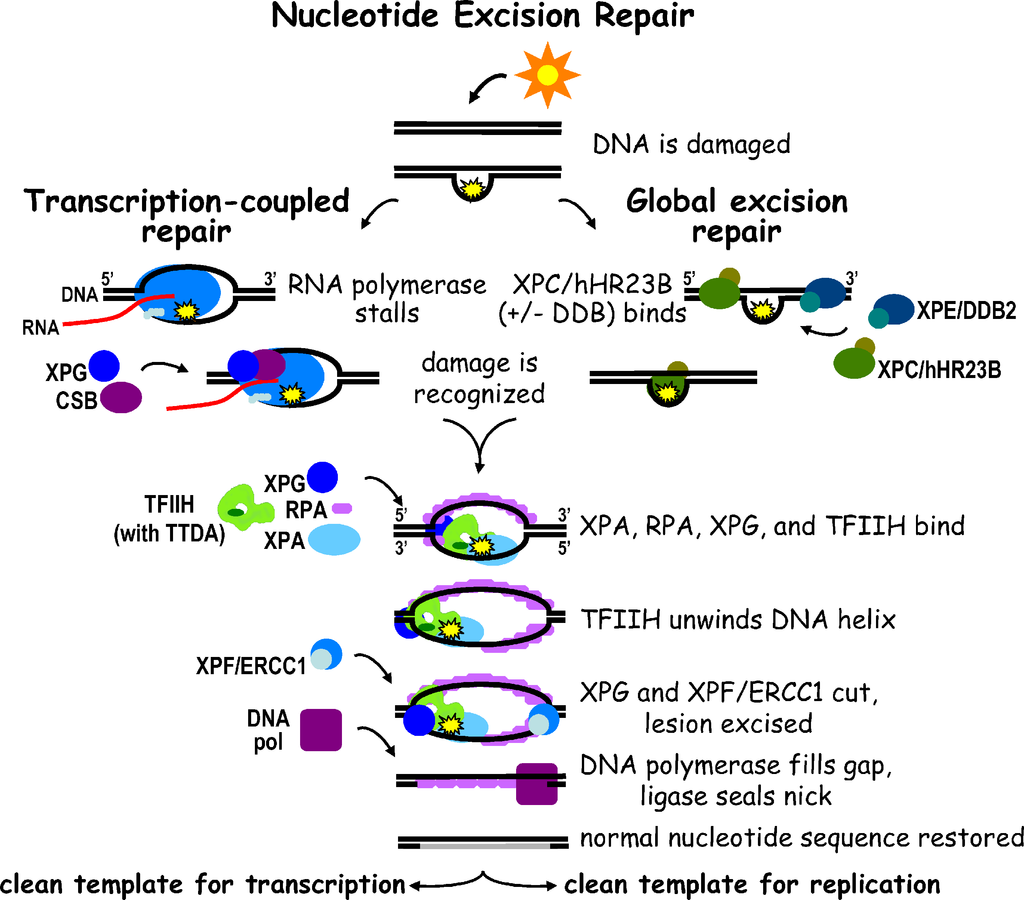
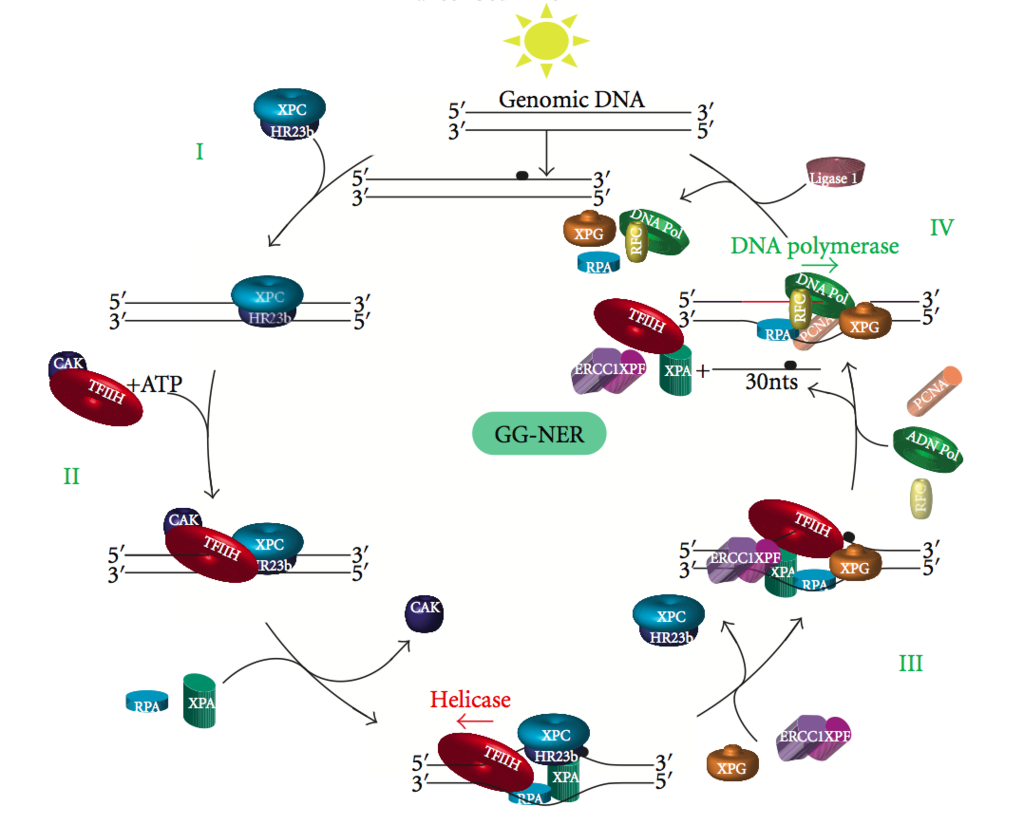
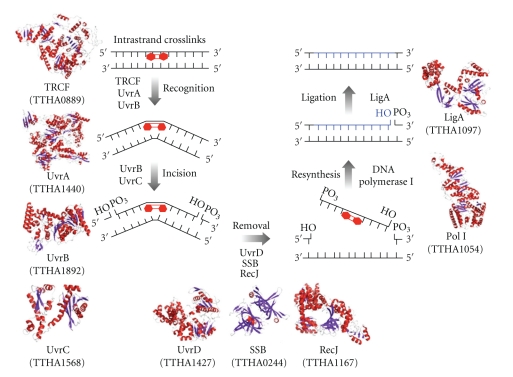
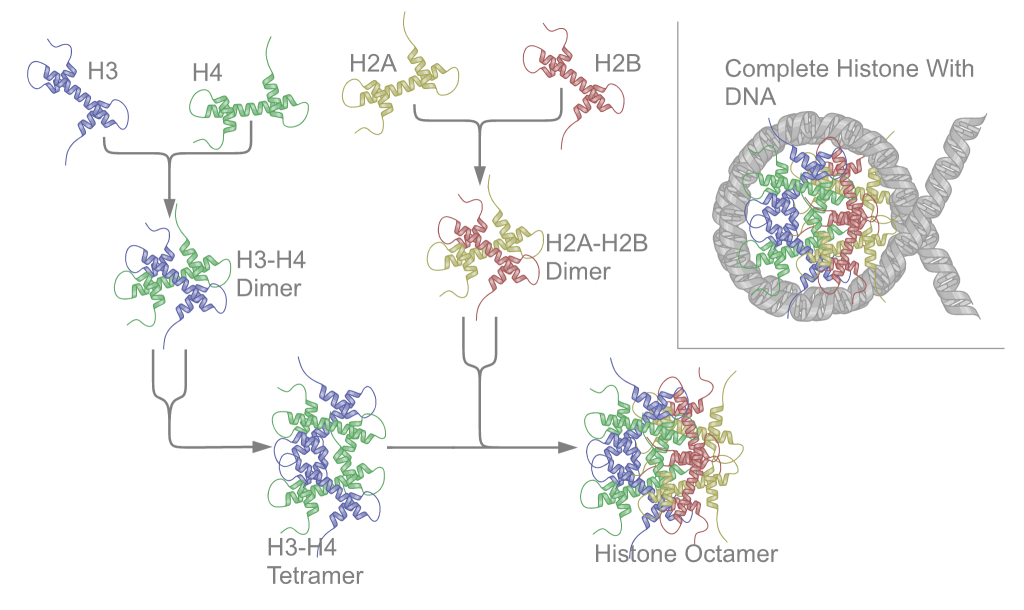
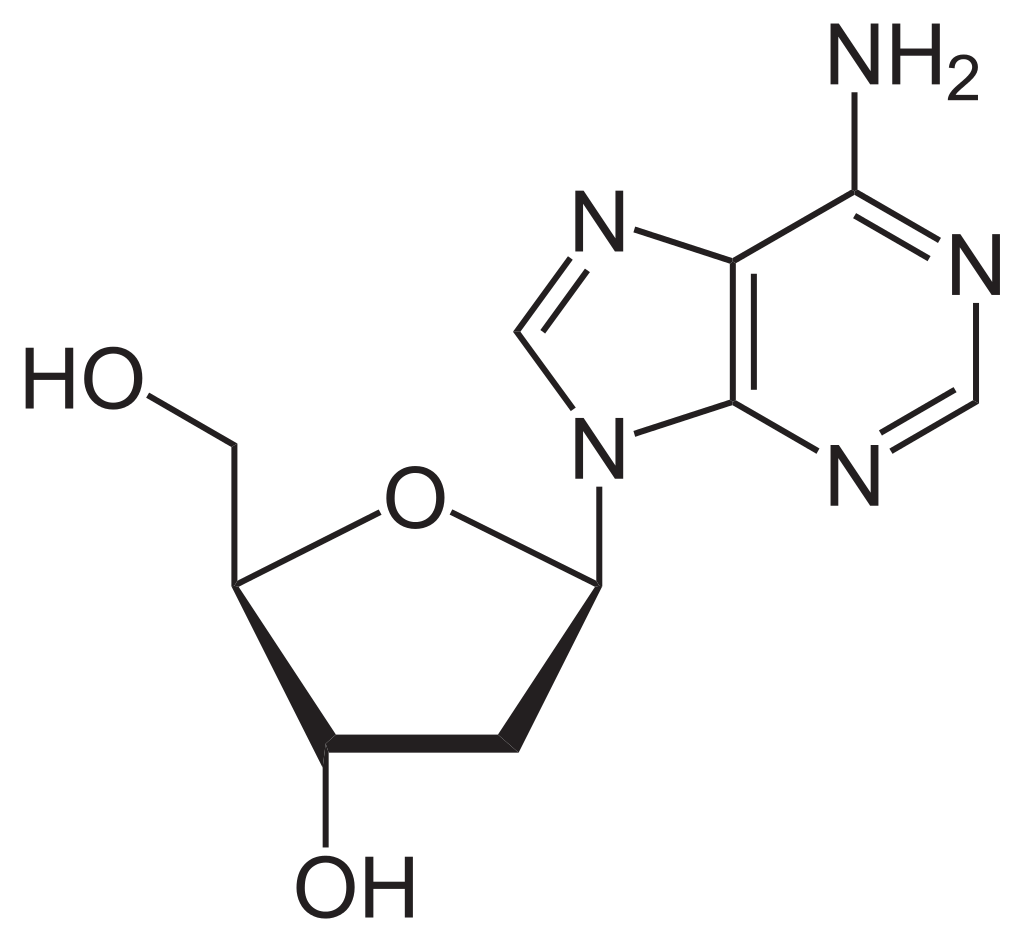
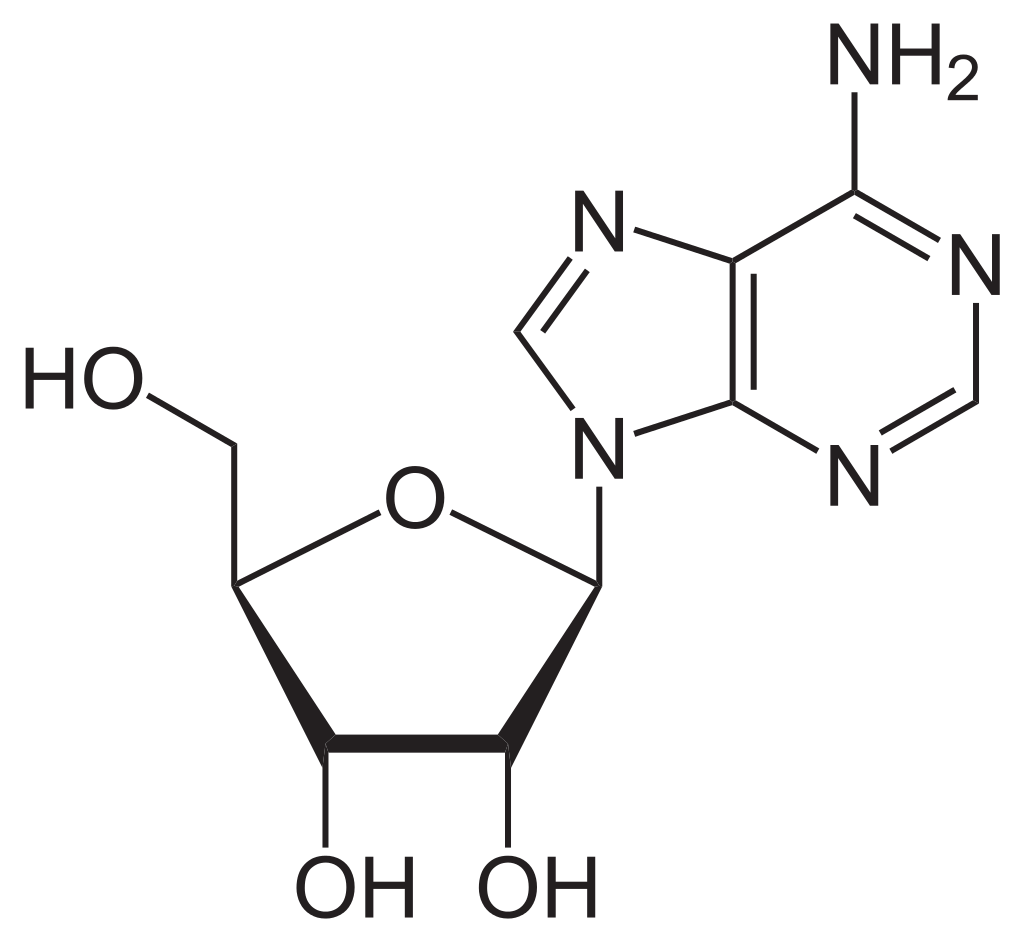
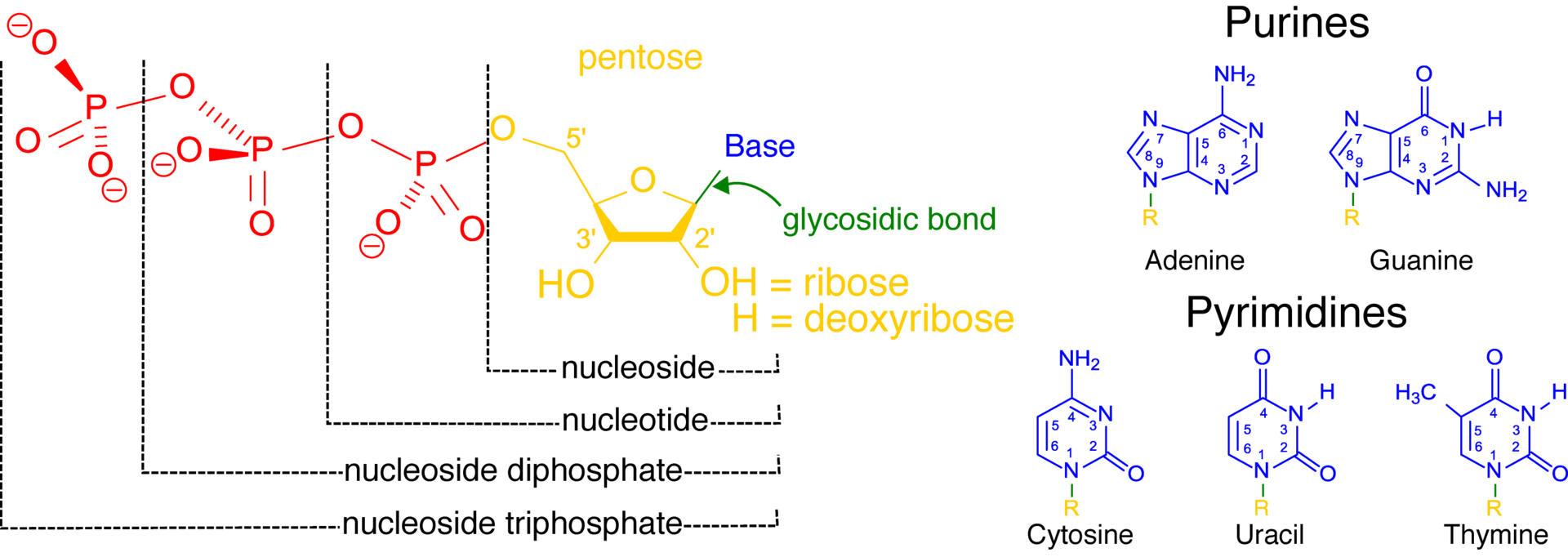
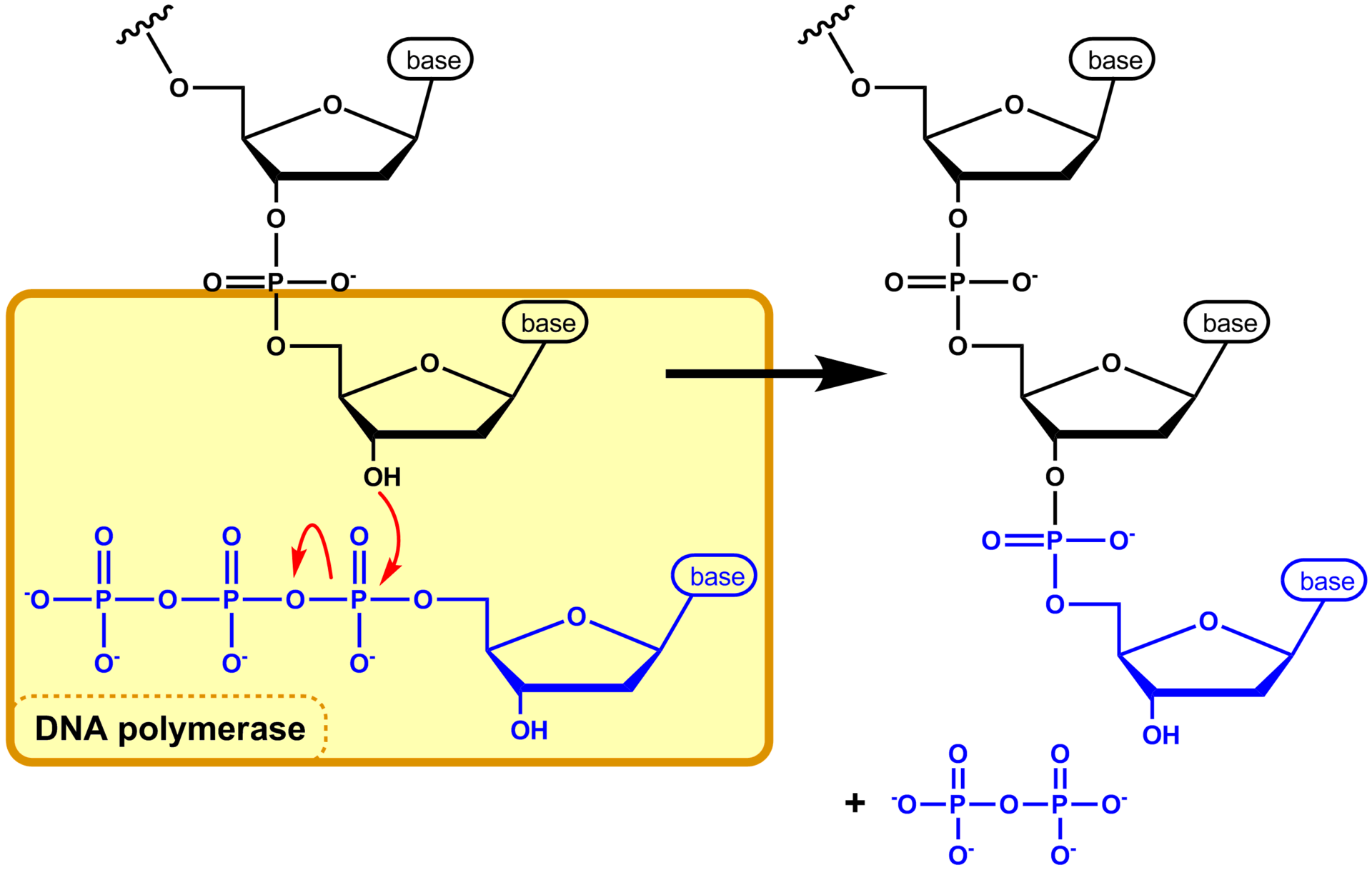
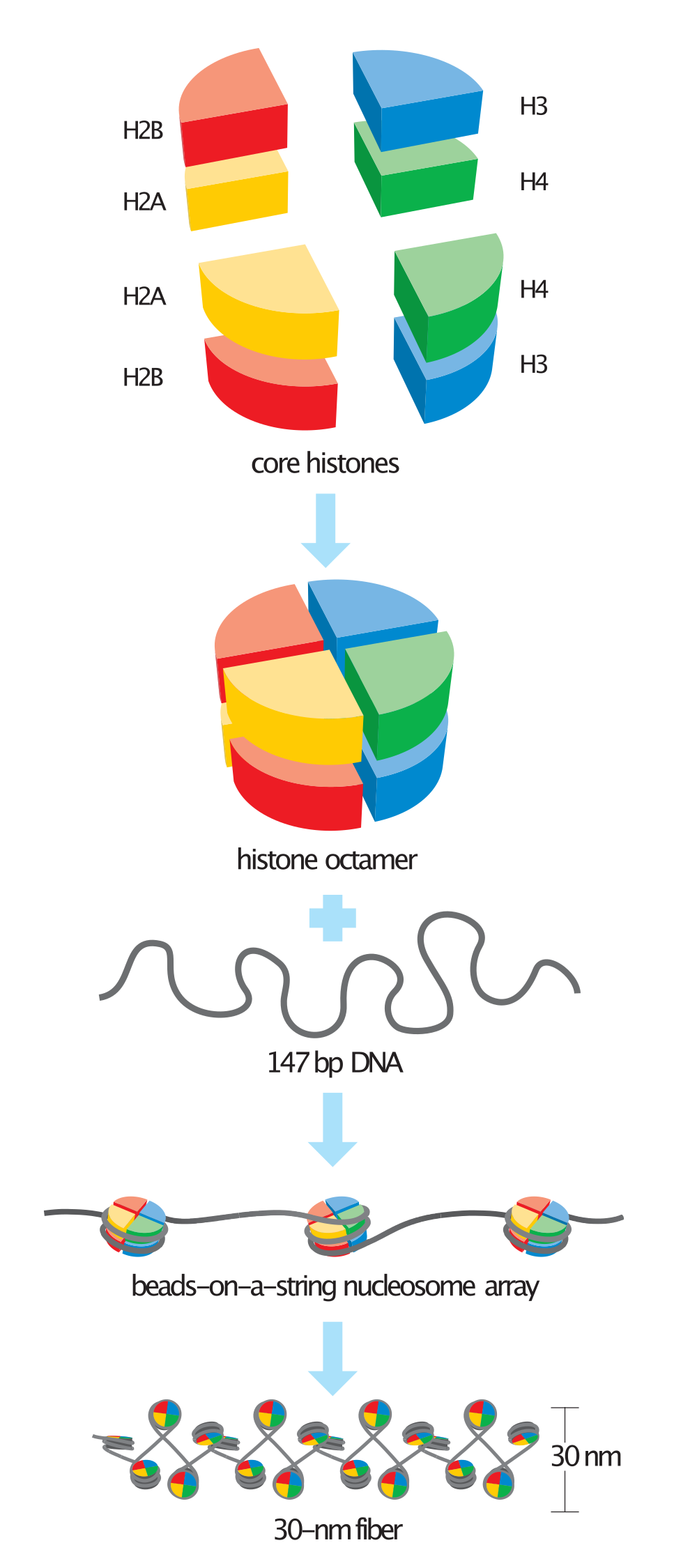
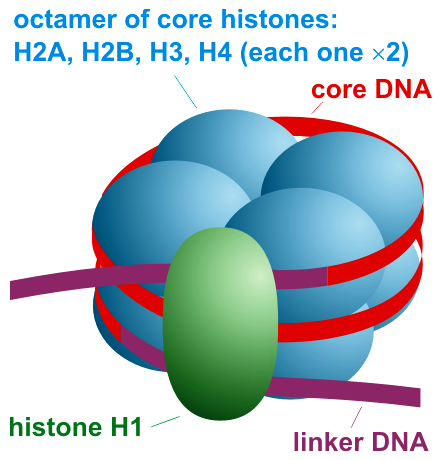
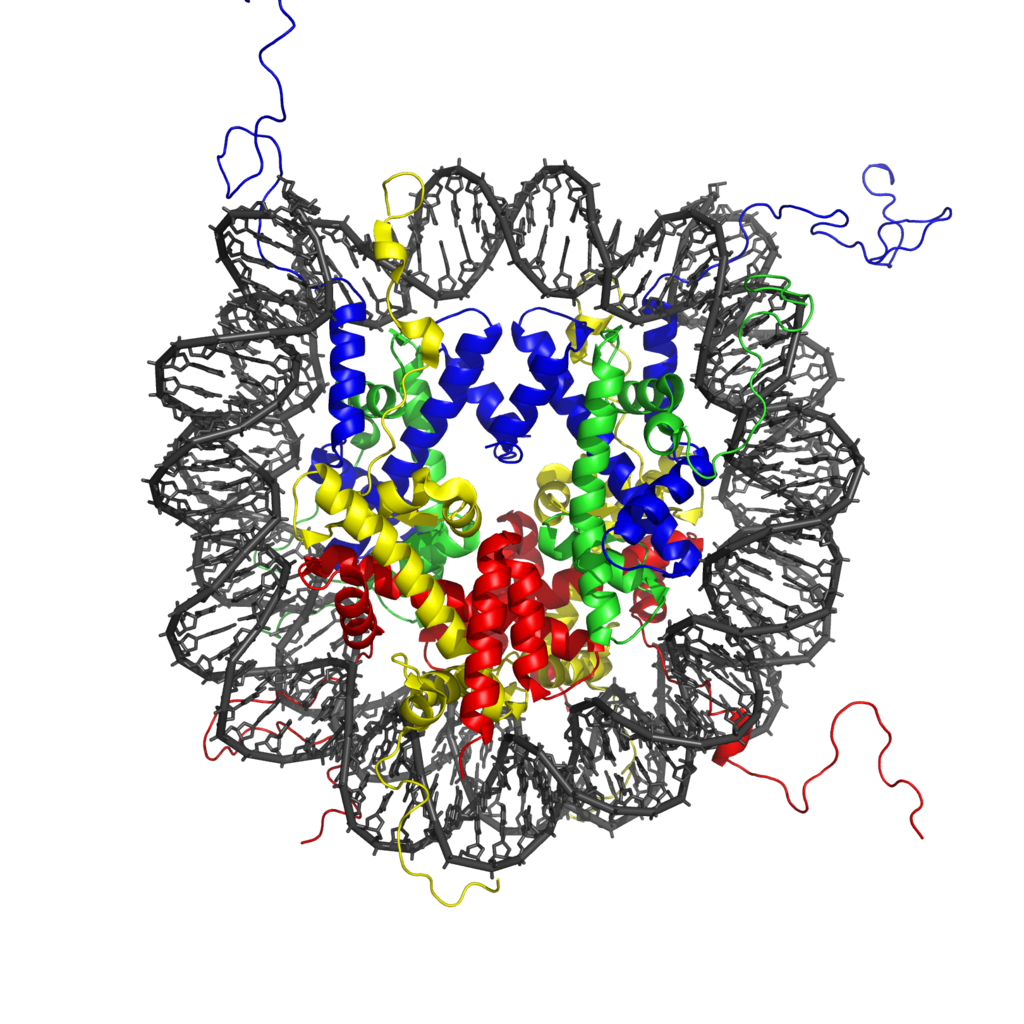
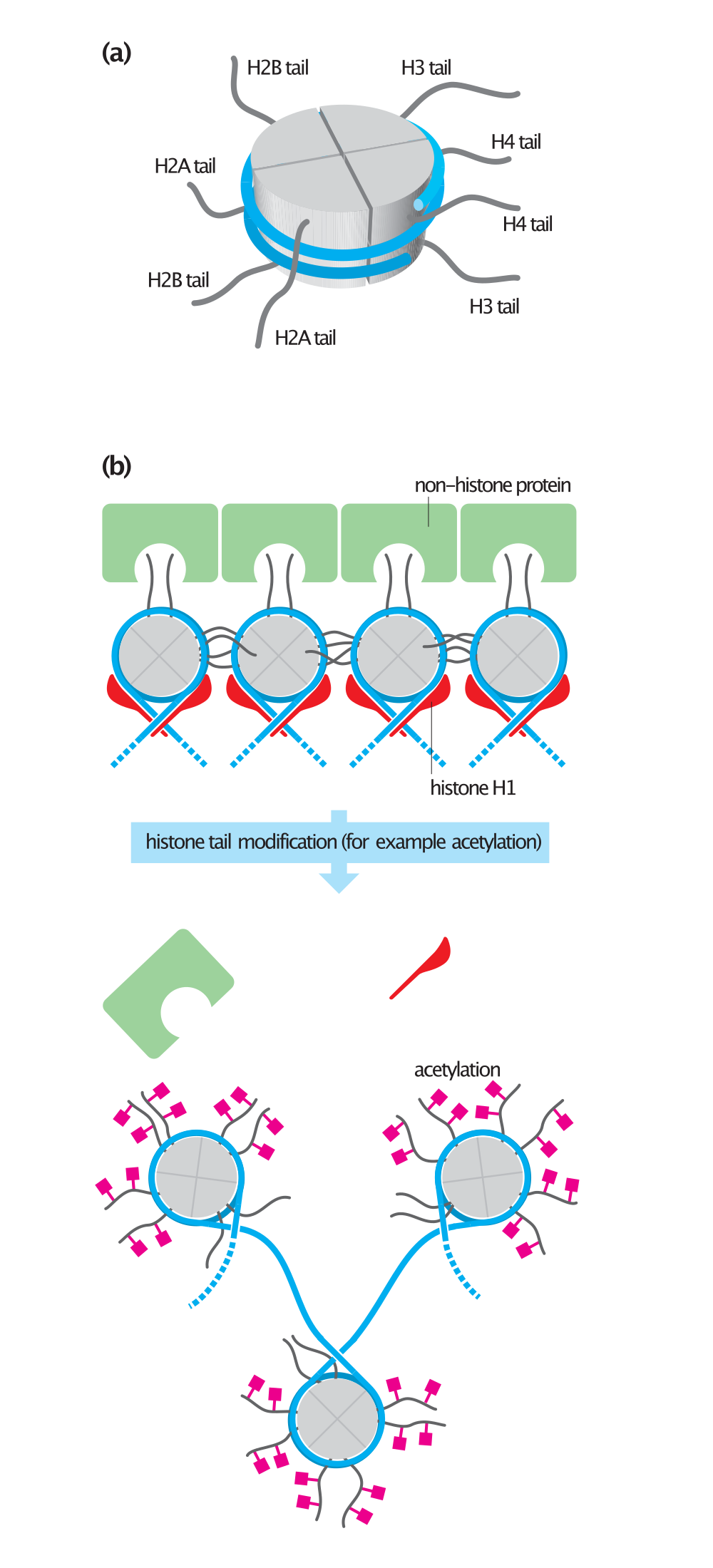
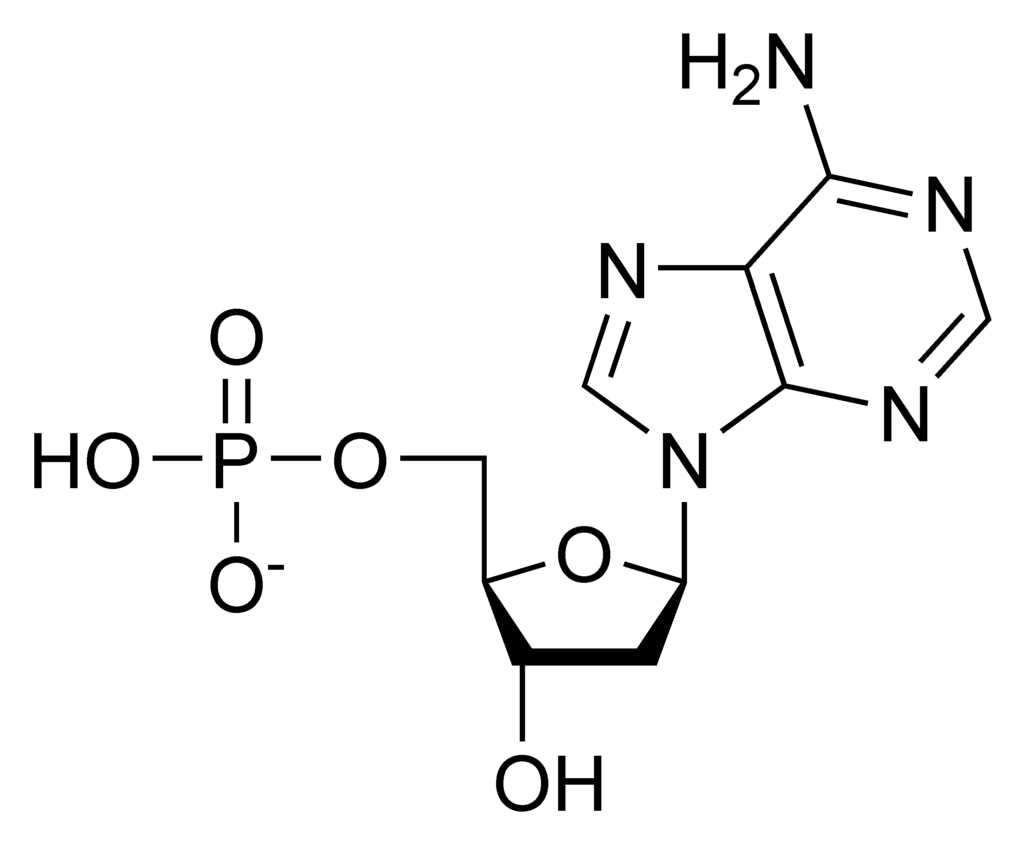
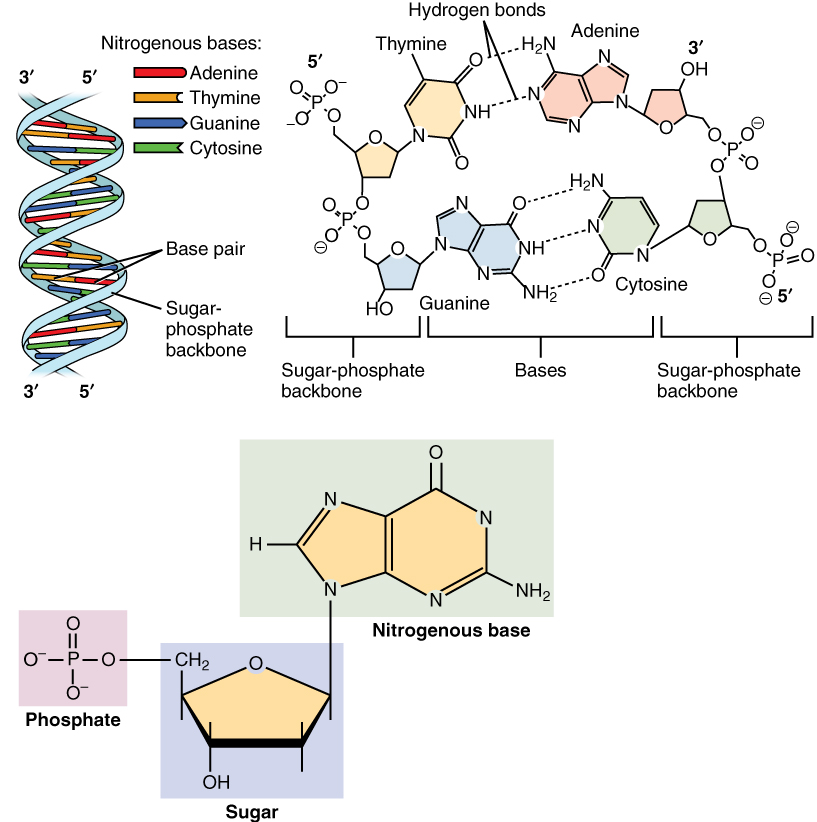
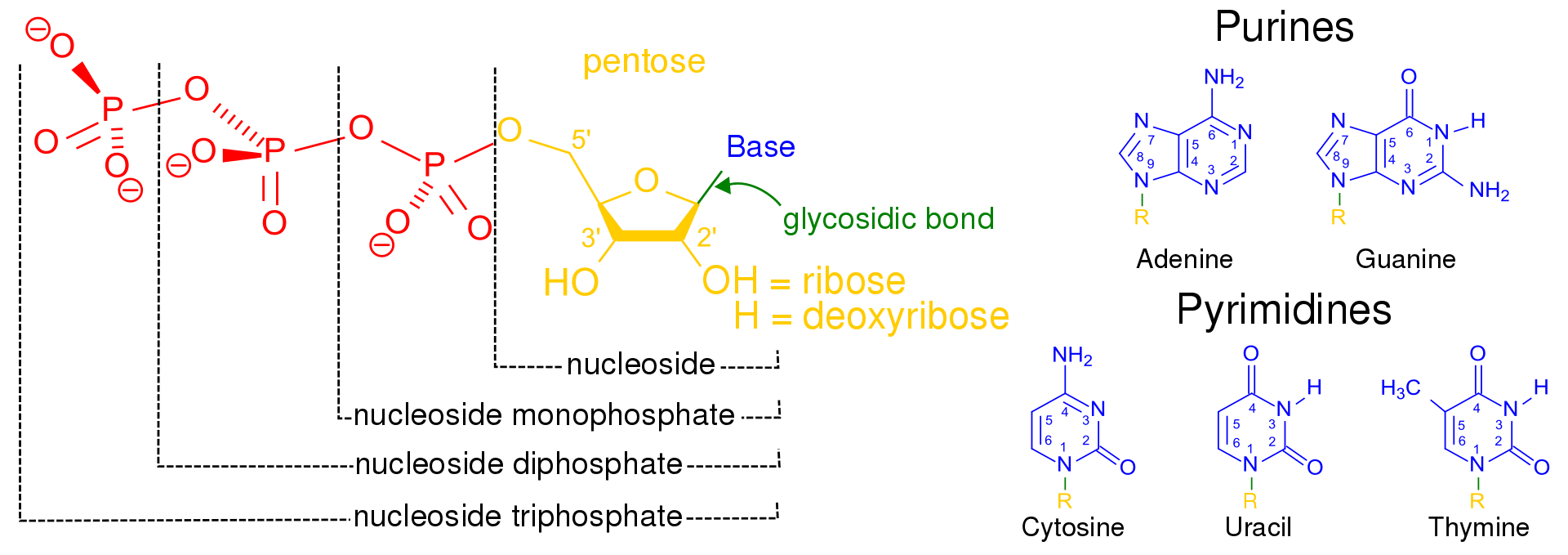
Chemical structure of a polypeptide macromolecule.
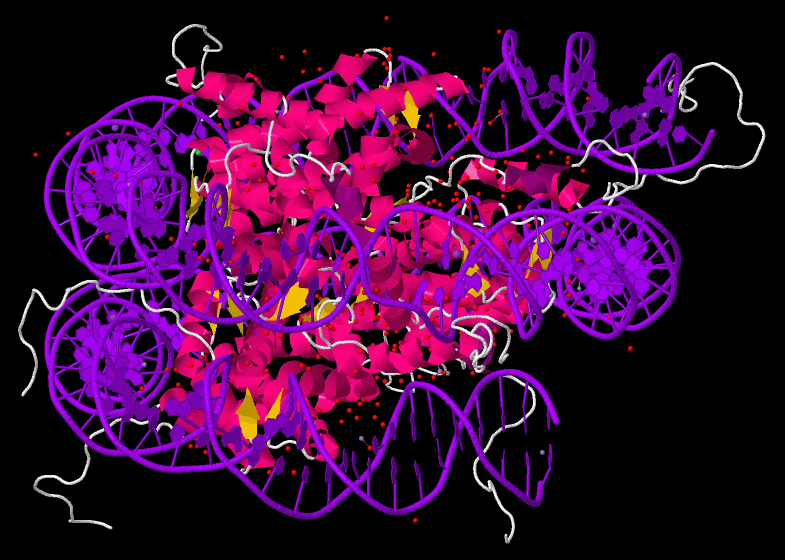
major vault proteinMajor vault protein is a protein that in humans is encoded by the MVPgene. 78 copies of the protein assemble into the large compartments called vaults, illustrated and discussed in the article on Vault (organelle).(W)
Structure of the MVP protein. Based on PyMOL rendering of PDB 1y7x.
mass spectrometry
Mass spectrometry (MS) is an analytical technique that measures the mass-to-charge ratio of ions. The results are typically presented as a mass spectrum, a plot of intensity as a function of the mass-to-charge ratio. Mass spectrometry is used in many different fields and is applied to pure samples as well as complex mixtures.
A mass spectrum is a plot of the ion signal as a function of the mass-to-charge ratio. These spectra are used to determine the elemental or isotopic signature of a sample, the masses of particles and of molecules, and to elucidate the chemical identity or structure of molecules and other chemical compounds.
In a typical MS procedure, a sample, which may be solid, liquid, or gaseous, is ionized, for example by bombarding it with electrons. This may cause some of the sample's molecules to break into charged fragments or simply become charged without fragmenting. These ions are then separated according to their mass-to-charge ratio, for example by accelerating them and subjecting them to an electric or magnetic field: ions of the same mass-to-charge ratio will undergo the same amount of deflection. The ions are detected by a mechanism capable of detecting charged particles, such as an electron multiplier. Results are displayed as spectra of the signal intensity of detected ions as a function of the mass-to-charge ratio. The atoms or molecules in the sample can be identified by correlating known masses (e.g. an entire molecule) to the identified masses or through a characteristic fragmentation pattern. (W)
Schematics of a simple mass spectrometer with sector type mass analyzer. This one is for the measurement of carbon dioxide isotope ratios (IRMS) as in the carbon-13urea breath test.
mass spectrometry imagingMass spectrometry imaging (MSI) is a technique used in mass spectrometry to visualize the spatial distribution of molecules, as biomarkers,metabolites,peptides or proteins by their molecular masses. After collecting a mass spectrum at one spot, the sample is moved to reach another region, and so on, until the entire sample is scanned. By choosing a peak in the resulting spectra that corresponds to the compound of interest, the MS data is used to map its distribution across the sample. This results in pictures of the spatially resolved distribution of a compound pixel by pixel. Each data set contains a veritable gallery of pictures because any peak in each spectrum can be spatially mapped. Despite the fact that MSI has been generally considered a qualitative method, the signal generated by this technique is proportional to the relative abundance of the analyte. Therefore, quantification is possible, when its challenges are overcome. Although widely used traditional methodologies like radiochemistry and immunohistochemistry achieve the same goal as MSI, they are limited in their abilities to analyze multiple samples at once, and can prove to be lacking if researchers do not have prior knowledge of the samples being studied. Most common ionization technologies in the field of MSI are DESI imaging,MALDI imaging and secondary ion mass spectrometry imaging (SIMS imaging(W)
Mouse kidney: (a) MALDI spectra from the tissue. (b) H&E stained tissue. N-glycans at m/z = 1996.7 (c) is located in the cortex and medulla while m/z = 2158.7 (d) is in the cortex, (e) An overlay image of these two masses, (f) untreated control tissue.
Mouse kidney. (a) A MALDI spectra from the tissue. (b) H&E stained tissue. The labeled peaks correspond to N-glycans that have been reported for the mouse kidney. Two of these ions were selected and their tissue localization was examined. Hex4dHex2HexNAc5 at m/z = 1996.7 (c) is located in the cortex and medulla while Hex5dHex2HexNAc5 m/z = 2158.7 (d) is more abundant in the cortex of the mouse kidney. An overlay image of these two masses is also shown (e), as well as the corresponding image from untreated control tissues (f).
membrane lipidMembrane lipids are a group of compounds (structurally similar to fats and oils) which form the double-layered surface of all cells (lipid bilayer). The three major classes of membrane lipids are phospholipids, glycolipids, and cholesterol. Lipids are amphiphilic: they have one end that is soluble in water ('polar') and an ending that is soluble in fat ('nonpolar'). By forming a double layer with the polar ends pointing outwards and the nonpolar ends pointing inwards membrane lipids can form a 'lipid bilayer' which keeps the watery interior of the cell separate from the watery exterior. The arrangements of lipids and various proteins, acting as receptors and channel pores in the membrane, control the entry and exit of other molecules and ions as part of the cell's metabolism. In order to perform physiological functions, membrane proteins are facilitated to rotate and diffuse laterally in two dimensional expanse of lipid bilayer by the presence of a shell of lipids closely attached to protein surface, called annular lipid shell.(W)
Space-filling models of (a) sphingomyelin and (b) cholesterol. This figure shows the inverted cone-like shape of a common sphingolipid (sphingomyelin) and the cone-like shape of cholesterol based on the area of space occupied by the hydrophobic and hydrophilic regions.
membrane potential
Membrane potential (also transmembrane potential or membrane voltage) is the difference in electric potential between the interior and the exterior of a biological cell. For the exterior of the cell, typical values of membrane potential, normally given in units of millivolts and denoted as mV, range from –40 mV to –80 mV.
All animal cells are surrounded by a membrane composed of a lipid bilayer with proteins embedded in it. The membrane serves as both an insulator and a diffusion barrier to the movement of ions. Transmembrane proteins, also known as ion transporter or ion pump proteins, actively push ions across the membrane and establish concentration gradients across the membrane, and ion channels allow ions to move across the membrane down those concentration gradients. Ion pumps and ion channels are electrically equivalent to a set of batteries and resistors inserted in the membrane, and therefore create a voltage between the two sides of the membrane.
Almost all plasma membranes have an electrical potential across them, with the inside usually negative with respect to the outside. The membrane potential has two basic functions. First, it allows a cell to function as a battery, providing power to operate a variety of "molecular devices" embedded in the membrane. Second, in electrically excitable cells such as neurons and muscle cells, it is used for transmitting signals between different parts of a cell. Signals are generated by opening or closing of ion channels at one point in the membrane, producing a local change in the membrane potential. This change in the electric field can be quickly affected by either adjacent or more distant ion channels in the membrane. Those ion channels can then open or close as a result of the potential change, reproducing the signal. (W)
Differences in the concentrations of ions on opposite sides of a cellular membrane lead to a voltage called the membrane potential. Typical values of membrane potential are in the range –40 mV to –70 mV. Many ions have a concentration gradient across the membrane, including potassium (K+), which is at a high concentration inside and a low concentration outside the membrane. Sodium (Na+) and chloride (Cl-) ions are at high concentrations in the extracellular region, and low concentrations in the intracellular regions. These concentration gradients provide the potential energy to drive the formation of the membrane potential. This voltage is established when the membrane has permeability to one or more ions. In the simplest case, illustrated here, if the membrane is selectively permeable to potassium, these positively charged ions can diffuse down the concentration gradient to the outside of the cell, leaving behind uncompensated negative charges. This separation of charges is what causes the membrane potential. Note that the system as a whole is electro-neutral. The uncompensated positive charges outside the cell, and the uncompensated negative charges inside the cell, physically line up on the membrane surface and attract each other across the lipid bilayer. Thus, the membrane potential is physically located only in the immediate vicinity of the membrane. It is the separation of these charges across the membrane that is the basis of the membrane voltage. This diagram is only an approximation of the ionic contributions to the membrane potential. Other ions including sodium, chloride, calcium, and others play a more minor role, even though they have strong concentration gradients, because they have more limited permeability than potassium. Key: Blue pentagons – sodium ions; Purple squares – potassium ions; Yellow circles – chloride ions; Orange rectangles – membrane-impermeable anions (these arise from a variety of sources including proteins). The large purple structure with an arrow represents a transmembrane potassium channel and the direction of net potassium movement..
Electric field (arrows) and contours of constant voltage created by a pair of oppositely charged objects. The electric field is at right angles to the voltage contours, and the field is strongest where the spacing between contours is the smallest..
Ions (pink circles) will flow across a membrane from the higher concentration to the lower concentration (down a concentration gradient), causing a current. However, this creates a voltage across the membrane that opposes the ions' motion. When this voltage reaches the equilibrium value, the two balance and the flow of ions stops.
The cell membrane, also called the plasma membrane or plasmalemma, is a semipermeable lipid bilayer common to all living cells. It contains a variety of biological molecules, primarily proteins and lipids, which are involved in a vast array of cellular processes.
The cell membrane, also called the plasma membrane or plasmalemma, is a semipermeable lipid bilayer common to all living cells. It contains a variety of biological molecules, primarily proteins and lipids, which are involved in a vast array of cellular processes. It also serves as the attachment point for both the intracellular cytoskeleton and, if present, the cell wall.
Facilitated diffusion in cell membranes, showing ion channels and carrier proteins.
The sodium-potassium pump uses energy derived from ATP to exchange sodium for potassium ions across the membrane.
Example of primary active transport, where energy from hydrolysis of ATP is directly coupled to the movement of a specific substance across a membrane independent of any other species.
Despite the small differences in their radii, ions rarely go through the "wrong" channel. For example, sodium or calcium ions rarely pass through a potassium channel.
Comparison of the sizes of Group I ions, together with chloride and calcium ions. The ionic radii were taken from the 6-coordinated crystalline ionic radii from page 12-14 to 12-15 in the 83rd edition of the CRC Handbook of Chemistry and Physics.
Depiction of the open potassium channel, with the potassium ion shown in purple in the middle, and hydrogen atoms omitted. When the channel is closed, the passage is blocked.
Ligand-gated calcium channel in closed and open states.
Intracellular and extracellular fluids have different ion compositions. Extracellular fluid has relatively high concentrations of sodium ions, which are positively-charged, and chloride ions, which are negatively charged. In contrast, in intracellular fluid, the most abundant positively-charged ion is potassium, and most of the negative charges are carried by proteins. The negatively charged proteins cannot pass through the cell membrane, so we can think of these negative charges as trapped inside the cell.
membrane transport
In cellular biology, membrane transport refers to the collection of mechanisms that regulate the passage of solutes such as ions and small molecules through biological membranes, which are lipid bilayers that contain proteins embedded in them. The regulation of passage through the membrane is due to selective membrane permeability - a characteristic of biological membranes which allows them to separate substances of distinct chemical nature. In other words, they can be permeable to certain substances but not to others.
The movements of most solutes through the membrane are mediated by membrane transport proteins which are specialized to varying degrees in the transport of specific molecules. As the diversity and physiology of the distinct cells is highly related to their capacities to attract different external elements, it is postulated that there is a group of specific transport proteins for each cell type and for every specific physiological stage. This differential expression is regulated through the differential transcription of the genes coding for these proteins and its translation, for instance, through genetic-molecular mechanisms, but also at the cell biology level: the production of these proteins can be activated by cellular signaling pathways, at the biochemical level, or even by being situated in cytoplasmic vesicles. (W)
Diagram of a cell membrane 1. phospholipid 2. cholesterol 3. glycolipid 4. sugar 5. polytopic protein (transmembrane protein) 6. monotopic protein (here, a glycoprotein) 7. monotopic protein anchored by a phospholipid 8. peripheral monotopic protein (here, a glycoprotein).
Relative permeability of a phospholipid bilayer to various substances
A semipermeable membrane separates two compartments of different solute concentrations: over time, the solute will diffuse until equilibrium is reached..
Uniport, symport, and antiport of molecules through membranes.
Channel-mediated diffusion occurs via channel proteins that allow ions and small water-soluble molecules to pass in and out of the cell.
membrane transport protein
A membrane transport protein (or simply transporter) is a membrane protein involved in the movement of ions, small molecules, and macromolecules, such as another protein, across a biological membrane. Transport proteins are integraltransmembrane protein; that is they exist permanently within and span the membrane across which they transport substances. The proteins may assist in the movement of substances by facilitated diffusion or active transport. The two main types of proteins involved in such transport are broadly categorized as either channels or carriers. The solute carriers and atypical SLCs are secondary active or facilitative transporters in humans. Collectively membrane transporters and channels are transportome. Transportomes govern cellular influx and efflux of not only ions and nutrients but drugs as well. (W)
The action of the sodium-potassium pump is an example of primary active transport. The two carrier proteins on the left are using ATP to move sodium out of the cell against the concentration gradient. The proteins on the right are using secondary active transport to move potassium into the cell.
Example of primary active transport, where energy from hydrolysis of ATP is directly coupled to the movement of a specific substance across a membrane independent of any other species.
Facilitated diffusion in the cell membrane, showing ion channels (left) and carrier proteins (three on the right).
Facilitated diffusion involves the use of a protein to facilitate the movement of molecules across the membrane. In some cases, molecules pass through channels within the protein,In other cases, the protein changes shape, allowing molecules to pass through.
This picture represents symport. The yellow triangle shows the concentration gradient for the yellow circles while the green triangle shows the concentration gradient for the green circles and the purple rods are the transport protein bundle. The green circles are moving against their concentration gradient through a transport protein which requires energy while the yellow circles move down their concentration gradient which releases energy. The yellow circles produce more energy through chemiosmosis than what is required to move the green circles so the movement is coupled and some energy is cancelled out. One example is the lactose permease which allows protons to go down its concentration gradient into the cell while also pumping lactose into the cell.
The picture represents uniport. The yellow triangle shows the concentration gradient for the yellow circles and the purple rods are the transport protein bundle. Since they move down their concentration gradient through a transport protein, they can release energy as a result of chemiosmosis. One example is GLUT1 which moves glucose down its concentration gradient into the cell..
This picture represents antiport. The yellow triangle shows the concentration gradient for the yellow circles while the blue triangle shows the concentration gradient for the blue circles and the purple rods are the transport protein bundle. The blue circles are moving against their concentration gradient through a transport protein which requires energy while the yellow circles move down their concentration gradient which releases energy. The yellow circles produce more energy through chemiosmosis than what is required to move the blue circles so the movement is coupled and some energy is cancelled out. One example is the sodium-proton exchanger which allows protons to go down their concentration gradient into the cell while pumping sodium out of the cell..
Transcription is when RNA is made from DNA. During transcription, RNA polymerase makes a copy of a gene from the DNA to mRNA as needed. This process is slightly different in eukaryotes and prokaryotes. One notable difference, however, is that prokaryotic RNA polymerase associates with DNA-processing enzymes during transcription so that processing can proceed during transcription. Therefore, this causes the new mRNA strand to become double stranded by producing a complementary strand known as the tRNA strand. Furthermore the RNA is unable to form structures from base-pairing. Moreover, the template for mRNA is the complementary strand of tRNA, which is identical in sequence to the anticodon sequence that the DNA binds to. The short-lived, unprocessed or partially processed product is termed precursor mRNA, or pre-mRNA; once completely processed, it is termed mature mRNA.
As in DNA, genetic information in mRNA is contained in the sequence of nucleotides, which are arranged into codons consisting of three base pairs each. Each codon codes for a specific amino acid, except the stop codons, which terminate protein synthesis. This process of translation of codons into amino acids requires two other types of RNA: transfer RNA, which recognises the codon and provides the corresponding amino acid, and ribosomal RNA (rRNA), the central component of the ribosome's protein-manufacturing machinery.
The structure of a mature eukaryotic mRNA. A fully processed mRNA includes a 5' cap,5' UTR,coding region,3' UTR, and poly(A) tail.
Diagramatic structure of a typical human protein coding mRNA including the untranslated regions (UTRs).It is drawn approximately to scale. The cap is only one modified base, average en:5' UTR length 170, en:3' UTR 700.
messenger RNA decapping
The process of messenger RNA decapping consists of hydrolysis of the 5' cap structure on the RNA exposing a 5' monophosphate. In eukaryotes, this 5' monophosphate is a substrate for the 5' exonuclease Xrn1 and the mRNA is quickly destroyed. There are many situations which may lead to the removal of the cap, some of which are discussed below.
In prokaryotes, the initial mRNA transcript naturally possesses a 5'-triphosphate group after bacterial transcription; the enzyme RppH removes a pyrophosphate molecule from the 5' end, converting the 5'-triphosphate to a 5'-monophosphate, triggering mRNA degradation by ribonucleases. (W)
Schematic representation of deadenylation-independent decapping in S. cerevisiae.
Metabolic network reconstruction and simulation allows for an in-depth insight into the molecular mechanisms of a particular organism. In particular, these models correlate the genome with molecular physiology. A reconstruction breaks down metabolic pathways (such as glycolysis and the citric acid cycle) into their respective reactions and enzymes, and analyzes them within the perspective of the entire network. In simplified terms, a reconstruction collects all of the relevant metabolic information of an organism and compiles it in a mathematical model. Validation and analysis of reconstructions can allow identification of key features of metabolism such as growth yield, resource distribution, network robustness, and gene essentiality. This knowledge can then be applied to create novel biotechnology.
In general, the process to build a reconstruction is as follows:
Draft a reconstruction
Refine the model
Convert model into a mathematical/computational representation
Evaluate and debug model through experimentation (W)
Metabolic network showing interactions between enzymes and metabolites in the Arabidopsis thaliana citric acid cycle. Enzymes and metabolites are the red dots and interactions between them are the lines..
Pathway Tools: A bioinformatics software package that assists in the construction of pathway/genome databases such as EcoCyc. Developed by Peter Karp and associates at the SRI International Bioinformatics Research Group, Pathway Tools has several components. Its PathoLogic module takes an annotated genome for an organism and infers probable metabolic reactions and pathways to produce a new pathway/genome database. Its MetaFlux component can generate a quantitative metabolic model from that pathway/genome database using flux-balance analysis. Its Navigator component provides extensive query and visualization tools, such as visualization of metabolites, pathways, and the complete metabolic network.
ERGO: A subscription-based service developed by Integrated Genomics. It integrates data from every level including genomic, biochemical data, literature, and high-throughput analysis into a comprehensive user friendly network of metabolic and nonmetabolic pathways.
KEGGtranslator: an easy-to-use stand-alone application that can visualize and convert KEGG files (KGML formatted XML-files) into multiple output formats. Unlike other translators, KEGGtranslator supports a plethora of output formats, is able to augment the information in translated documents (e.g., MIRIAM annotations) beyond the scope of the KGML document, and amends missing components to fragmentary reactions within the pathway to allow simulations on those. KEGGtranslator converts these files to SBML,BioPAX,SIF,SBGN, SBML with qualitative modeling extension, GML,GraphML,JPG,GIF,LaTeX, etc.
ModelSEED: An online resource for the analysis, comparison, reconstruction, and curation of genome-scale metabolic models. Users can submit genome sequences to the RAST annotation system, and the resulting annotation can be automatically piped into the ModelSEED to produce a draft metabolic model. The ModelSEED automatically constructs a network of metabolic reactions, gene-protein-reaction associations for each reaction, and a biomass composition reaction for each genome to produce a model of microbial metabolism that can be simulated using Flux Balance Analysis.
MetaMerge: algorithm for semi-automatically reconciling a pair of existing metabolic network reconstructions into a single metabolic network model.
CoReCo: algorithm for automatic reconstruction of metabolic models of related species. The first version of the software used KEGG as reaction database to link with the EC number predictions from CoReCo. Its automatic gap filling using atom map of all the reactions produce functional models ready for simulation.
In biochemistry, a metabolic pathway is a linked series of chemical reactions occurring within a cell. The reactants, products, and intermediates of an enzymatic reaction are known as metabolites, which are modified by a sequence of chemical reactions catalyzed by enzymes. In most cases of a metabolic pathway, the product of one enzyme acts as the substrate for the next. However, side products are considered waste and removed from the cell. These enzymes often require dietary minerals, vitamins, and other cofactors to function.
There are two types of metabolic pathways that are characterized by their ability to either synthesize molecules with the utilization of energy (anabolic pathway) or break down of complex molecules by releasing energy in the process (catabolic pathway). The two pathways complement each other in that the energy released from one is used up by the other. The degradative process of a catabolic pathway provides the energy required to conduct a biosynthesis of an anabolic pathway. In addition to the two distinct metabolic pathways is the amphibolic pathway, which can be either catabolic or anabolic based on the need for or the availability of energy.
Pathways are required for the maintenance of homeostasis within an organism and the flux of metabolites through a pathway is regulated depending on the needs of the cell and the availability of the substrate. The end product of a pathway may be used immediately, initiate another metabolic pathway or be stored for later use. The metabolism of a cell consists of an elaborate network of interconnected pathways that enable the synthesis and breakdown of molecules (anabolism and catabolism). (W
Net reactions for glycolysis of glucose, oxidative decarboxylation of pyruvate, and Krebs cycle.
Metabolism (from Greek:μεταβολήmetabolē, "change") is the set of life-sustaining chemical reactions in organisms. The three main purposes of metabolism are: the conversion of food to energy to run cellular processes; the conversion of food/fuel to building blocks for proteins,lipids,nucleic acids, and some carbohydrates; and the elimination of metabolic wastes. These enzyme-catalyzed reactions allow organisms to grow and reproduce, maintain their structures, and respond to their environments. (The word metabolism can also refer to the sum of all chemical reactions that occur in living organisms, including digestion and the transport of substances into and between different cells, in which case the above described set of reactions within the cells is called intermediary metabolism or intermediate metabolism). (W)
Simplified view of the cellular metabolism (aerobic metabolism).
Effect of insulin on glucose uptake and metabolism. Insulin binds to its receptor (1), which in turn starts many protein activation cascades (2). These include: translocation of Glut-4 transporter to the plasma membrane and influx of glucose (3), glycogen synthesis (4), glycolysis (5) and fatty acid synthesis (6)..
In biochemistry, a metabolite is an intermediate or end product of metabolism. The term metabolite is usually used for small molecules. Metabolites have various functions, including fuel, structure, signaling, stimulatory and inhibitory effects on enzymes, catalytic activity of their own (usually as a cofactor to an enzyme), defense, and interactions with other organisms (e.g. pigments,odorants, and pheromones).
Some antibiotics use primary metabolites as precursors, such as actinomycin, which is created from the primary metabolite tryptophan. Some sugars are metabolites, such as fructose or glucose, which are both present in the metabolic pathways. (W)
methanogenesisMethanogenesis or biomethanation is the formation of methane by microbes known as methanogens. Organisms capable of producing methane have been identified only from the domainArchaea, a group phylogenetically distinct from both eukaryotes and bacteria, although many live in close association with anaerobic bacteria. The production of methane is an important and widespread form of microbial metabolism. In anoxic environments, it is the final step in the decomposition of biomass. Methanogenesis is responsible for significant amounts of natural gas accumulations, the remainder being thermogenic. (W)
methionine
Methionine (symbol Met or M) is an essential amino acid in humans. As the substrate for other amino acids such as cysteine and taurine, versatile compounds such as SAM-e, and the important antioxidant glutathione, methionine plays a critical role in the metabolism and health of many species, including humans. It is encoded by the codon AUG.
Methionine is also an important part of angiogenesis, the growth of new blood vessels. Supplementation may benefit those suffering from copper poisoning. Overconsumption of methionine, the methyl group donor in DNA methylation, is related to cancer growth in a number of studies. Methionine was first isolated in 1921 by John Howard Mueller. (W)
methyl group
A methyl group is an alkyl derived from methane, containing one carbon atom bonded to three hydrogen atoms — CH3. In formulas, the group is often abbreviatedMe. Such hydrocarbon groups occur in many organic compounds. It is a very stable group in most molecules. While the methyl group is usually part of a larger molecule, it can be found on its own in any of three forms: anion,cation or radical. The anion has eight valence electrons, the radical seven and the cation six. All three forms are highly reactive and rarely observed. (W)
Different ways of representing a methyl group (highlighted in blue).
methyltransferaseMethyltransferases are a large group of enzymes that all methylate their substrates but can be split into several subclasses based on their structural features. The most common class of methyltransferases is class I, all of which contain a Rossmann fold for binding S-Adenosyl methionine (SAM). Class II methyltransferases contain a SET domain, which are exemplified by SET domain histone methyltransferases, and class III methyltransferases, which are membrane associated. Methyltransferases can also be grouped as different types utilizing different substrates in methyl transfer reactions. These types include protein methyltransferases, DNA/RNA methyltransferases, natural product methyltransferases, and non-SAM dependent methyltransferases. SAM is the classical methyl donor for methyltrasferases, however, examples of other methyl donors are seen in nature. The general mechanism for methyl transfer is a SN2-like nucleophilic attack where the methionine sulfur serves as the nucleophile that transfers the methyl group to the enzyme substrate. SAM is converted to S-Adenosyl homocysteine (SAH) during this process. The breaking of the SAM-methyl bond and the formation of the substrate-methyl bond happen nearly simultaneously. These enzymatic reactions are found in many pathways and are implicated in genetic diseases, cancer, and metabolic diseases. Another type of methyl transfer is the radical S-Adenosyl methionine (SAM) which is the methylation of unactivated carbon atoms in primary metabolites, proteins, lipids, and RNA. (W)
SET7/9, a representative histone methyltransferase with SAM (red) and peptide undergoing methylation (orange. Rendered from PDB file 4J83.).
The SN2-like methyl transfer reaction. Only the SAM cofactor and cytosine base are shown for simplicity.
microRNA
A microRNA (abbreviated miRNA) is a small non-coding RNA molecule (containing about 22 nucleotides) found in plants, animals and some viruses, that functions in RNA silencing and post-transcriptional regulation of gene expression. miRNAs function via base-pairing with complementary sequences within mRNA molecules. As a result, these mRNA molecules are silenced, by one or more of the following processes: (1) Cleavage of the mRNA strand into two pieces, (2) Destabilization of the mRNA through shortening of its poly(A) tail, and (3) Less efficient translation of the mRNA into proteins by ribosomes.
miRNAs resemble the small interfering RNAs (siRNAs) of the RNA interference (RNAi) pathway, except miRNAs derive from regions of RNA transcripts that fold back on themselves to form short hairpins, whereas siRNAs derive from longer regions of double-stranded RNA. The human genome may encode over 1900 miRNAs, although more recent analysis indicates that the number is closer to 600.
miRNAs are abundant in many mammalian cell types and appear to target about 60% of the genes of humans and other mammals. Many miRNAs are evolutionarily conserved, which implies that they have important biological functions. For example, 90 families of miRNAs have been conserved since at least the common ancestor of mammals and fish, and most of these conserved miRNAs have important functions, as shown by studies in which genes for one or more members of a family have been knocked out in mice.(W)
Diagram of microRNA (miRNA) action with mRNA. (Diagram of microRNA. Based on [1], [2], [3], the wikipedia article, and various other sources. The editable text is in this file, off beyond the page boundaries.)
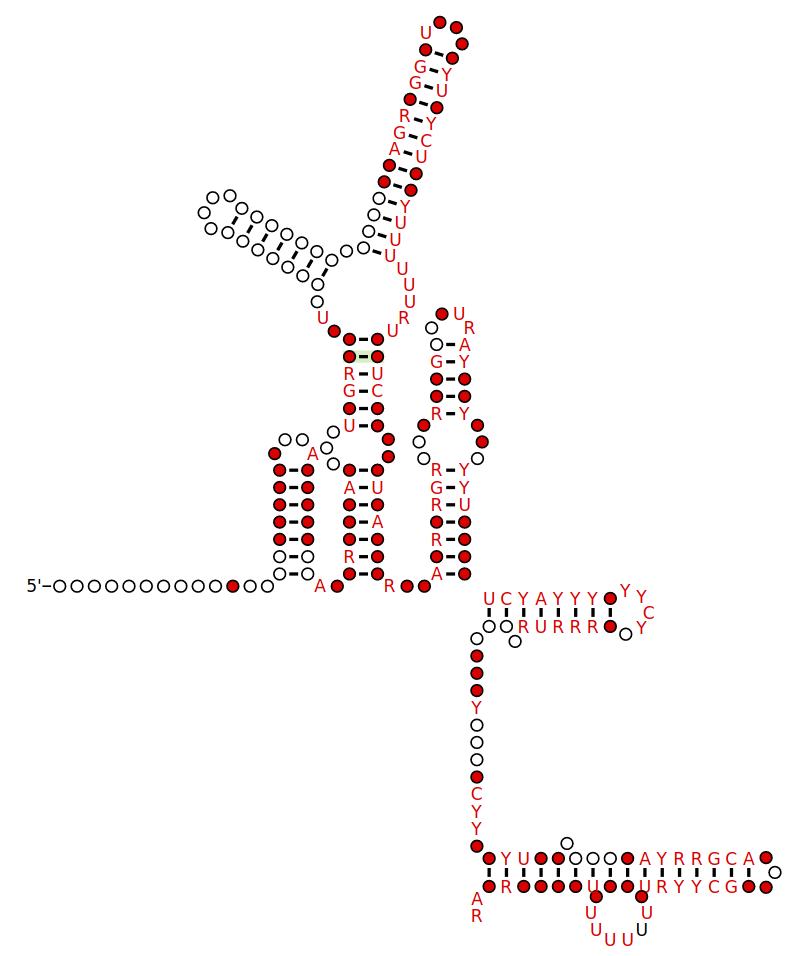
Examples of miRNA stem-loops, with the mature miRNAs shown in red.
Examples of miRNA stem-loops, with the mature miRNAs shown in red. Shown are predicted stem-loop secondary structures within the pri-RNA molecules that give rise to the lin-4 miRNA of C. elegans and the miR-1 miRNA of humans. This figure was drawn based on studies that cloned and sequenced mature miRNAs and predicted the corresponding stem-loops. (W)
Overview of microRNA processing in animals, from transcription to the formation of the effector complex. There are two pathways, one for microRNAs from independent genes and one for intronic microRNAs. Enzymes in the picture:Drosha,Pasha (pri-miRNA → pre-miRNA) Spliceosome (pre-mRNA → intron lariat) Debranching enzyme (intron lariat → RNA that can fold into pre-miRNA) RAN-GTP,Exportin-5 (export from nucleus) Dicer (pre-miRNA → miRNA) Abbrevations: pri-miRNA = primary microRNA transcript pre-mRNA = precursor messenger RNA pre-miRNA = precursor microRNA miRNA = microRNA miRNA* = antisense microRNA miRNP = microRNA ribonucleoprotein.
Overview of the miRNAs biogenesis. In the canonical pathway in the nucleus, pri-miRNAs are cleaved into pre-miRNAs by Drosha. Pre-miRNAs are exported to the cytoplasm by exportin 5. In the cytoplasm, pre-miRNAs are cleaved into small dsRNAs by Dicer. Then, RISC mediates the recognition of the mRNA to be targeted. In the non-canonical pathway (Mirtron), Drosha cleavage is substituted with splicing. pri-miRNAs (pre-mRNAs) are processed to pre-miRNAs by the spliceosome machinery and debranching enzyme to generate double-stranded loop structures like the regular miRNAs. Subsequently, the RNA product of splicing adopts a pre-miRNA like form, and transferred to the cytoplasm by exportin 5 to continue with the canonical pathway. For more details please refer to the text. (W)
Interaction of microRNA with protein translation process. Several translation repression mechanisms are shown: M1) on the initiation process, preventing assembling of the initiation complex or recruiting the 40S ribosomal subunit; M2) on the ribosome assembly; M3) on the translation process; M7, M8) on the degradation of mRNA.40S and 60S are light and heavy components of the ribosome, 80S is the assembled ribosome bound to mRNA, eIF4F is a translation initiation factor, PABC1 is the Poly-A binding protein, and "cap" is the mRNA cap structure needed for mRNA circularization (which can be the normal m7G-cap or modified A-cap). The initiation of mRNA can proceed in a cap-independent manner, through recruiting 40S to IRES (Internal Ribosome Entry Site) located in 5'UTR region. The actual work of RNA silencing is performed by RISC in which the main catalytic subunit is one of the Argonaute proteins (AGO), and miRNA serves as a template for recognizing specific mRNA sequences. (W)
microRNA sequencingMicroRNA sequencing (miRNA-seq), a type of RNA-Seq, is the use of next-generation sequencing or massively parallel high-throughput DNA sequencing to sequence microRNAs, also called miRNAs. miRNA-seq differs from other forms of RNA-seq in that input material is often enriched for small RNAs. miRNA-seq allows researchers to examine tissue-specific expression patterns, disease associations, and isoforms of miRNAs, and to discover previously uncharacterized miRNAs. Evidence that dysregulated miRNAs play a role in diseases such as cancer has positioned miRNA-seq to potentially become an important tool in the future for diagnostics and prognostics as costs continue to decrease. Like other miRNA profiling technologies, miRNA-Seq has both advantages (sequence-independence, coverage) and disadvantages (high cost, infrastructure requirements, run length, and potential artifacts) (W)
microsatellite {DNA}
A microsatellite is a tract of repetitive DNA in which certain DNA motifs (ranging in length from one to six or more base pairs) are repeated, typically 5–50 times. Microsatellites occur at thousands of locations within an organism's genome. They have a higher mutation rate than other areas of DNA leading to high genetic diversity. Microsatellites are often referred to as short tandem repeats (STRs) by forensic geneticists and in genetic genealogy, or as simple sequence repeats (SSRs) by plant geneticists.
Microsatellites and their longer cousins, the minisatellites, together are classified as VNTR (variable number of tandem repeats) DNA. The name "satellite" DNA refers to the early observation that centrifugation of genomic DNA in a test tube separates a prominent layer of bulk DNA from accompanying "satellite" layers of repetitive DNA.
They are widely used for DNA profiling in cancer diagnosis, in kinship analysis (especially paternity testing) and in forensic identification. They are also used in genetic linkage analysis to locate a gene or a mutation responsible for a given trait or disease. Microsatellites are also used in population genetics to measure levels of relatedness between subspecies, groups and individuals. (W)
DNA strand slippage during replication of an STR locus. Boxes symbolize repetitive DNA units. Arrows indicate the direction in which a new DNA strand (white boxes) is being replicated from the template strand (black boxes). Three situations during DNA replication are depicted. (a) Replication of the STR locus has proceeded without a mutation. (b) Replication of the STR locus has led to a gain of one unit owing to a loop in the new strand; the aberrant loop is stabilized by flanking units complementary to the opposite strand. (c) Replication of the STR locus has led to a loss of one unit owing to a loop in the template strand. (Forster et al. 2015).
A number of DNA samples from specimens of Littorina plena amplified using polymerase chain reaction with primers targeting a variable simple sequence repeat (SSR, a.k.a. microsatellite) locus. Samples were run on a 5% polyacrylamide gel and visualized using silver staining.
Minicircle preparation from a parental plasmid. The parental plasmid contains two recombinase target sites (black half arrows). Recombination between these sites generates the desired minicircle (bottom right) together with the miniplasmid (bottom left). The hook on the red minicircle-insert stands for a scaffold-matrix attachment region ( S/MAR-Element), which allows for autonomous replication in the recipient cell.
minor spliceosome
The minor spliceosome is a ribonucleoprotein complex that catalyses the removal (splicing) of an atypical class of spliceosomal introns (U12-type) from eukaryotic messenger RNAs in plants, insects, vertebrates and some fungi (Rhizopus oryzae). This process is called noncanonical splicing, as opposed to U2-dependent canonical splicing. U12-type introns represent less than 1% of all introns in human cells. However they are found in genes performing essential cellular functions. (W)
llustration of exons and introns in pre-mRNA. The mature mRNA is formed by splicing.
Pre-mRNA is the first form of RNA created through transcription in protein synthesis. The pre-mRNA lacks structures that the messenger RNA (mRNA) requires. First all introns have to be removed from the transcribed RNA through a process known as splicing. Before the RNA is ready for export, a Poly(A)tail is added to the 3’ end of the RNA and a 5’ cap is added to the 5’ end.
A comparison between major and minor splicing mechanisms. (L)
Mitochondrial DNA (mtDNA or mDNA) is the DNA located in mitochondria, cellular organelles within eukaryotic cells that convert chemical energy from food into a form that cells can use, adenosine triphosphate (ATP). Mitochondrial DNA is only a small portion of the DNA in a eukaryotic cell; most of the DNA can be found in the cell nucleus and, in plants and algae, also in plastids such as chloroplasts.
Human mitochondrial DNA was the first significant part of the human genome to be sequenced. This sequencing revealed that the human mtDNA includes 16,569 base pairs and encodes 13 proteins.
Since animal mtDNA evolves faster than nuclear genetic markers, it represents a mainstay of phylogenetics and evolutionary biology. It also permits an examination of the relatedness of populations, and so has become important in anthropology and biogeography.(W)
Mitochondrial DNA is the small circular chromosome found inside mitochondria. These organelles found in cells have often been called the powerhouse of the cell. The mitochondria, and thus mitochondrial DNA, are passed almost exclusively from mother to offspring through the egg cell.
Map of the human mitochondrial DNA genome (16569 bp, NCBI sequence accession NC_012920 — Anderson et al. 1981). The H (heavy, outer circle) and L (light, inner circle) strands are given with their corresponding genes. There are 22 transfer RNA (TRN) genes for the following amino acids: F, V, L1 (codon UUA/G), I, Q, M, W, A, N, C, Y, S1 (UCN), D, K, G, R, H, S2 (AGC/U), L2 (CUN), E, T and P (white boxes). There are 2 ribosomal RNA (RRN) genes: S (small subunit, or 12S) and L (large subunit, or 16S) (blue boxes). There are 13 protein-coding genes: 7 for NADH dehydrogenase subunits (ND, yellow boxes), 3 for cytochrome c oxidase subunits (COX, orange boxes), 2 for ATPase subunits (ATP, red boxes), and one for cytochrome b (CYTB, coral box). Two gene overlaps are indicated (ATP8-ATP6, and ND4L-ND4, black boxes). The control region (CR) is the longest non-coding sequence (grey box). Its three hyper-variable regions are indicated (HV, green boxes). .
The involvement of mitochondrial DNA in several human diseases.
Animal species mtDNA base composition was retrieved from the MitoAge database and compared to their maximum life span from AnAge database.
mobile genetic elementsMobile genetic elements (MGEs) sometimes called selfish genetic elements are a type of genetic material that can move around within a genome, or that can be transferred from one species or replicon to another. MGEs are found in all organisms. In humans, approximately 50% of the genome is thought to be MGEs. MGEs play a distinct role in evolution. Gene duplication events can also happen through the mechanism of MGEs. MGEs can also cause mutations in protein coding regions, which alters the protein functions. They can also rearrange genes in the host genome. One of the examples of MGEs in evolutionary context is that virulence factors and antibiotic resistance genes of MGEs can be transported to share them with neighboring bacteria. Newly acquired genes through this mechanism can increase fitness by gaining new or additional functions. On the other hand, MGEs can also decrease fitness by introducing disease-causing alleles or mutations. (W)
The current definition was adopted in November 2018 as one of the seven SI base units, revising the previous definition that specified it as the number of atoms in 12 grams of carbon-12 (12C), an isotope of carbon.
The number 6.02214076×1023 (the Avogadro number)was chosen so that the mass of one mole of a chemical compound in grams is numerically equal, for most practical purposes, to the average mass of one molecule of the compound in daltons. Thus, for example, one mole of water contains 6.02214076×1023 molecules, whose total mass is about 18.015 grams – and the mean mass of one molecule of water is about 18.015 daltons.
The mole is widely used in chemistry as a convenient way to express amounts of reactants and products of chemical reactions. For example, the chemical equation 2H2 + O2 → 2H2O can be interpreted to mean that 2 mol dihydrogen (H2) and 1 mol dioxygen (O2) react to form 2 mol water (H2O). The mole may also be used to represent the number of atoms, ions, electrons, or other entities.
The concentration of a solution is commonly expressed by its molarity, defined as the amount of dissolved substance per unit volume of solution, for which the unit typically used is moles per litre (mol/l), commonly abbreviated M.
The term gram-molecule (g mol) was formerly used for "mole of molecules", and gram-atom (g atom) for "mole of atoms". For example, 1 mole of MgBr2 is 1 gram-molecule of MgBr2 but 3 gram-atoms of MgBr2. (W)
molecular cloning
Molecular cloning is a set of experimental methods in molecular biology that are used to assemble recombinant DNA molecules and to direct their replication within host organisms. The use of the word cloning refers to the fact that the method involves the replication of one molecule to produce a population of cells with identical DNA molecules. Molecular cloning generally uses DNA sequences from two different organisms: the species that is the source of the DNA to be cloned, and the species that will serve as the living host for replication of the recombinant DNA. Molecular cloning methods are central to many contemporary areas of modern biology and medicine.
In a conventional molecular cloning experiment, the DNA to be cloned is obtained from an organism of interest, then treated with enzymes in the test tube to generate smaller DNA fragments. Subsequently, these fragments are then combined with vector DNA to generate recombinant DNA molecules. The recombinant DNA is then introduced into a host organism (typically an easy-to-grow, benign, laboratory strain of E. coli bacteria). This will generate a population of organisms in which recombinant DNA molecules are replicated along with the host DNA. Because they contain foreign DNA fragments, these are transgenic or genetically modified microorganisms (GMO). This process takes advantage of the fact that a single bacterial cell can be induced to take up and replicate a single recombinant DNA molecule. This single cell can then be expanded exponentially to generate a large amount of bacteria, each of which contain copies of the original recombinant molecule. Thus, both the resulting bacterial population, and the recombinant DNA molecule, are commonly referred to as "clones". Strictly speaking, recombinant DNA refers to DNA molecules, while molecular cloning refers to the experimental methods used to assemble them. The idea arose that different DNA sequences could be inserted into a plasmid and that these foreign sequences would be carried into bacteria and digested as part of the plasmid. That is, these plasmids could serve as cloning vectors to carry genes. (W)
Molecular geometry is the three-dimensional arrangement of the atoms that constitute a molecule. It includes the general shape of the molecule as well as bond lengths, bond angles, torsional angles and any other geometrical parameters that determine the position of each atom.
Geometry of the water molecule with values for O-H bond length and for H-O-H bond angle between two bonds.
molecular self-assembly
Molecular self-assembly is the process by which molecules adopt a defined arrangement without guidance or management from an outside source. There are two types of self-assembly. These are intramolecular self-assembly and intermolecular self-assembly. Commonly, the term molecular self-assembly refers to intermolecular self-assembly, while the intramolecular analog is more commonly called folding.(W)
monomerA monomer (mono-, "one" + -mer, "part") is a molecule that can be reacted together with other monomer molecules to form a larger polymer chain or three-dimensional network in a process called polymerization. (W)
This nylon is formed by condensation polymerization of two monomers, yielding water.
Examples of monosaccharides include glucose (dextrose), fructose (levulose), and galactose. Monosaccharides are the building blocks of disaccharides (such as sucrose and lactose) and polysaccharides (such as cellulose and starch). Each carbon atom that supports a hydroxyl group is chiral, except those at the end of the chain. This gives rise to a number of isomeric forms, all with the same chemical formula. For instance, galactose and glucose are both aldohexoses, but have different physical structures and chemical properties.
The monosaccharide glucose plays a pivotal role in metabolism, where the chemical energy is extracted through glycolysis and the citric acid cycle to provide energy to living organisms. Some other monosaccharides can be converted in the living organism to glucose. (W)
d- and l-glucose.
mRNA display
mRNA display is a display technique used for in vitroprotein, and/or peptide evolution to create molecules that can bind to a desired target. The process results in translated peptides or proteins that are associated with their mRNA progenitor via a puromycin linkage. The complex then binds to an immobilized target in a selection step (affinity chromatography). The mRNA-protein fusions that bind well are then reverse transcribed to cDNA and their sequence amplified via a polymerase chain reaction. The result is a nucleotide sequence that encodes a peptide with high affinity for the molecule of interest.
Puromycin is an analogue of the 3’ end of a tyrosyl-tRNA with a part of its structure mimics a molecule of adenosine, and the other part mimics a molecule of tyrosine. Compared to the cleavable ester bond in a tyrosyl-tRNA, puromycin has a non-hydrolysable amide bond. As a result, puromycin interferes with translation, and causes premature release of translation products.
All mRNA templates used for mRNA display technology have puromycin at their 3’ end. As translation proceeds, ribosome moves along the mRNA template, and once it reaches the 3’ end of the template, the fused puromycin will enter ribosome’s A site and be incorporated into the nascent peptide. The mRNA-polypeptide fusion is then released from the ribosome (Figure 1). (W)
Figure 1. mRNA-Polypeptide Fusion Formation. a. Ribosome moves along the mRNA template and nascent peptide is being made. When the ribosome reaches the 3’ end of the template, the fused puromycin will enter the A site of the ribosome. b. The mRNA-polypeptide fusion is released.
Figure 2. Splint Aid Single Stranded mRNA/DNA T4 DNA Ligase Ligation.
Figure 3. Selection Cycle.
mRNA surveillancemRNA surveillance mechanisms are pathways utilized by organisms to ensure fidelity and quality of messenger RNA (mRNA) molecules. There are a number of surveillance mechanisms present within cells. These mechanisms function at various steps of the mRNA biogenesis pathway to detect and degrade transcripts that have not properly been processed.(W)
UPF1 is a conserved helicase which is phosphorylated in the process of NMD. This phosphorylation is catalyzed by SMG1 kinase. This process requires UPF2 and UPF3. Dephosphorylation of UPF1 is catalyzed by SMG5, SMG6 and SMG7 proteins.
Nonsense mediated decay in mammals is mediated by the exon-exon junction. This junction is marked by a group of proteins which constitute the exon junction complex (EJC). The EJC recruits UPF1/SMG by transcription factors eRF1/eRF3. Interactions of these proteins lead to the assembly of the surveillance complex. This complex is ultimately responsible for the degradation of the nonsense mRNA.
Nonsense mediated mRNA decay in invertebrates is postulated to be mediated by the presence of a faux 3' untranslated region (UTR). These faux 3'UTRs are distinguished from natural 3'UTRs which follow natural stop codons. This is due to the lack of binding proteins which are normally present in natural 3'UTR. These binding proteins include the poly(A)-binding protein (PABP).
Nonstop mediated mRNA. Translation of a mRNA without a stop codon results in the translation of the ribosome into the 3' poly-A tail region. this results in a stalled ribosome. The ribosome is rescued by two distinct pathways. The mechanisms are dependent of the absence or presence of the Ski7 protein.
No-Go Mediated mRNA decay.
A proposed evolutionary mechanism for development of mRNA surveillance component proteins.
Muller’s morphs
Hermann J. Muller (1890–1967), who was a 1946 Nobel Prize winner, coined the terms amorph, hypomorph, hypermorph, antimorph and neomorph to classify mutations based on their behaviour in various genetic situations, as well as gene interaction between themselves. These classifications are still widely used in Drosophila genetics to describe mutations. For a more general description of mutations, see mutation, and for a discussion of allele interactions, see dominance relationship.
Key: In the following sections, alleles are referred to as +=wildtype, m=mutant, Df=gene deletion, Dp=gene duplication. Phenotypes are compared with '>', meaning 'phenotype is more severe than'(W)
Myoglobin (symbol Mb or MB) is an iron- and oxygen-binding protein found in the skeletalmuscle tissue of vertebrates in general and in almost all mammals. Myoglobin is distantly related to hemoglobin, oxygen-binding protein in red blood cells. In humans, myoglobin is only found in the bloodstream after muscle injury.
High concentrations of myoglobin in muscle cells allow organisms to hold their breath for a longer period of time. Diving mammals such as whales and seals have muscles with particularly high abundance of myoglobin. Myoglobin is found in Type I muscle, Type II A, and Type II B, but most texts consider myoglobin not to be found in smooth muscle.
Myoglobin was the first protein to have its three-dimensional structure revealed by X-ray crystallography. This achievement was reported in 1958 by John Kendrew and associates. For this discovery, Kendrew shared the 1962 Nobel Prize in chemistry with Max Perutz. Despite being one of the most studied proteins in biology, its physiological function is not yet conclusively established: mice genetically engineered to lack myoglobin can be viable and fertile, but show many cellular and physiological adaptations to overcome the loss. Through observing these changes in myoglobin-depleted mice, it is hypothesised that myoglobin function relates to increased oxygen transport to muscle, and to oxygen storage; as well, it serves as a scavenger of reactive oxygen species.
Myoglobin can take the forms oxymyoglobin (MbO2), carboxymyoglobin (MbCO), and metmyoglobin (met-Mb), analogously to hemoglobin taking the forms oxyhemoglobin (HbO2), carboxyhemoglobin (HbCO), and methemoglobin (met-Hb). (W)
This is an image of an oxygenated myoglobin molecule. The image shows the structural change when oxygen is bound to the iron atom of the heme prosthetic group. The oxygen atoms are colored in green, the iron atom is colored in red, and the heme group is colored in blue.
Receptors for myokines are found on muscle, fat, liver, pancreas, bone, heart, immune, and brain cells. The location of these receptors reflects the fact that myokines have multiple functions. Foremost, they are involved in exercise-associated metabolic changes, as well as in the metabolic changes following training adaptation. They also participate in tissue regeneration and repair, maintenance of healthy bodily functioning, immunomodulation; and cell signaling, expression and differentiation. (W)
Nicotinamide adenine dinucleotide phosphate, abbreviated NADP+ or, in older notation, TPN (triphosphopyridine nucleotide), is a cofactor used in anabolic reactions, such as the Calvin cycle and lipid and nucleic acid syntheses, which require NADPH as a reducing agent. It is used by all forms of cellular life.
NADPH is the reduced form of NADP+. NADP+ differs from NAD+ by the presence of an additional phosphate group on the 2' position of the ribose ring that carries the adeninemoiety. This extra phosphate is added by NAD+ kinase and removed by NADP+ phosphatase.
NADPH
NADPH is produced from NADP+. The major source of NADPH in animals and other non-photosynthetic organisms is the pentose phosphate pathway, by glucose-6-phosphate dehydrogenase (G6PDH) in the first step. The pentose phosphate pathway also produces pentose, another important part of NAD(P)H, from glucose. Some bacteria also use G6PDH for the Entner–Doudoroff pathway, but NADPH production remains the same. (W)
Structure of nicotinamide adenine dinucleotide phosphate, oxidized (NADP+).
NADP+
NADPH
naked extracellular DNA (eDNA)
Naked extracellular DNA (eDNA), most of it released by cell death, is nearly ubiquitous in the environment. Its concentration in soil may be as high as 2 μg/L, and its concentration in natural aquatic environments may be as high at 88 μg/L. Various possible functions have been proposed for eDNA: it may be involved in horizontal gene transfer; it may provide nutrients; and it may act as a buffer to recruit or titrate ions or antibiotics. Extracellular DNA acts as a functional extracellular matrix component in the biofilms of several bacterial species. It may act as a recognition factor to regulate the attachment and dispersal of specific cell types in the biofilm; it may contribute to biofilm formation; and it may contribute to the biofilm's physical strength and resistance to biological stress.
Cell-free fetal DNA is found in the blood of the mother, and can be sequenced to determine a great deal of information about the developing fetus.
Under the name of environmental DNA eDNA has seen increased use in the natural sciences as a survey tool for ecology, monitoring the movements and presence of species in water, air, or on land, and assessing an area's biodiversity. (W)
natural competence
In microbiology,genetics,cell biology, and molecular biology,competence is the ability of a cell to alter its genetics by taking up extracellular ("naked") DNA from its environment in the process called transformation. Competence may be differentiated between natural competence, a genetically specified ability of bacteria which is thought to occur under natural conditions as well as in the laboratory, and induced or artificial competence, which arises when cells in laboratory cultures are treated to make them transiently permeable to DNA. Competence allows for rapid adaptation and DNA repair of the cell. This article primarily deals with natural competence in bacteria, although information about artificial competence is also provided.(W)
Natural competence. 1-Bacterial cell DNA
2-Bacterial cell plasmids
3-Sex pili
4-Plasmid of foreign DNA from a dead cell
5-Bacterial cell restriction enzyme
6-Unwound foreign plasmid
7-DNA ligase
I: A plasmid of foreign DNA from a dead cell is intercepted by the sex pili of a naturally competent bacterial cell. II: The foreign plasmid is transduced through the sex pili into the bacterial cell, where it is processed by bacterial cell restriction enzymes. The restriction enzymes break the foreign plasmid into a strand of nucleotides that can be added to the bacterial DNA.
III: DNA ligase integrates the foreign nucleotides into the bacterial cell DNA.
IV: Recombination is complete and the foreign DNA has integrated into the original bacterial cell's DNA and will continue to be a part of it when the bacterial cell replicates next.
A neural pathway connects one part of the nervous system to another using bundles of axons called tracts. The optic tract that extends from the optic nerve is an example of a neural pathway because it connects the eye to the brain; additional pathways within the brain connect to the visual cortex.
A neural pathway is responsible for connecting a specific part of the nervous system to another by a bundle of axons, which are also the long fibers of neurons. The pathway helps to connect parts of the brain or nervous system that are distant, and are typically known and seen as white matter. In the vision pathway, visual information leaves the eye with the help of the optic nerve. Axons partially cross in the middle of the optic chiasm. Following this, the axons are known as the optic tract, which will bind around the midbrain in order to reach the lateral geniculate nucleus. The lateral geniculate nucleus is the area where the axons have to synapse. After this, the axons flow throughout the white matter and act as optic radiations, which finally travel back to the primary visual cortex located in the back of the brain..
Neural pathways of cerebellar cortex. Architecture of the human cerebellar cortex.
neurogenins
Neurogenins are a family of bHLHtranscription factors involved in specifying neuronal differentiation. It is one of many gene families related to the atonal gene in Drosophila. Other positive regulators of neuronal differentiation also expressed during early neural development include NeuroD and ASCL1.
Neuromodulation is the physiological process by which a given neuron uses one or more chemicals to regulate diverse populations of neurons. Neuromodulators typically bind to metabotropic, G-protein coupled receptors (GPCRs) to initiate a second messenger signaling cascade that induces a broad, long-lasting signal. This modulation can last for hundreds of milliseconds to several minutes. Some of the effects of neuromodulators include: alter intrinsic firing activity, increase or decrease voltage-dependent currents,[2] alter synaptic efficacy, increase bursting activity and reconfiguration of synaptic connectivity.
Major neuromodulators in the central nervous system include: dopamine, serotonin, acetylcholine, histamine, norepinephrine and several neuropeptides. Neuromodulators can be packaged into vesicles and released by neurons, secreted as hormones and delivered through the circulatory system. A neuromodulator can be conceptualized as a neurotransmitter that is not reabsorbed by the pre-synaptic neuron or broken down into a metabolite. Some neuromodulators end up spending a significant amount of time in the cerebrospinal fluid (CSF), influencing (or "modulating") the activity of several other neurons in the brain. (W)
neutralization (chemistry)
In chemistry, neutralization or neutralisation (see spelling differences) is a chemical reaction in which acid and a base react quantitatively with each other. In a reaction in water, neutralization results in there being no excess of hydrogen or hydroxide ions present in the solution. The pH of the neutralized solution depends on the acid strength of the reactants. (W)
Animation of a strong acid–strong base neutralization titration (using phenolphthalein). The equivalence point is marked in red.
niche (protein structural motif)
In the area of proteinstructural motifs,niches are three or four amino acid residue features in which main-chain CO groups are bridged by positively charged or δ+ groups. The δ+ groups include groups with two hydrogen bond donor atoms such as NH2 groups and water molecules. In typical proteins, 7% of amino acid residues belong to niches bound to a δ+ group, while another 7% have the conformation but no single cationic bridging group is detected. (W)
nick (DNA)
A nick is a discontinuity in a double stranded DNA molecule where there is no phosphodiester bond between adjacent nucleotides of one strand typically through damage or enzyme action. Nicks allow DNA strands to untwist during replication, and are also thought to play a role in the DNA mismatch repair mechanisms that fix errors on both the leading and lagging daughter strands. (W)
The diagram shows the effects of nicks on intersecting DNA forms. A plasmid is tightly wound into a negative supercoil (a). To release the intersecting states, the torsional energy must be released by utilizing nicks (b). After introducing a nick in the system, the negative supercoil gradually unwinds (c) until it reaches its final, circular, plasmid state (d).
Minimalistic mechanism of DNA nick sealing by DNA ligase.
nicotinamide adenine dinucleotide (NAD)
Nicotinamide adenine dinucleotide (NAD) is a cofactor central to metabolism. Found in all living cells, NAD is called a dinucleotide because it consists of two nucleotides joined through their phosphate groups. One nucleotide contains an adeninenucleobase and the other nicotinamide. NAD exists in two forms: an oxidized and reduced form, abbreviated as NAD+ and NADH respectively.
In metabolism, nicotinamide adenine dinucleotide is involved in redox reactions, carrying electrons from one reaction to another. The cofactor is, therefore, found in two forms in cells: NAD+ is an oxidizing agent – it accepts electrons from other molecules and becomes reduced. This reaction forms NADH, which can then be used as a reducing agent to donate electrons. These electron transfer reactions are the main function of NAD. However, it is also used in other cellular processes, most notably as a substrate of enzymes in adding or removing chemical groups to or from, respectively, proteins, in posttranslational modifications. Because of the importance of these functions, the enzymes involved in NAD metabolism are targets for drug discovery.(W)
Structure of nicotinamide adenine dinucleotide, oxidized (NAD+).
Ball-and-stick model of the nicotinamide adenine dinucleotide molecule, NAD+, as found in the crystal structure of the zwitterionic form, C21H27N7O14P2·4H2O. The crystal structure was reported in B. Guillot et al, J. Phys. Chem. B2003, 107, 9109-9121. Note that the zwitterionic form is different to the physiological form: the zwitterion is protonated at nitrogen N1 of the adenine group so the molecule as a whole has a charge of zero, whereas the physiological form is not protonated here and thus the molecule has an overall charge of −1. Colour code: Carbon, C: black Hydrogen, H: white Nitrogen, N: blue Oxygen, O: red Phosphorus, P: orange Model manipulated and image generated in Accelrys DS Visualizer..
natural competence
In microbiology,genetics,cell biology, and molecular biology,competence is the ability of a cell to alter its genetics by taking up extracellular ("naked") DNA from its environment in the process called transformation. Competence may be differentiated between natural competence, a genetically specified ability of bacteria which is thought to occur under natural conditions as well as in the laboratory, and induced or artificial competence, which arises when cells in laboratory cultures are treated to make them transiently permeable to DNA. Competence allows for rapid adaptation and DNA repair of the cell. This article primarily deals with natural competence in bacteria, although information about artificial competence is also provided.(W)
Natural competence. 1-Bacterial cell DNA
2-Bacterial cell plasmids
3-Sex pili
4-Plasmid of foreign DNA from a dead cell
5-Bacterial cell restriction enzyme
6-Unwound foreign plasmid
7-DNA ligase
I: A plasmid of foreign DNA from a dead cell is intercepted by the sex pili of a naturally competent bacterial cell. II: The foreign plasmid is transduced through the sex pili into the bacterial cell, where it is processed by bacterial cell restriction enzymes. The restriction enzymes break the foreign plasmid into a strand of nucleotides that can be added to the bacterial DNA.
III: DNA ligase integrates the foreign nucleotides into the bacterial cell DNA.
IV: Recombination is complete and the foreign DNA has integrated into the original bacterial cell's DNA and will continue to be a part of it when the bacterial cell replicates next.
Stylized depiction of an activated NMDAR. Glutamate is in the glutamate-binding site and glycine is in the glycine-binding site. The allosteric site, which modulates receptor function when bound to a ligand, is not occupied. NMDARs require the binding of two molecules of glutamate or aspartate and two of glycine.
Figure 1: NR1/NR2 NMDA receptor.
Cell membrane bound N1/N2/N1/N2 NMDA receptor. Typical NMDA-receptors have 4 subunits - only 2 are shown. Normal flow of Ca2+, Na+ and K+ ions is shown alongside with the regular membrane potential (+ and - signs) and some of the ligand binding sites. ATD: amino terminal domain. LBD: ligand-binding domain. LBD can bind glutamine (Glu, agonist) and D-serine (D-Ser) or glycine (Gly) coagonists. TMD: transmembrane domains. TMDs are composed of M1-4 segments. CTD: intracellular carboxyl terminal domain. Structure and information adapted from: Hashimoto, Kenjii (ed.). (2017). The NMDA receptors. Mori, Hisashi. p. 7-8. ISBN 9783319497952. doi:10.1007/978-3-319-49795-2..
Figure 2: Transmembrane region of NR1 (left) and NR2B (right) subunits of NMDA receptor.
NR2 subunit in vertebrates (left) and invertebrates (right). Ryan et al., 2008.
Model of NR2 Subunit. 1.A: Schematic of vertebrate NR2A or NR2B subunits. Note the long intracellular C-terminal domain and relative positioning of particular interacting proteins. PSD-95 is a scaffolding protein, while CaMKII and P13K are kinases that phosphorylate the NMDA receptor. 1.B: Schematic of invertebrate NR2. Note the significantly shorter intracellular C-terminus. Ryan et al. BMC Neuroscience 2008 9:6 doi:10.1186/1471-2202-9-6.
The timecourse of GluN2B-GluN2A switch in human cerebellum. Bar-Shira et al., 2015.
non-cellular life
Non-cellular life, or acellular life is life that exists without a cellular structure for at least part of its life cycle. Historically, most (descriptive) definitions of life postulated that a living organism must be composed of one or more cells, but this is no longer considered necessary, and modern criteria allow for forms of life based on other structural arrangements.
The primary candidates for non-cellular life are viruses. Some biologists consider viruses to be living organisms, but others do not. Their primary objection is that no known viruses are capable of autonomous reproduction: they must rely on cells to copy them.
Engineers sometimes use the term "artificial life" to refer to software and robots inspired by biological processes, but these do not satisfy any biological definition of life. (W)
The number of non-coding RNAs within the human genome is unknown; however, recent transcriptomic and bioinformatic studies suggest that there are thousands of them. Many of the newly identified ncRNAs have not been validated for their function. It is also likely that many ncRNAs are non functional (sometimes referred to as junk RNA), and are the product of spurious transcription.
Non-coding RNAs are thought to contribute to diseases including cancer and Alzheimer's.(W)
The cloverleaf structure of Yeast tRNAPhe (inset) and the 3D structure determined by X-ray analysis.
X-ray structure of the tRNAPhe from yeast. Data was obtained by PDB:1ehz and rendered with PyMOL. violet: acceptor stem wine red: D-loop blue: anticodon loop orange: variable loop green: TPsiC-loop yellow: CCA-3' of the acceptor stem grey: anticodon
non-covalent interactions, types of
Electrostatic interaction: In an aqueous environment, the oppositely charged groups in amino acid side chains within the active site and substrates attract each other, which is termed electrostatic interaction. For example, when a carboxylic acid (R-COOH) dissociates into RCOO- and H+ ions, COO− will attract positively charged groups such as protonated guanidine side chain of arginine.
Positively charged sodium ion and negatively charged fluoride ion attract each other to form sodium fluoride under electrostatic interaction.
Hydrogen bond: A hydrogen bond is a specific type of dipole-dipole interaction between a partially positive hydrogen atom and a partially negative electron donor that contain a pair of electrons such as oxygen,fluorine and nitrogen. The strength of hydrogen bond depends on the chemical nature and geometric arrangement of each group.
Hydrogen bond between two water molecules.
Van der Waals force: Van der Waals force is formed between oppositely charged groups due to transient uneven electron distribution in each group. If all electrons all concentrated at one pole of the group this end will be negative, while the other end will be positive. Although the individual force is weak, as the total number of interactions between the active site and substrate is massive the sum of them will be significant.
Van der Waals force between two acetone molecules. The lower acetone molecule contains a partially negative oxygen atom that attracts partially positive carbon atom in the upper acetone.
Dipole-dipole interactions between two acetone molecules, with the partially negative oxygen atom interacting with the partially positive carbon atom in the carbonyl.
Hydrophobic interaction: Non-polar hydrophobic groups tend to aggregate together in the aqueous environment and try to leave from polar solvent. These hydrophobic groups usually have long carbon chain and do not react with water molecules. When dissolving in water a protein molecule will curl up into a ball-like shape, leaving hydrophilic groups in outside while hydrophobic groups are deeply buried within the centre. (W)
Hydrophobic and hydrophilic groups tend to assemble with the same kind of molecules.
non-homologous end joiningNon-homologous end joining (NHEJ) is a pathway that repairs double-strand breaks in DNA. NHEJ is referred to as "non-homologous" because the break ends are directly ligated without the need for a homologous template, in contrast to homology directed repair, which requires a homologous sequence to guide repair. The term "non-homologous end joining" was coined in 1996 by Moore and Haber. (W)
Non-homologous end joining (NHEJ) and homologous recombination (HR) in mammals during DNA double-strand break.
Mammalian double-strand break (DSB) repair. Non-homologous end joining (NHEJ) and homologous recombination (HR) in mammals during DNA double-strand break. Figure from article Hannes Lans, Jurgen A. Marteijn & Wim Vermeulen (2012). "ATP-dependent chromatin remodeling in the DNA-damage response". Epigenetics & chromatin5: 4. DOI:10.1186/1756-8935-5-4.PMID22289628.License info.
non-stop decayNon-stop decay (NSD) is a cellular mechanism of mRNA surveillance to detect mRNA molecules lacking a stop codon and prevent these mRNAs from translation. The non-stop decay pathway releases ribosomes that have reached the far 3' end of an mRNA and guides the mRNA to the exosome complex, or to RNase R in bacteria for selective degradation. In contrast to Nonsense-mediated decay (NMD), polypeptides do not release from the ribosome, and thus, NSD seems to involve mRNA decay factors distinct from NMD. (W)
Diagram of non-stop decay (NDS) process.
nonsense-mediated decayNonsense-mediated mRNA decay (NMD) is a surveillance pathway that exists in all eukaryotes. Its main function is to reduce errors in gene expression by eliminating mRNA transcripts that contain premature stop codons. Translation of these aberrant mRNAs could, in some cases, lead to deleterious gain-of-function or dominant-negative activity of the resulting proteins. (W)
Canonical NMD pathway (in human).
nonsense mutation
In genetics, a point-nonsense mutation is a point mutation in a sequence of DNA that results in a premature stop codon, or a point-nonsense codon in the transcribedmRNA, and in a truncated, incomplete, and usually nonfunctional protein product. The functional effect of a point-nonsense mutation depends on the location of the stop codon within the coding DNA. For example, the effect of a point-nonsense mutation depends on the proximity of the point-nonsense mutation to the original stop codon, and the degree to which functional subdomains of the protein are affected.
A point-nonsense mutation differs from a missense mutation, which is a point mutation where a single nucleotide is changed to cause substitution of a different amino acid. A point-nonsense mutation also differs from a nonstop mutation in that it does not erase a stop codon but, instead, create one.
Selection of notable mutations, ordered in a standard table of the genetic code of amino acids. point-nonsense mutations are marked by red arrows.
Selection of notable mutations, ordered in a standard table of the genetic code of amino acids. As can be seen, clinically important missense mutations generally change the properties of the coded amino acid residue between being basic, acidic, polar or nonpolar, while nonsense mutations result in a stop codon. In the case of cancers, mutations cause aggravation of the conditions by impairing tumor suppressors or activating oncogenes. Every U (uracil) in the mRNA corresponds to a T (thymine) in the original DNA. Therefore, mutations are often noted using T rather than U. Mutations mentioned Sickle-cell disease: GAG to GTG in the hemoglobin gene Huntington's disease: CAG insertions, which adds a string of glutamines to Huntingtin Friedreich's ataxia: In most cases, the mutant frataxin gene contains expanded GAA triplet repeats in the first intron; Dentatorubral-pallidoluysian atrophy (DRPLA), caused by an expansion of a CAG repeat encoding a polyglutamine tract in the atrophin-1 protein. Kennedy's disease, caused by expansion of a CAG repeat in the first exon of the androgen receptor gene. Fragile X Syndrome: CGG insertions on the X chromosome. Practically, however, these are not related to arginine, because the mutations are located in the 5' untranslated region. CTG in myotonic dystrophy. Spinocerebellar ataxia. Many types are caused by CAG repeats, see Wikipedia:Spinocerebellar ataxia#Treatment and prognosis for details. Spinocerebellar ataxia: CTG β-thalassemia (β-globin gene) C to U resulting in stop signal UAG also UGG to UGA D1822V by GAC->GTC is the most common missense APC variant described to date in colorectal cancer. A49T (GCC to ACC), V63M and V89L are the most common missense substitutions in prostatic or type II steroid 5alpha-reductase gene in prostate cancer tissue. p.R50X is the most common nonsense mutation in myophosphorylase in McArdle's disease, the most common Glycogen storage diseaseReferences ↑ abcKimball's Biology Pages --> Mutations Retrieved on July 18, 2009. Author: John W. Kimball ↑The Friedreich ataxia GAA triplet repeat: premutation and normal alleles L Montermini, E Andermann, M Labuda, A Richter, M Pandolfo, F Cavalcanti, L Pianese, L Iodice, G Farina, A Monticelli, M Turano, A Filla, G De Michele and S Cocozza. Human Molecular Genetics, Vol 6, 1261-1266 ↑Molecular pathology of dentatorubral-pallidoluysian atrophy. I Kanazawa. Philos Trans R Soc Lond B Biol Sci. 1999 June 29; 354(1386): 1069–1074. PMCID: PMC1692599 ↑ La Spada AR, Wilson EM, Lubahn DB, Harding AE, Fischbeck KH (July 1991). "Androgen receptor gene mutations in X-linked spinal and bulbar muscular atrophy". Nature352 (6330): 77–9. DOI:10.1038/352077a0.PMID2062380.↑Page 88 in: Title: COLOR ATLAS OF GENETICS. Author: CEBERHARD PASSARGE, M.D. ISBN: C1588903362, 9781588903365 Length: 486 pages ↑Molecular genetics of spinocerebellar ataxia type 8 (SCA8) A.K. Mosemillera,c, J.C. Daltona,c, J.W. Dayb,c, L.P.W. Ranuma,c. Nucleotide and Protein Expansions and Human Disease. ↑Mutations By Professor A. Cuschieri.Department of Anatomy. University of Malta. Retrieved on July 18, 2009 ↑Page 258 in: Colleen Smith; Lieberman, Michael; Marks, Dawn B.; Allan D. Marks (2009) Marks' Basic medical biochemistry: a clinical approach, Philadelphia: Wolters Kluwer Health/Lippincott Williams & Wilkins ISBN:0-7817-7022-X.↑ Guerreiro CS, Cravo ML, Brito M, Vidal PM, Fidalgo PO, Leitão CN (June 2007). "The D1822V APC polymorphism interacts with fat, calcium, and fiber intakes in modulating the risk of colorectal cancer in Portuguese persons". Am. J. Clin. Nutr.85 (6): 1592–7. PMID17556698.↑ Cleary SP, Kim H, Croitoru ME, et al. (October 2008). "Missense polymorphisms in the adenomatous polyposis coli gene and colorectal cancer risk". Dis. Colon Rectum51 (10): 1467–73; discussion 1473–4. DOI:10.1007/s10350-008-9356-7.PMID18612690. ↑ ab Hayes VM, Severi G, Padilla EJ, et al. (February 2007). "5alpha-Reductase type 2 gene variant associations with prostate cancer risk, circulating hormone levels and androgenetic alopecia". Int. J. Cancer120 (4): 776–80. DOI:10.1002/ijc.22408.PMID17136762.↑ Makridakis N, Akalu A, Reichardt JK (September 2004). "Identification and characterization of somatic steroid 5alpha-reductase (SRD5A2) mutations in human prostate cancer tissue". Oncogene23 (44): 7399–405. DOI:10.1038/sj.onc.1207922.PMID15326487.↑ García-Consuegra I, Rubio JC, Nogales-Gadea G, et al. (March 2009). "Novel mutations in patients with McArdle disease by analysis of skeletal muscle mRNA". J. Med. Genet.46 (3): 198–202. DOI:10.1136/jmg.2008.059469.PMID19251976. .
With northern blotting it is possible to observe cellular control over structure and function by determining the particular gene expression rates during differentiation and morphogenesis, as well as in abnormal or diseased conditions. Northern blotting involves the use of electrophoresisto separate RNA samples by size, and detection with a hybridization probe complementary to part of or the entire target sequence. The term 'northern blot' actually refers specifically to the capillary transfer of RNA from the electrophoresis gel to the blotting membrane. However, the entire process is commonly referred to as northern blotting. The northern blot technique was developed in 1977 by James Alwine, David Kemp, and George Stark at Stanford University, with contributions from Gerhard Heinrich. Northern blotting takes its name from its similarity to the first blotting technique, the Southern blot, named for biologist Edwin Southern. The major difference is that RNA, rather than DNA, is analyzed in the northern blot. (W)
Flow diagram outlining the general procedure for RNA detection by northern blotting.
Capillary blotting system setup for the transfer of RNA from an electrophoresis gel to a blotting membrane.
RNA run on a formaldehyde agarose gel to highlight the 28S (top band) and 18S (lower band) ribosomal subunits.
nuclear protein
A nuclear protein is a protein found in the cell nucleus. Proteins are transported inside the nucleus with the help of the nuclear pore complex, which acts a barrier between cytoplasm and nuclear membrane. The import and export of proteins through the nuclear pore complex plays a fundamental role in gene regulation and other biological functions. (W)
Crystallographic structure of a heterodimer of the nuclear receptors PPAR-γ (green) and RXR-α (cyan) bound to double stranded DNA (magenta) and two molecules of the NCOA2 coactivator (red). The PPAR-γ antagonist GW9662 and RXR-α agonist retinoic acid are depicted as space-filling models (carbon = white, oxygen = red, nitrogen = blue, chlorine = green).
Structural Organization of Nuclear Receptors Top – Schematic 1D amino acid sequence of a nuclear receptor. Bottom – 3D structures of the DBD (bound to DNA) and LBD (bound to hormone) regions of the nuclear receptor. The structures shown are of the estrogen receptor. Experimental structures of N-terminal domain (A/B), hinge region (D), and C-terminal domain (F) have not been determined therefore are represented by red, purple, and orange dashed lines, respectively..
Structure of the human progesterone receptor DNA-binding domain dimer (cyan and green) complexed with double strained DNA (magenta). Zinc atoms of are depicted as grey spheres.
Mechanism of class I nuclear receptor action. A class I nuclear receptor (NR), in the absence of ligand, is located in the cytosol. Hormone binding to the NR triggers dissociation of heat shock proteins (HSP), dimerization, and translocation to the nucleus, where the NR binds to a specific sequence of DNA known as a hormone response element (HRE). The nuclear receptor DNA complex in turn recruits other proteins that are responsible for transcription of downstream DNA into mRNA, which is eventually translated into protein, which results in a change in cell function..
Mechanism of class II nuclear receptor action. A class II nuclear receptor (NR), regardless of ligand-binding status, is located in the nucleus bound to DNA. For the purpose of illustration, the nuclear receptor shown here is the thyroid hormone receptor (TR) heterodimerized to the RXR. In the absence of ligand, the TR is bound to corepressor protein. Ligand binding to TR causes a dissociation of corepressor and recruitment of coactivator protein, which, in turn, recruits additional proteins such as RNA polymerase that are responsible for transcription of downstream DNA into RNA and eventually protein.
nuclear transport
Nuclear transport refers to the mechanisms by which molecules move across the nuclear membrane of a cell. The entry and exit of large molecules from the cell nucleus is tightly controlled by the nuclear pore complexes (NPCs). Although small molecules can enter the nucleus without regulation, macromolecules such as RNA and proteins require association with transport factors known as nuclear transport receptors, like karyopherins called importins to enter the nucleus and exportins to exit.(W)
There are two primary classifications based on the locus of activity. Exonucleases digest nucleic acids from the ends. Endonucleases act on regions in the middle of target molecules. They are further subcategorized as deoxyribonucleases and ribonucleases. The former acts on DNA, the latter on RNA.(W)
The DNA double helix biopolymer of nucleic acid is held together by nucleotides which base pair together. In B-DNA, the most common double helical structure found in nature, the double helix is right-handed with about 10–10.5 base pairs per turn. The double helix structure of DNA contains a major groove and minor groove. In B-DNA the major groove is wider than the minor groove. Given the difference in widths of the major groove and minor groove, many proteins which bind to B-DNA do so through the wider major groove. (W)
Simplified representation of a double stranded DNA helix with coloured bases.
A double stranded DNA fragment 22 residues long is displayed with alternating adenine residues in green, thymidine in red, cytosine in dark blue, and guanine residues in cyan. The phosphate backbone is displayed as an orange ribbon.
Base pair geometries.
A-DNA, B-DNA, and Z-DNA conformations of DNA. 12 base-pair steps composed by 13 base-pairs are show in a side view and top view. The symmetrical features of the double-helix are highlighted with the top view panel.
The helix axis of A-, B-, and Z-DNA.
Major and minor grooves of DNA. Minor groove is a binding site for the dye Hoechst 33258. Ligand in minor DNA groove.
nucleic acid hybridization
In molecular biology, hybridization (or hybridisation) is a phenomenon in which single-stranded deoxyribonucleic acid (DNA) or ribonucleic acid (RNA) molecules anneal to complementary DNA or RNA. Though a double-stranded DNA sequence is generally stable under physiological conditions, changing these conditions in the laboratory (generally by raising the surrounding temperature) will cause the molecules to separate into single strands. These strands are complementary to each other but may also be complementary to other sequences present in their surroundings. Lowering the surrounding temperature allows the single-stranded molecules to anneal or “hybridize” to each other.
Nucleic acid metabolism is the process by which nucleic acids (DNA and RNA) are synthesized and degraded. Nucleic acids are polymers of nucleotides. Nucleotide synthesis is an anabolic mechanism generally involving the chemical reaction of phosphate, pentose sugar, and a nitrogenous base. Destruction of nucleic acid is a catabolic reaction. Additionally, parts of the nucleotides or nucleobases can be salvaged to recreate new nucleotides. Both synthesis and degradation reactions require enzymes to facilitate the event. Defects or deficiencies in these enzymes can lead to a variety of diseases. (W)
Composition of nucleotides, which make up nucleic acids.
The origin of atoms that make up purine bases.
Uridine-triphosphate (UTP), at left, reacts with glutamine and other chemicals to form cytidine-triphosphate (CTP), on the right.
General outline of nucleic acid degradation for purines.
nucleic acid sequence
A nucleic acid sequence is a succession of bases signified by a series of a set of five different letters that indicate the order of nucleotides forming alleles within a DNA (using GACT) or RNA (GACU) molecule. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.
The sequence has capacity to represent information. Biological deoxyribonucleic acid represents the information which directs the functions of a living thing.
Nucleic acids also have a secondary structure and tertiary structure. Primary structure is sometimes mistakenly referred to as primary sequence. Conversely, there is no parallel concept of secondary or tertiary sequence. (W)
nucleic acid structureNucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary. (W)
Chemical structure of DNA. Linkage of the nucleobasesC, G, A and T to the deoxyribose phosphat backbone of DNA
Nucleic acid design can be used to create nucleic acid complexes with complicated secondary structures such as this four-arm junction. These four strands associate into this structure because it maximizes the number of correct base pairs, with As matched to Ts and Cs matched to Gs. Image from Mao, 2004.
An example of RNA secondary structure. This image includes several structural elements, including; single-stranded and double-stranded areas, bulges, internal loops and hairpin loops. Double-stranded RNA forms an A-type helical structure, unlike the common B-type conformation taken by double-stranded DNA molecules..
The structure of DNA, based on Image:DNA-structure-and-bases.png: A. Adenine B. Thymine C. Guanine D. Cytosine 1. Sugar, Phosphate, Backbone 2. Base pair 3. Nitrogeous base.
A-B-Z-DNA Side View.
nucleobase
Nucleobases, also known as nitrogenous bases or often simply bases, are nitrogen-containing biological compounds that form nucleosides, which in turn are components of nucleotides, with all of these monomers constituting the basic building blocks of nucleic acids. The ability of nucleobases to form base pairs and to stack one upon another leads directly to long-chain helical structures such as ribonucleic acid (RNA) and deoxyribonucleic acid (DNA).
Five nucleobases—adenine (A), cytosine (C), guanine (G), thymine (T), and uracil (U)—are called primary or canonical. They function as the fundamental units of the genetic code, with the bases A, G, C, and T being found in DNA while A, G, C, and U are found in RNA. Thymine and uracil are identical except that T includes a methyl group that U lacks.
Adenine and guanine have a fused-ring skeletal structure derived of purine, hence they are called purine bases. The purine nitrogenous bases are characterized by their single amino group (NH2), at the C6 carbon in adenine and C2 in guanine. Similarly, the simple-ring structure of cytosine, uracil, and thymine is derived of pyrimidine, so those three bases are called the pyrimidine bases. Each of the base pairs in a typical double-helix DNA comprises a purine and a pyrimidine: either an A paired with a T or a C paired with a G. These purine-pyrimidine pairs, which are called base complements, connect the two strands of the helix and are often compared to the rungs of a ladder. The pairing of purines and pyrimidines may result, in part, from dimensional constraints, as this combination enables a geometry of constant width for the DNA spiral helix. The A-T and C-G pairings function to form double or triple hydrogen bonds between the amine and carbonyl groups on the complementary bases.
Nucleobases such as adenine, guanine, xanthine,hypoxanthine, purine, 2,6-diaminopurine, and 6,8-diaminopurine may have formed in outer space as well as on earth.
The origin of the term base reflects these compounds' chemical properties in acid-base reactions, but those properties are not especially important for understanding most of the biological functions of nucleobases. (W)
Base pairing: Two base pairs are produced by four nucleotide monomers, nucleobases are in blue. Guanine (G) is paired with cytosine (C) via threehydrogen bonds,in red. Adenine (A) is paired with uracil (U) via two hydrogen bonds, in red.
nucleoid
The nucleoid (meaning nucleus-like) is an irregularly shaped region within the prokaryotic cell that contains all or most of the genetic material. The chromosome of a prokaryote is circular, and its length is very large compared to the cell dimensions needing it to be compacted in order to fit. In contrast to the nucleus of a eukaryotic cell, it is not surrounded by a nuclear membrane. Instead, the nucleoid forms by condensation and functional arrangement with the help of chromosomal architectural proteins and RNA molecules as well as DNA supercoiling. The length of a genome widely varies (generally at least a few million base pairs) and a cell may contain multiple copies of it.
There is not yet a high-resolution structure known of a bacterial nucleoid, however key features have been researched in Escherichia coli as a model organism. In E. coli, the chromosomal DNA is on average negatively supercoiled and folded into plectonemic loops, which are confined to different physical regions, and rarely diffuse into each other. These loops spatially organize into megabase-sized regions called macrodomains, within which DNA sites frequently interact, but between which interactions are rare. The condensed and spatially organized DNA forms a helical ellipsoid that is radially confined in the cell. The 3D structure of the DNA in the nuceoid appears to vary depending on conditions and is linked to gene expression so that the nucleoid architecture and gene transcription are tightly interdependent, influencing each other reciprocally. (W)
Formation of the Escherichia coli nucleoid
A. An illustration of an open conformation of the circular genome of Escherichia coli. Arrows represent bi-directional DNA replication. The genetic position of the origin of bi-directional DNA replication (oriC) and the site of chromosome decatenation (dif) in the replication termination region (ter) are marked. Colors represent specific segments of DNA as discussed in C.
B. An illustration of a random coil form adopted by the pure circular DNA of Escherichia coli at thermal equilibrium without supercoils and additional stabilizing factors.
C. A cartoon of the chromosome of a newly born Escherichia coli cell. The genomic DNA is not only condensed by 1000-fold compared to its pure random coil form but is also spatially organized. oriC and dif are localized in the mid-cell, and specific regions of the DNA indicated by colors in A organize into spatially distinct domains. Six spatial domains have been identified in E. coli. Four domains (Ori, Ter, Left, and Right) are structured and two (NS-right and NS-left) are non-structured. The condensed and organized form of the DNA together with its associated proteins and RNAs is called nucleoid..
Diagram of both the TC-NER and GG-NER pathways. The two pathways differ only in initial DNA damage recognition.
"When DNA is damaged by sunlight, the damage is recognized differently depending on whether the DNA is transcriptionally active (transcription-coupled repair) or not (global excision repair). After the initial recognition step, the damage is repaired in a similar manner with the final outcome being the restoration of the normal nucleotide sequence. A more detailed description is provided in the text.".
Schematic depicts binding of proteins involved with GG-NER.
Cartoon depiction of global genomic repair, a subpathway of nucleotide excision repair.Shows the binding of involved proteins at various steps (XPC, HR23b, CAK, TFIIH, XPA, RPA, XPG, XPF, ERCC1, TFIIH, PCNA, RFC, ADN Pol, Ligase I).
Schematic depicts binding of proteins involved with TC-NER.
Cartoon depiction of transcription coupled repair, a subpathway of nucleotide excision repair. Shows the binding of involved proteins at various steps (CSB, XPA, RPA, XPG, XPF, ERCC1, CSA-CNS, TFIIH, CAK, PCNA, RFC, Ligase I). Stalled RNA Polymerase II triggers transcription coupled repair.
A schematic representation of models for the nucleotide excision repair pathway controlled by Uvr proteins.
DNA excision pathways work in tandem to repair DNA damage. Unrepaired damage or malfunctioning proteins associated with excision repair could lead to unregulated cell growth and cancer.
Schematic showing how two excision repair pathways (mismatch repair and nucleotide excision repair) work together to repair DNA damage and prevent cancer.
nucleolus organizer region
Silver-stained nucleolus organizer region (arrow) at the tip of a chromosome of the Gecko Lepidodactylus lugubris
Nucleolus organizer regions (NORs) are chromosomal regions crucial for the formation of the nucleolus. In humans, the NORs are located on the short arms of the acrocentric chromosomes 13, 14, 15, 21 and 22, the genes RNR1,RNR2,RNR3,RNR4, and RNR5 respectively. These regions code for 5.8S,18S, and 28Sribosomal RNA. The NORs are "sandwiched" between the repetitive,heterochromaticDNA sequences of the centromeres and telomeres. The exact sequence of these regions is not included in the human reference genome as of 2016 or the GRCh38.p10 released January 6, 2017. On 28 February 2019, GRCh38.p13 was released, which added the NOR sequences for the short arms of chromosomes 13, 14, 15, 21, and 22. However, it is known that NORs contain tandem copies of ribosomal DNA (rDNA) genes. Some sequences of flanking sequences proximal and distal to NORs have been reported. The NORs of a loris have been reported to be highly variable. There are also DNA sequences related to rDNA that are on other chromosomes and may be involved in nucleoli formation. (W)
The location of NORs and the nucleolar cycle in human cells. (A) Schematic showing a human rDNA array expanded to show the pre-rRNA-coding sequences that are transcribed by RNA Pol I. The positions of mature rRNA-coding sequences, ETSs, and ITSs are indicated. (B) The locations of NORs on the acrocentric chromosome are indicated. The short arms, circled in red, are missing from the current genome draft GRCh38.p7. (C) During cell division, transcription ceases, and nucleoli disappear. NORs can be observed as achromatic gaps on DAPI-stained metaphase chromosomes due to undercondensation of rDNA (red dotted line). Silent NORs (solid red) fail to show this morphology and do not contribute to nucleolar formation. Transcription resumes in anaphase, and nucleoli form around individual active NORs. In most cell types, these then fuse, producing characteristic large nucleoli surrounded by heterochromatin.(L)
Cross-sectional drawing of the Ebola virus particle, with structures of the major proteins shown and labeled at the side. Pale circles represent domains too flexible to be observed in the experimental structure. Drawn by David Goodsell from PDB files 3csy, 4ldd, 4qb0, 3vne, 3fke, and 2i8b..
Two corresponding nucleosides, the deoxyribonucleoside, deoxyadenosine, and the ribonucleoside, adenosine. Both are in line-angle representation, where the presence of carbon atoms are inferred at each angle, as are the hydrogen atoms attached to the carbon, to fill its valency (to having four bonds).
While a nucleoside is a nucleobase linked to a sugar, a nucleotide is composed of a nucleoside and one or more phosphate groups. Thus, nucleosides can be phosphorylated by specific kinases in the cell on the sugar's primary alcohol group (-CH2-OH) to produce nucleotides. Nucleotides are the molecular building-blocks of DNA and RNA.(W)
nucleoside triphosphate
A nucleoside triphosphate is a molecule containing a nitrogenous base bound to a 5-carbon sugar (either ribose or deoxyribose), with three phosphate groups bound to the sugar. It is an example of a nucleotide. They are the molecular precursors of both DNA and RNA, which are chains of nucleotides made through the processes of DNA replication and transcription. Nucleoside triphosphates also serve as a source of energy for cellular reactions and are involved in signalling pathways. (W)
Schematic showing the structure of nucleoside triphosphates. Nucleosides consist of a 5-carbon sugar (pentose) connected to a nitrogenous base through a 1' glycosidic bond. Nucleotides are nucleosides with a variable number of phosphate groups connected to the 5' carbon. Nucleoside triphosphates are a specific type of nucleotide. This figure also shows the five common nitrogenous bases found in DNA and RNA on the right.
In nucleic acid synthesis, the 3’ OH of a growing chain of nucleotides attacks the α-phosphate on the next NTP to be incorporated (blue), resulting in a phosphodiester linkage and the release of pyrophosphate (PPi). This figure shows DNA synthesis, but RNA synthesis occurs through the same mechanism.
How Nucleoside Triphosphates Provide Energy for DNA Replication
📹 How Nucleoside Triphosphates Provide Energy for DNA Replication
nucleosome
A nucleosome is the basic structural unit of DNA packaging in eukaryotes. The structure of a nucleosome consists of a segment of DNA wound around eight histone proteins and resembles thread wrapped around a spool. The nucleosome is the fundamental subunit of chromatin. Each nucleosome is composed of a little less than two turns of DNA wrapped around a set of eight proteins called histones, which are known as a histone octamer. Each histone octamer is composed of two copies each of the histone proteins H2A,H2B,H3, and H4.
DNA must be compacted into nucleosomes to fit within the cell nucleus. In addition to nucleosome wrapping, eukaryotic chromatin is further compacted by being folded into a series of more complex structures, eventually forming a chromosome. Each human cell contains about 30 million nucleosomes.
Nucleosomes are thought to carry epigenetically inherited information in the form of covalent modifications of their core histones. Nucleosome positions in the genome are not random, and it is important to know where each nucleosome is located because this determines the accessibility of the DNA to regulatory proteins. (W)
The crystal structure of the nucleosome core particle consisting of H2A , H2B , H3 and H4 core histones, and DNA. The view is from the top through the superhelical axis.
The crystal structure of the nucleosome core particle (PDB:1EQZ).
The current chromatin compaction model.
Histone tails and their function in chromatin formation.
(a) The flexible amino- terminal tail of each histone extends from the surface of the histone octamer. (b) In 30-nm fibers, the histone tails of one nucleosome interact with the histones and DNA of adjacent nucleosomes. In some chromatin, histone tails also interact with non-histone proteins (green) that help package the DNA. Linker histones (histone H1, red) also contribute to chromatin formation. Acetylation of histone tails alters their interaction with other nucleosomes and non-histone proteins, generally resulting in a more open chromatin structure. (W)
Showing the arrangement of nucleotides within the structure of nucleic acids: At lower left, a monophosphate nucleotide; its nitrogenous base represents one side of a base-pair. At upper right, four nucleotides form two base-pairs: thymine and adenine (connected by double hydrogen bonds) and guanine and cytosine (connected by triple hydrogen bonds). The individual nucleotide monomers are chain-joined at their sugar and phosphate molecules, forming two 'backbones' (a double helix) of a nucleic acid, shown at upper left.
Structural elements of three nucleotides—where one-, two- or three-phosphates are attached to the nucleoside (in yellow, blue, green) at center: 1st, the nucleotide termed as a nucleoside monophosphate is formed by adding a phosphate (in red); 2nd, adding a second phosphate forms a nucleoside diphosphate; 3rd, adding a third phosphate results in a nucleoside triphosphate. + The nitrogenous base (nucleobase) is indicated by "Base" and "glycosidic bond" (sugar bond). All five primary, or canonical, bases—the purines and pyrimidines—are sketched at right (in blue).

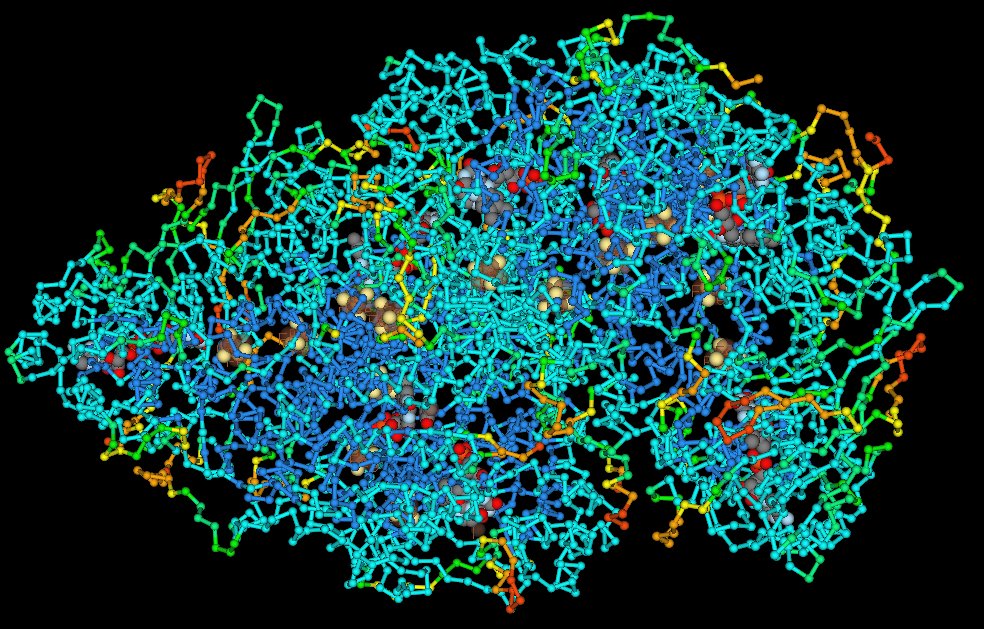
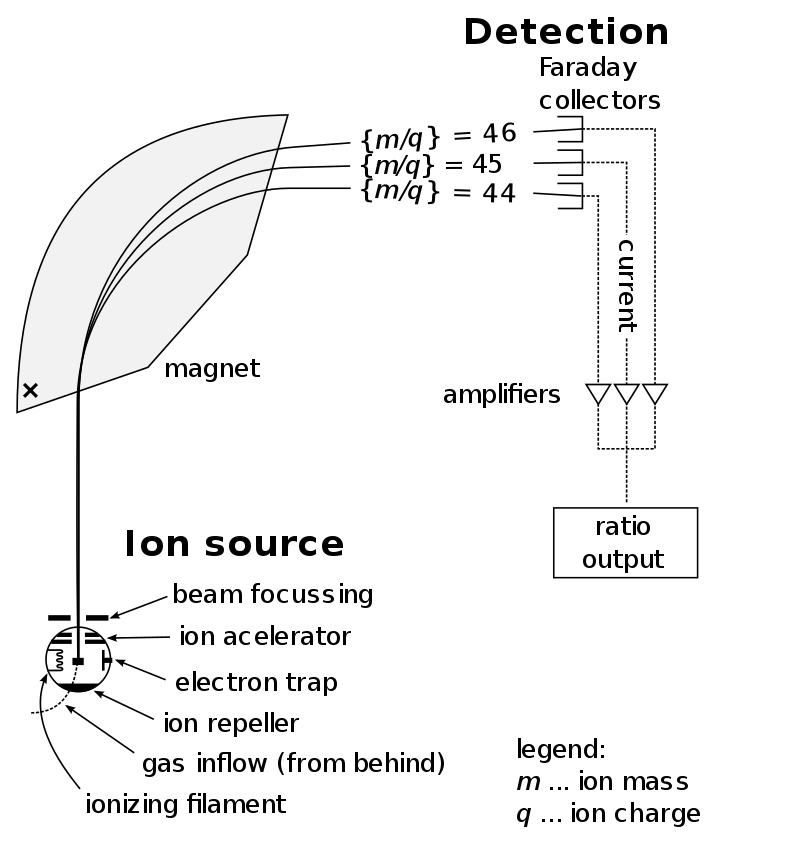
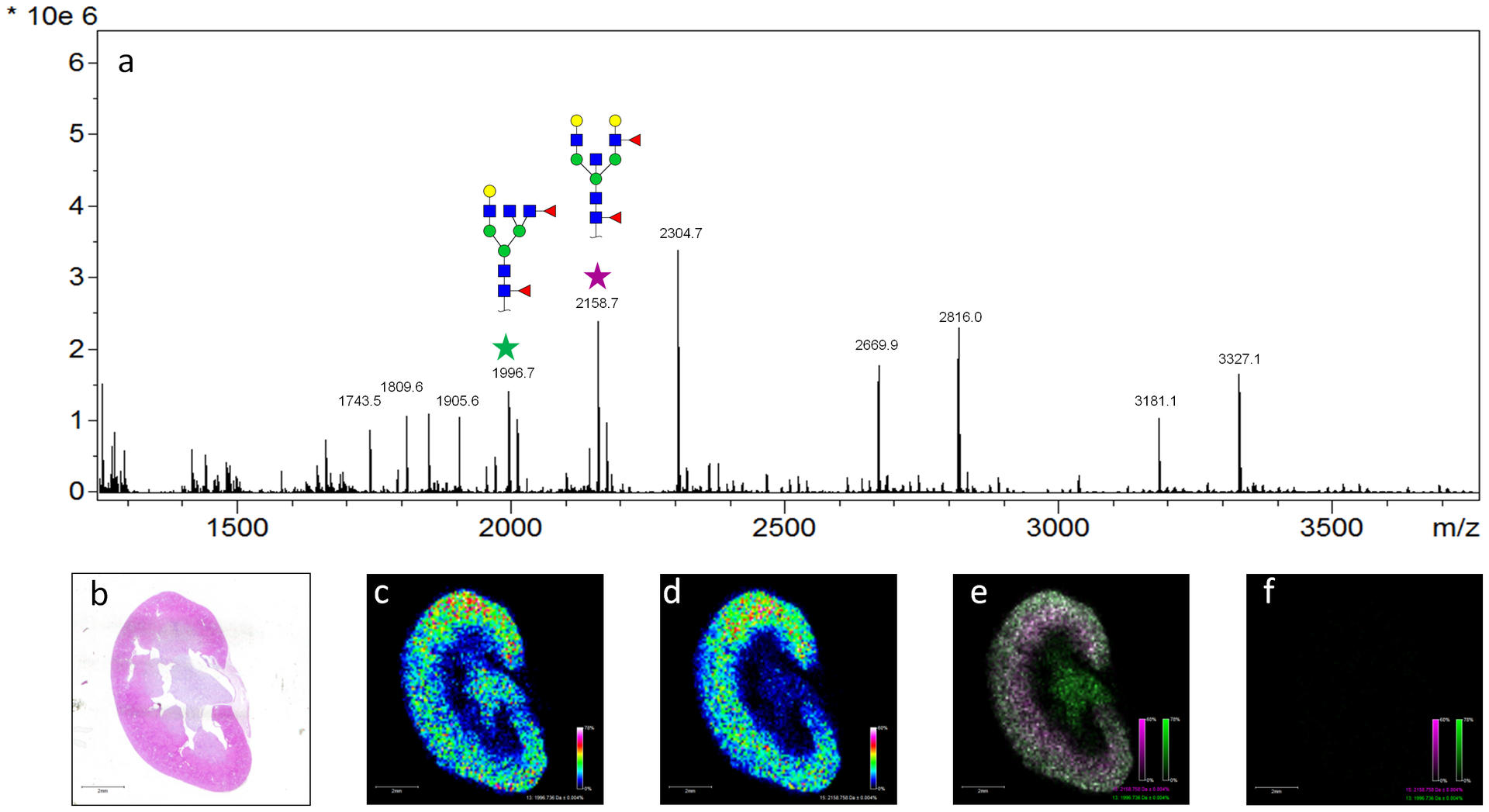
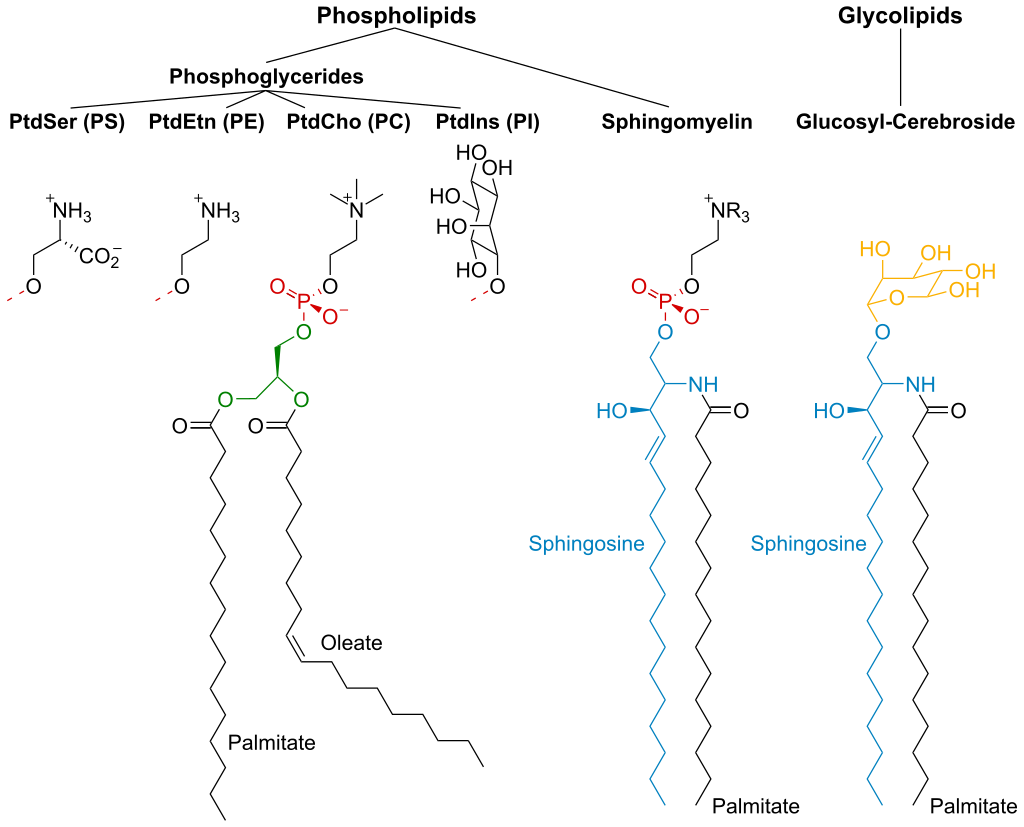
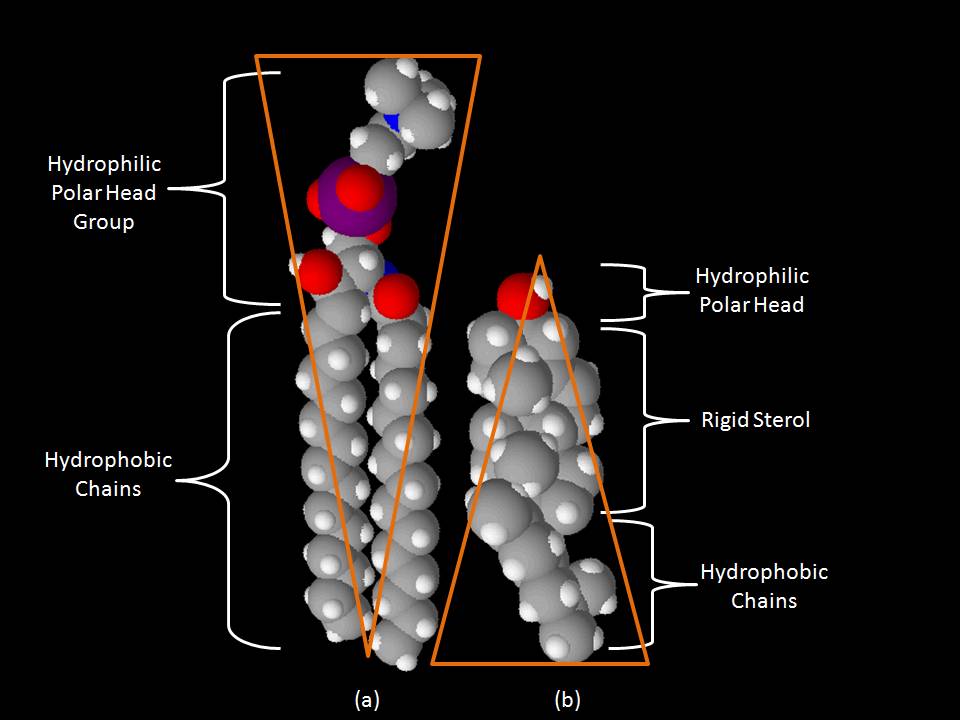
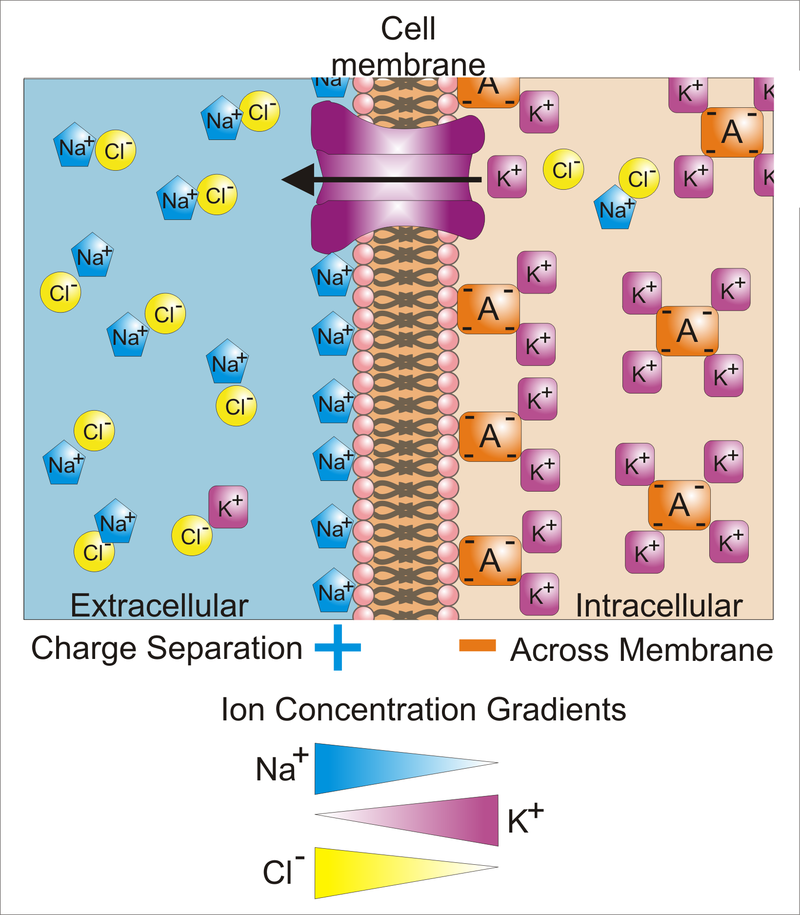
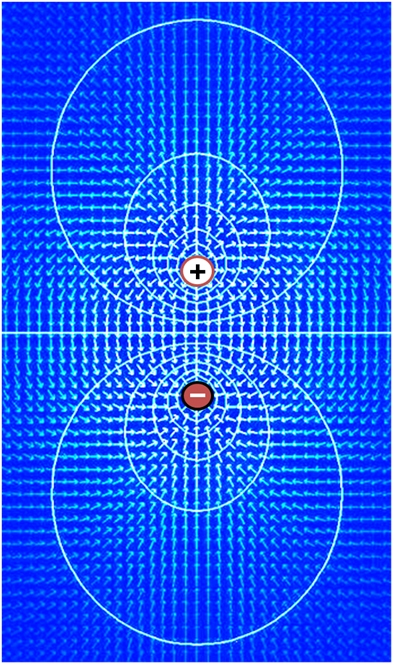
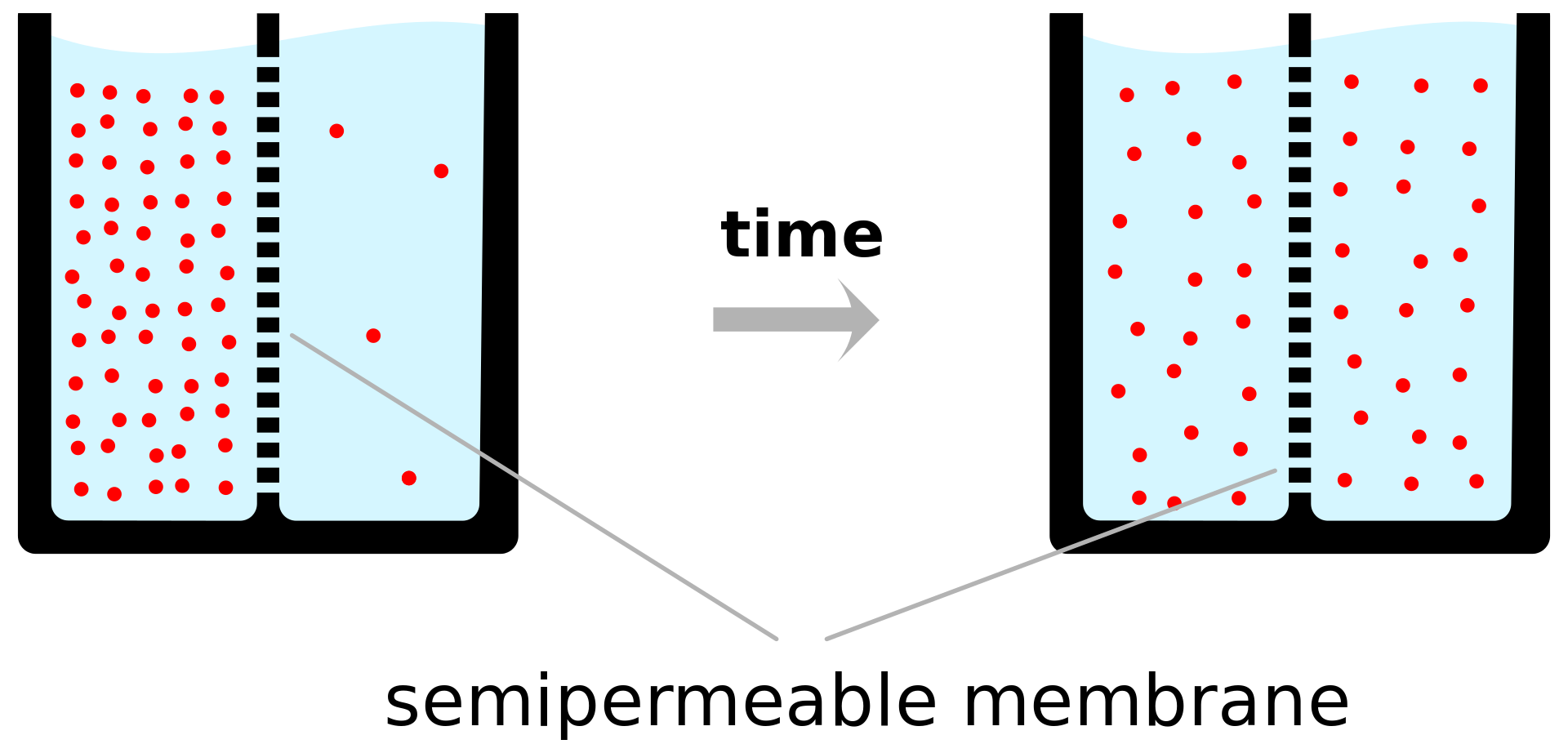
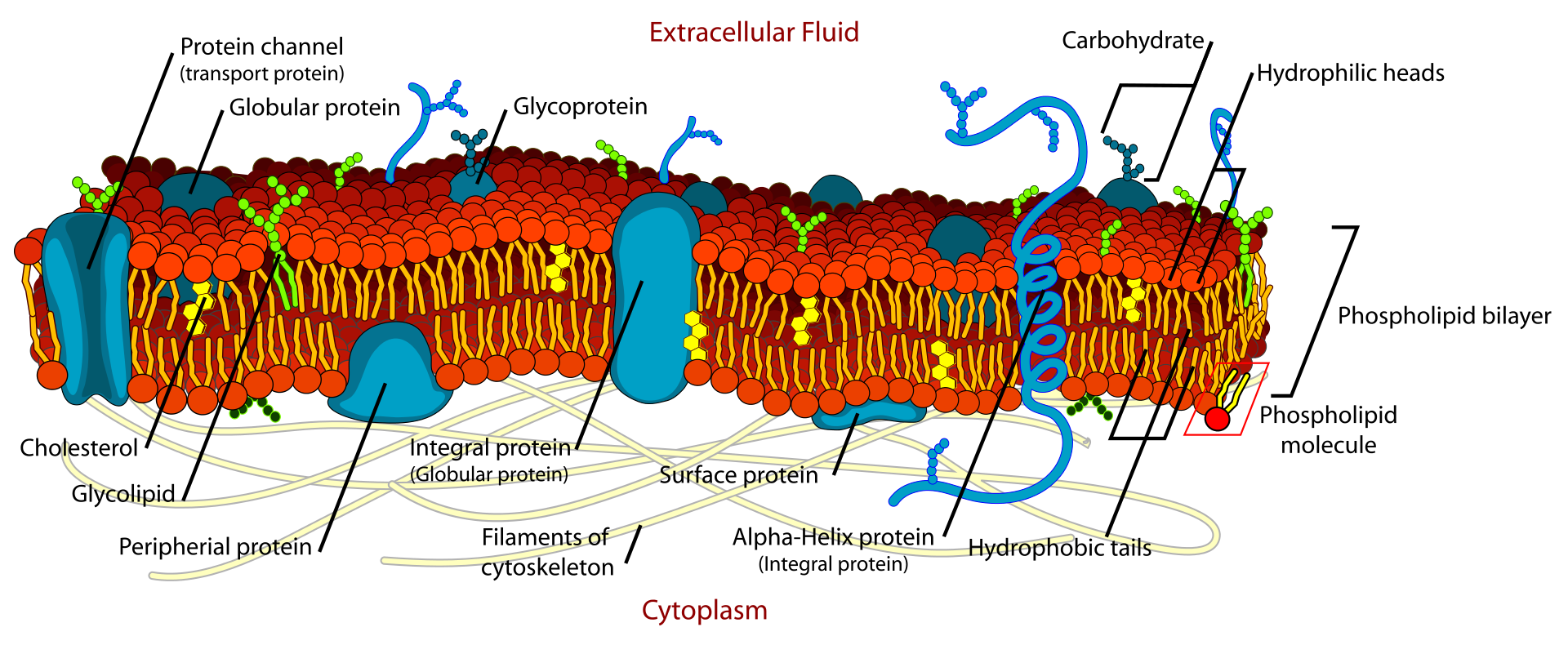
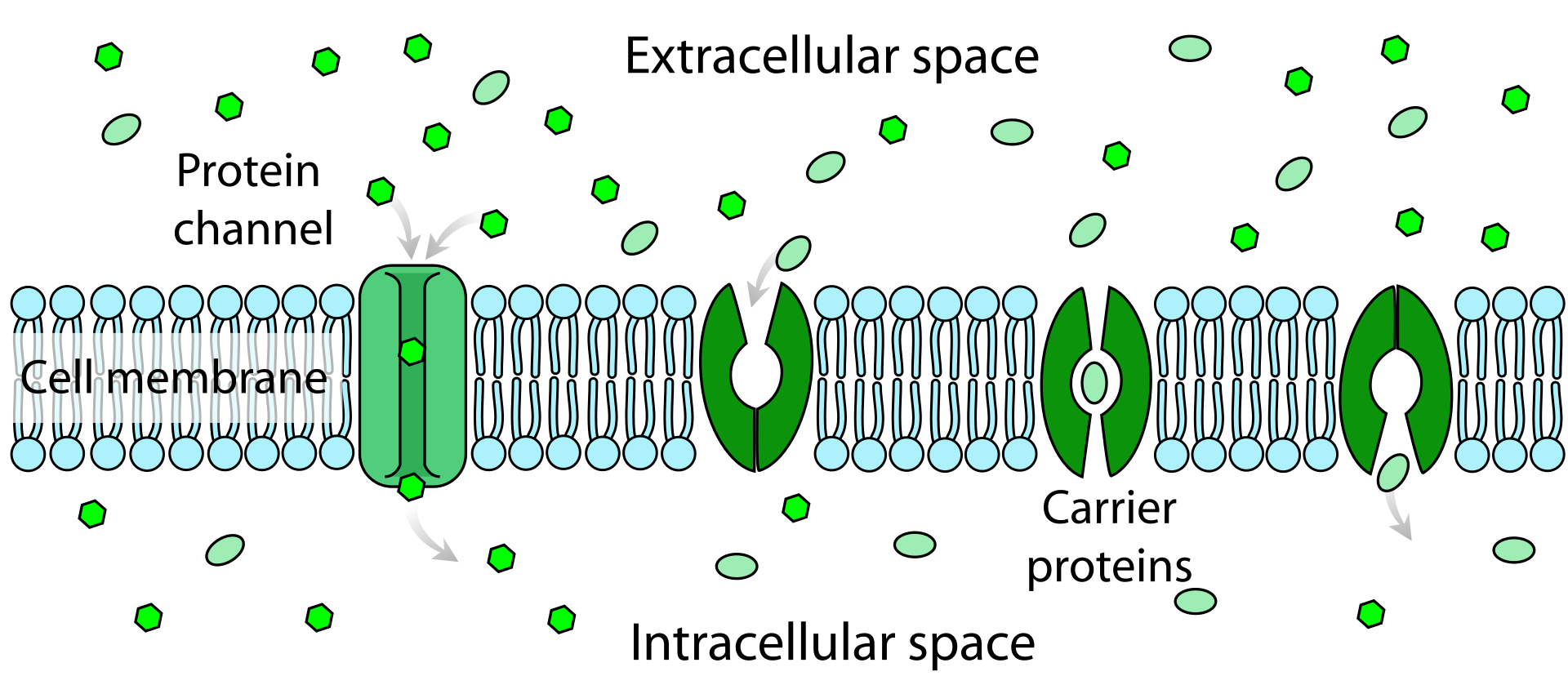
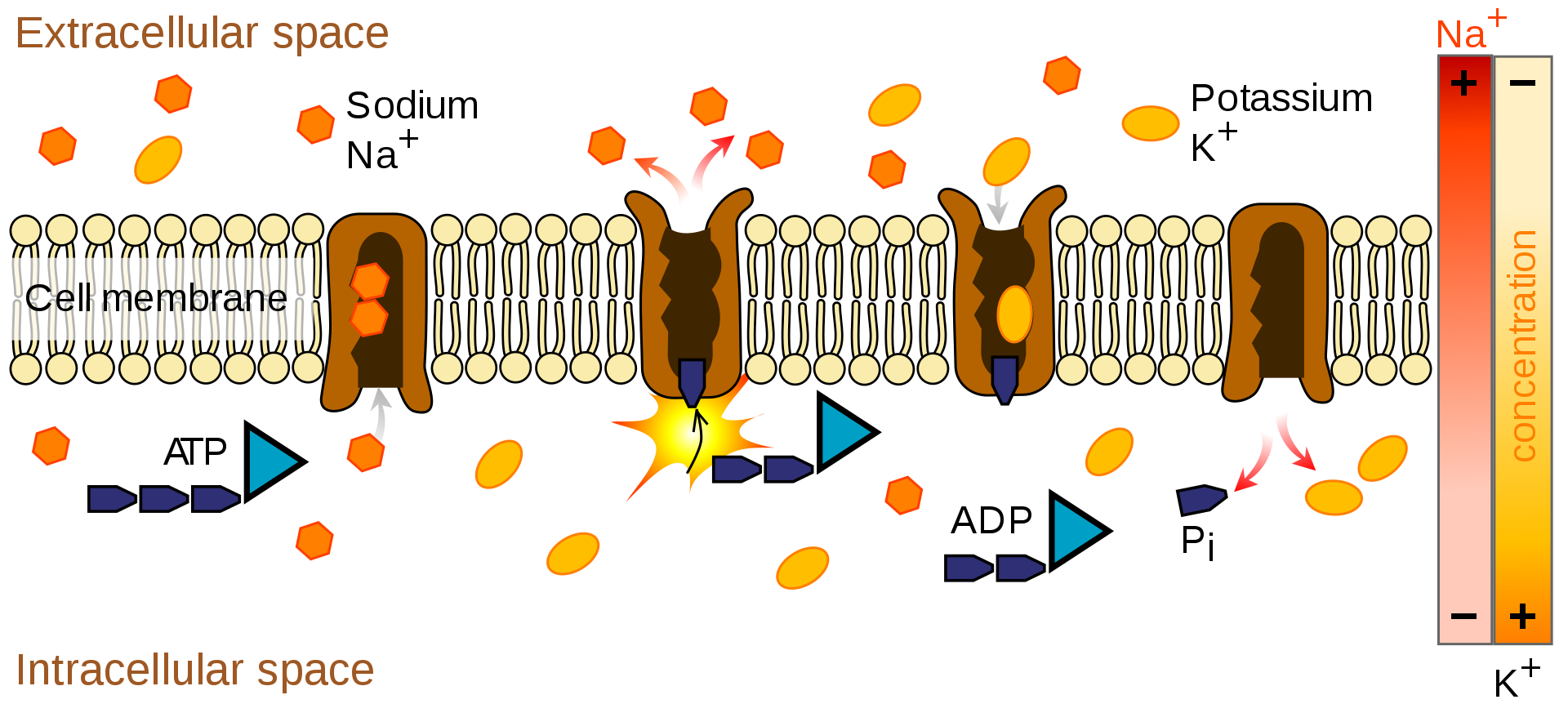
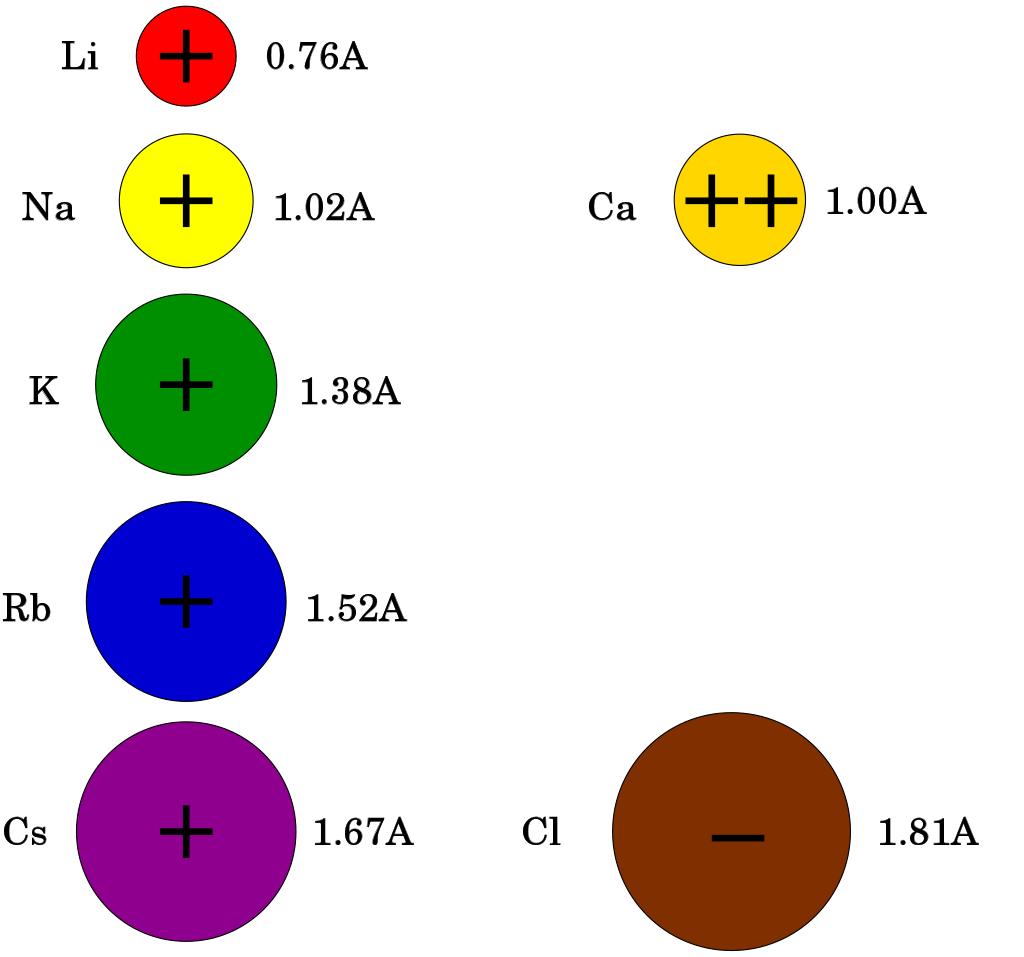
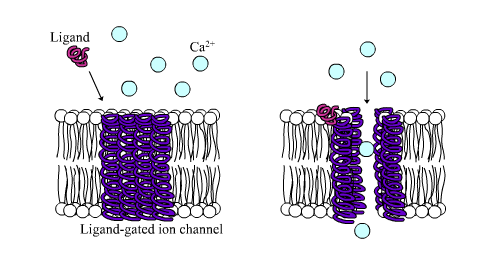
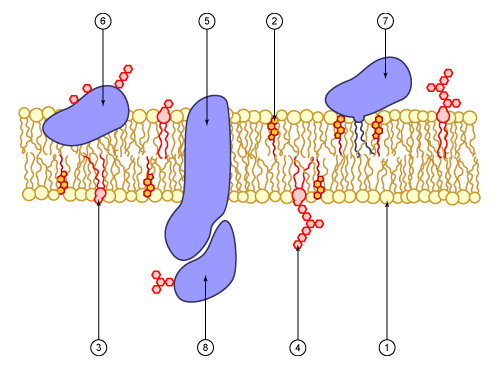
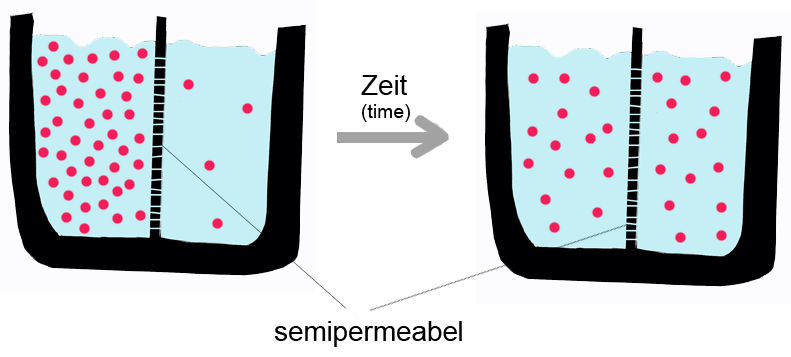
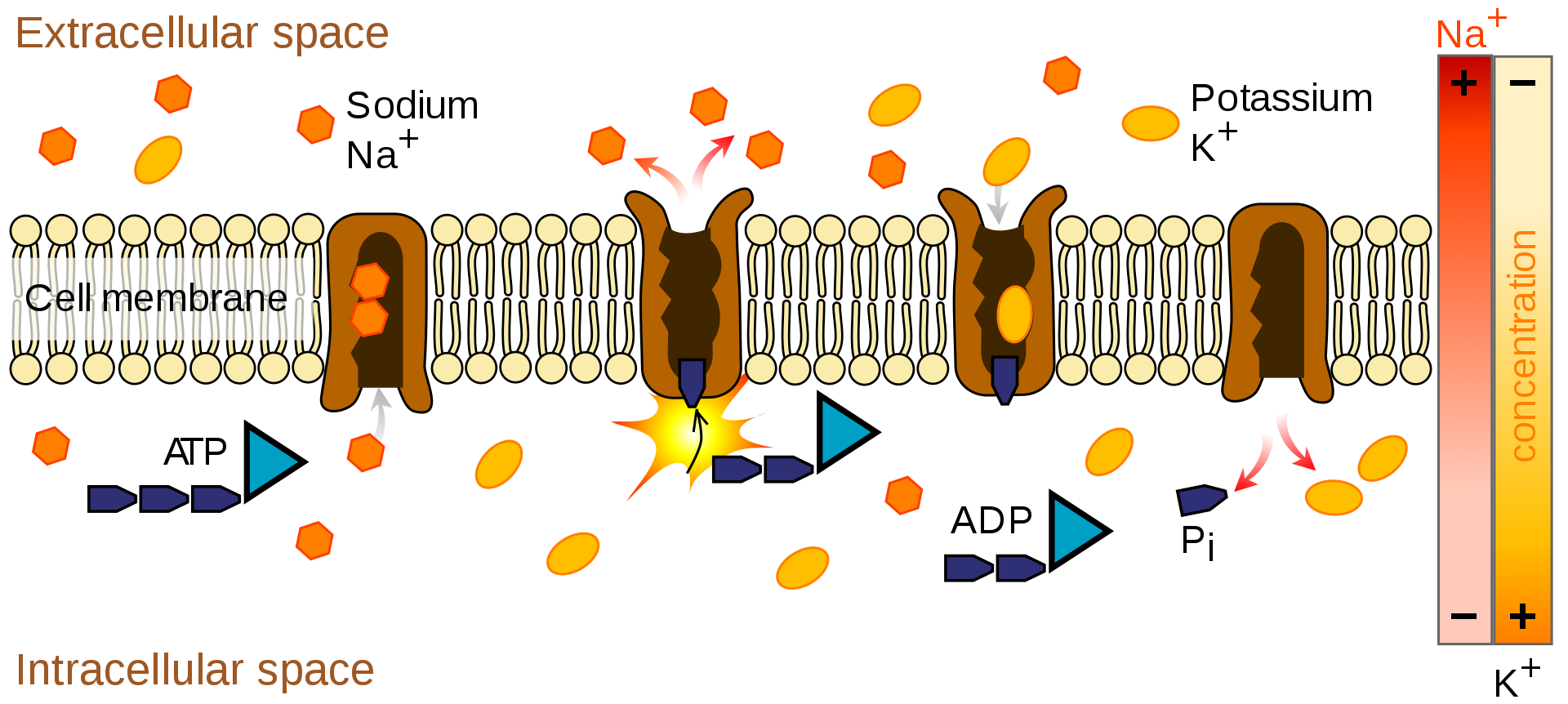
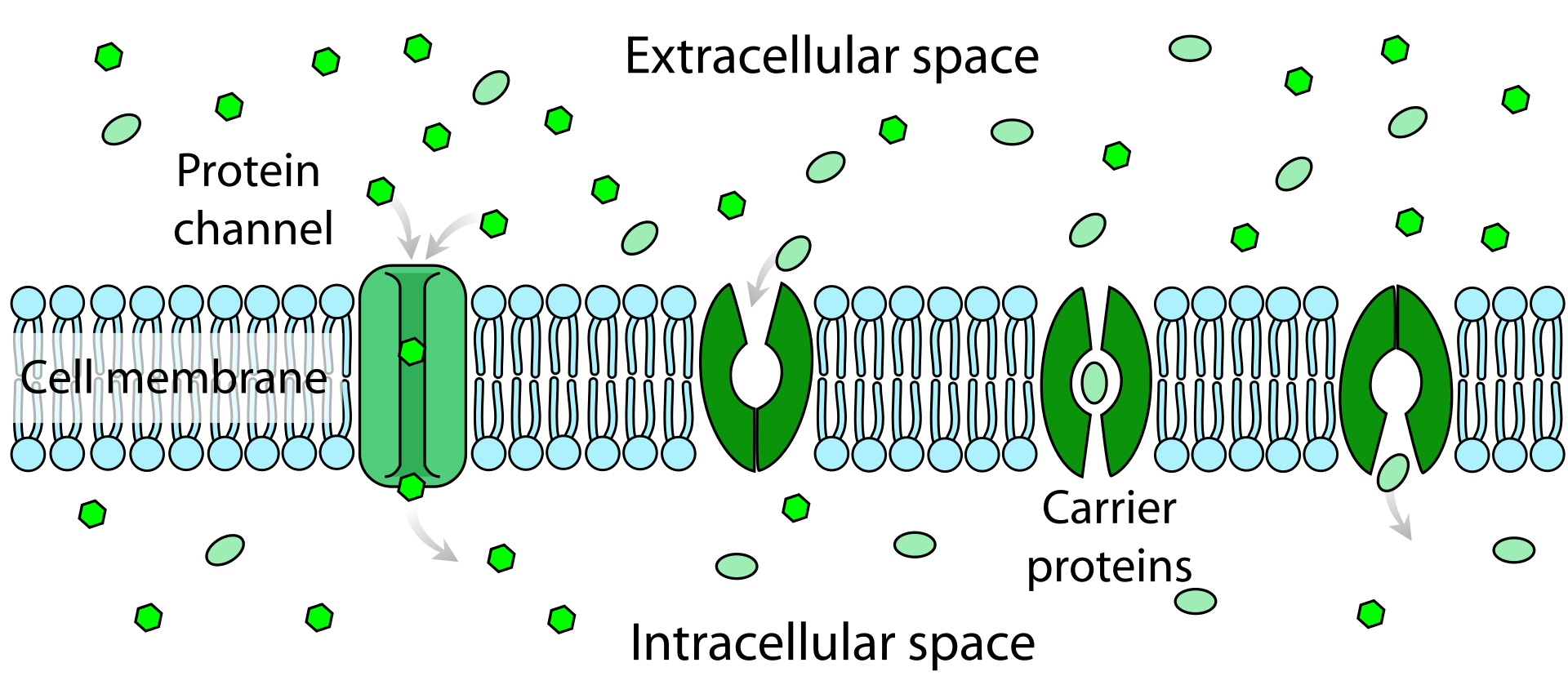
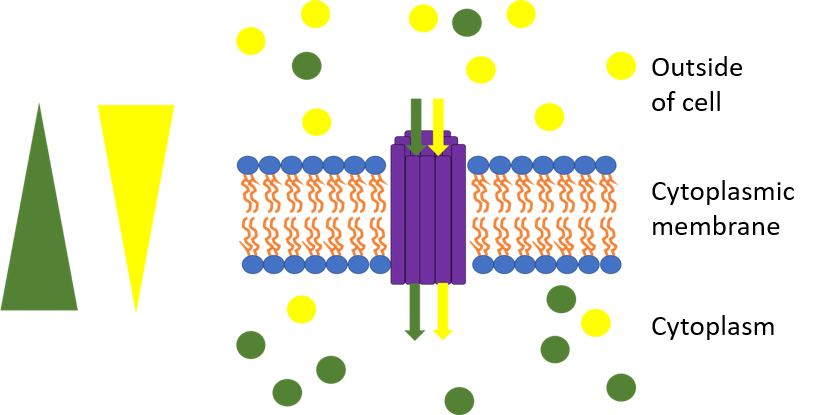
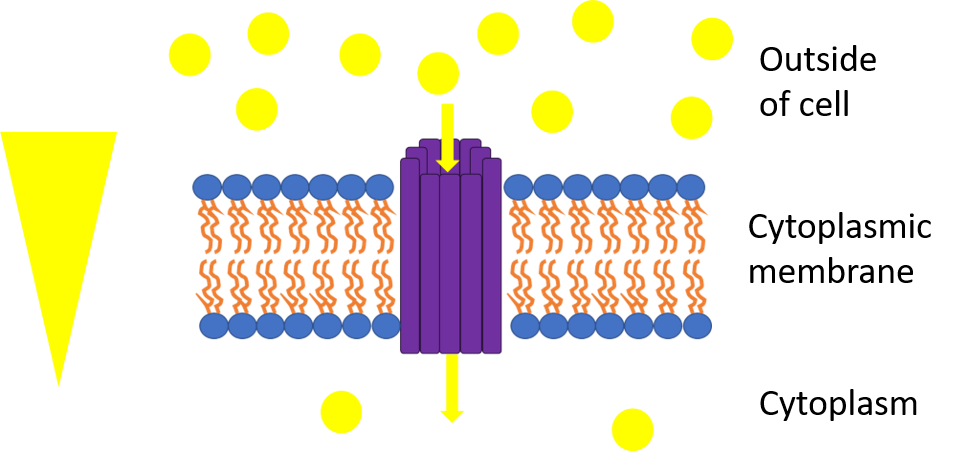
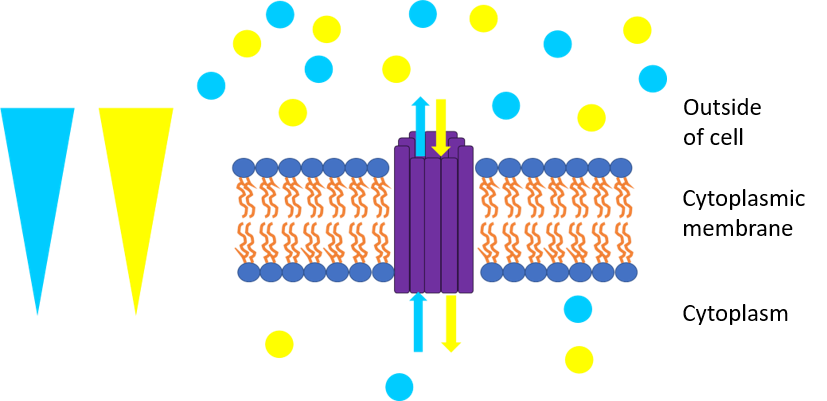
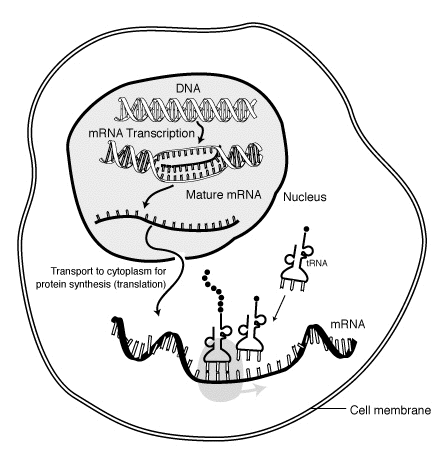

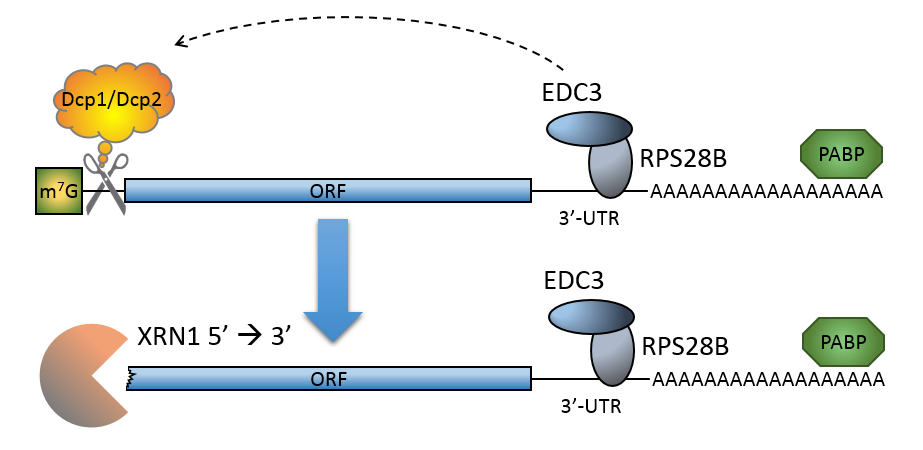
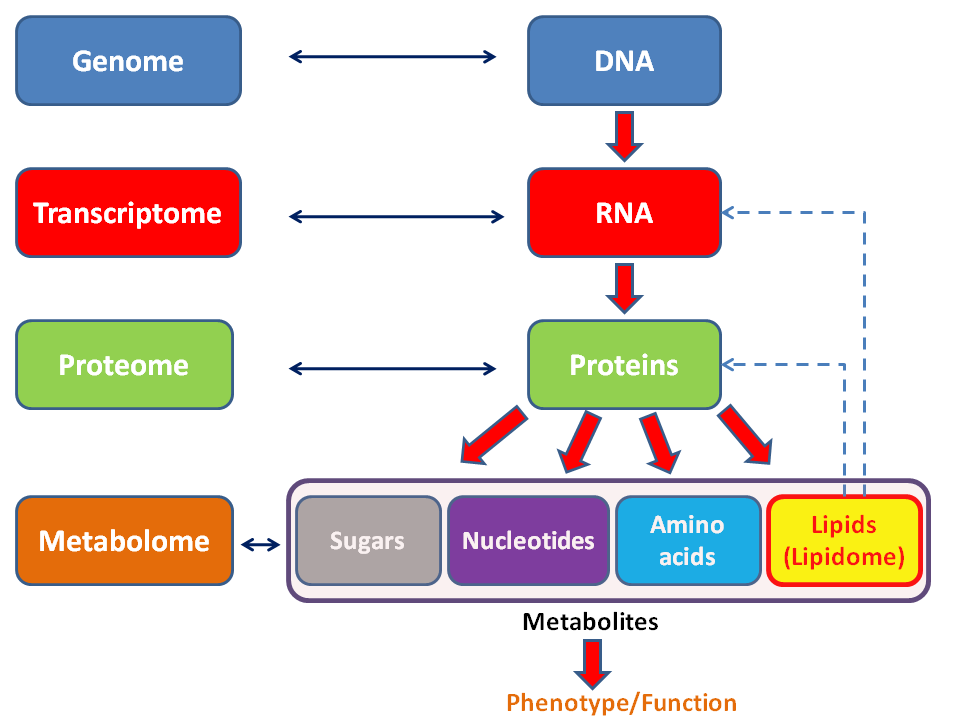
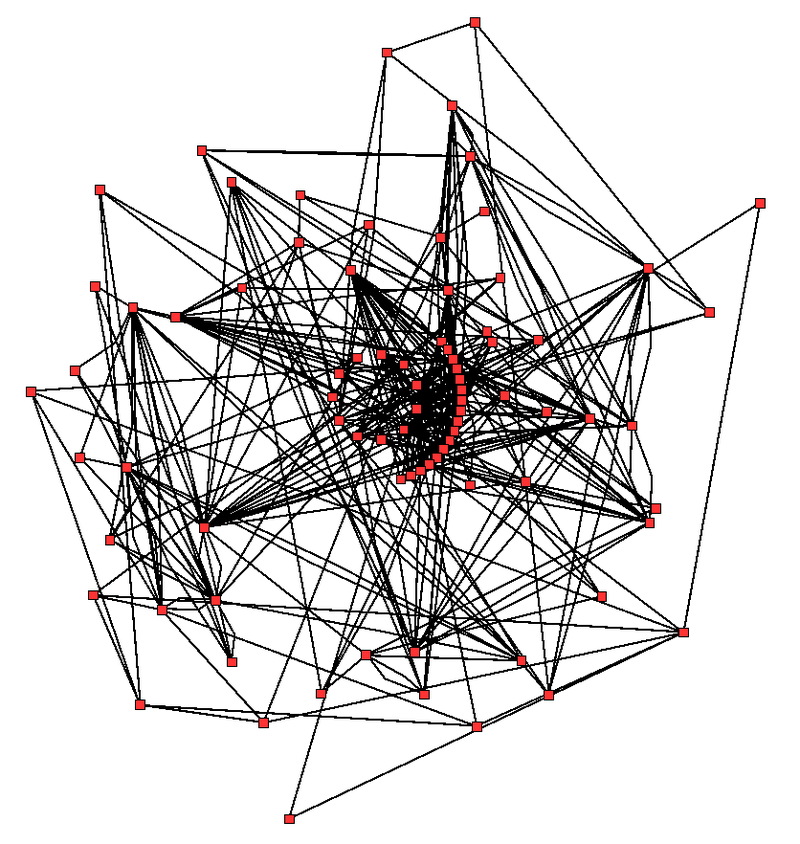

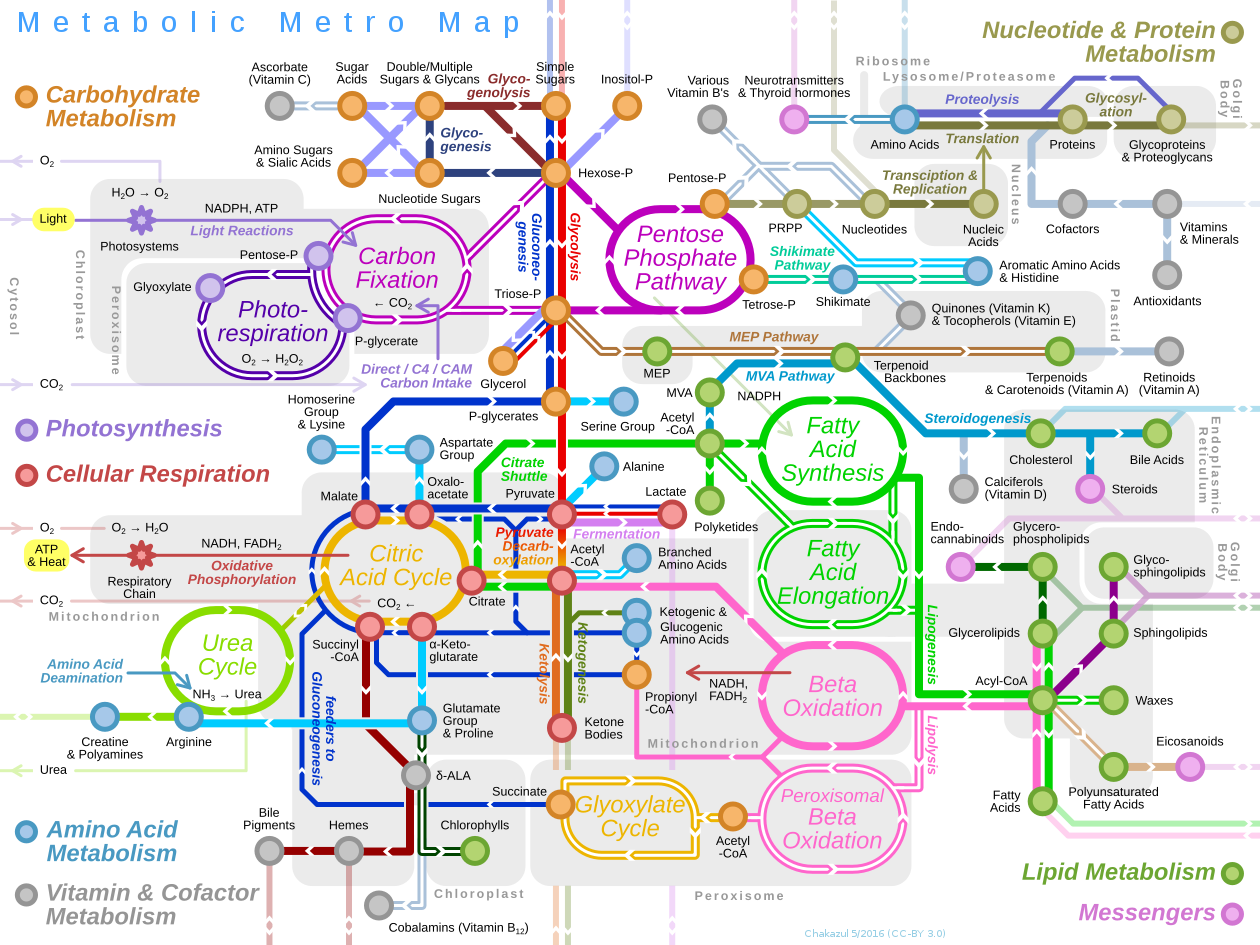

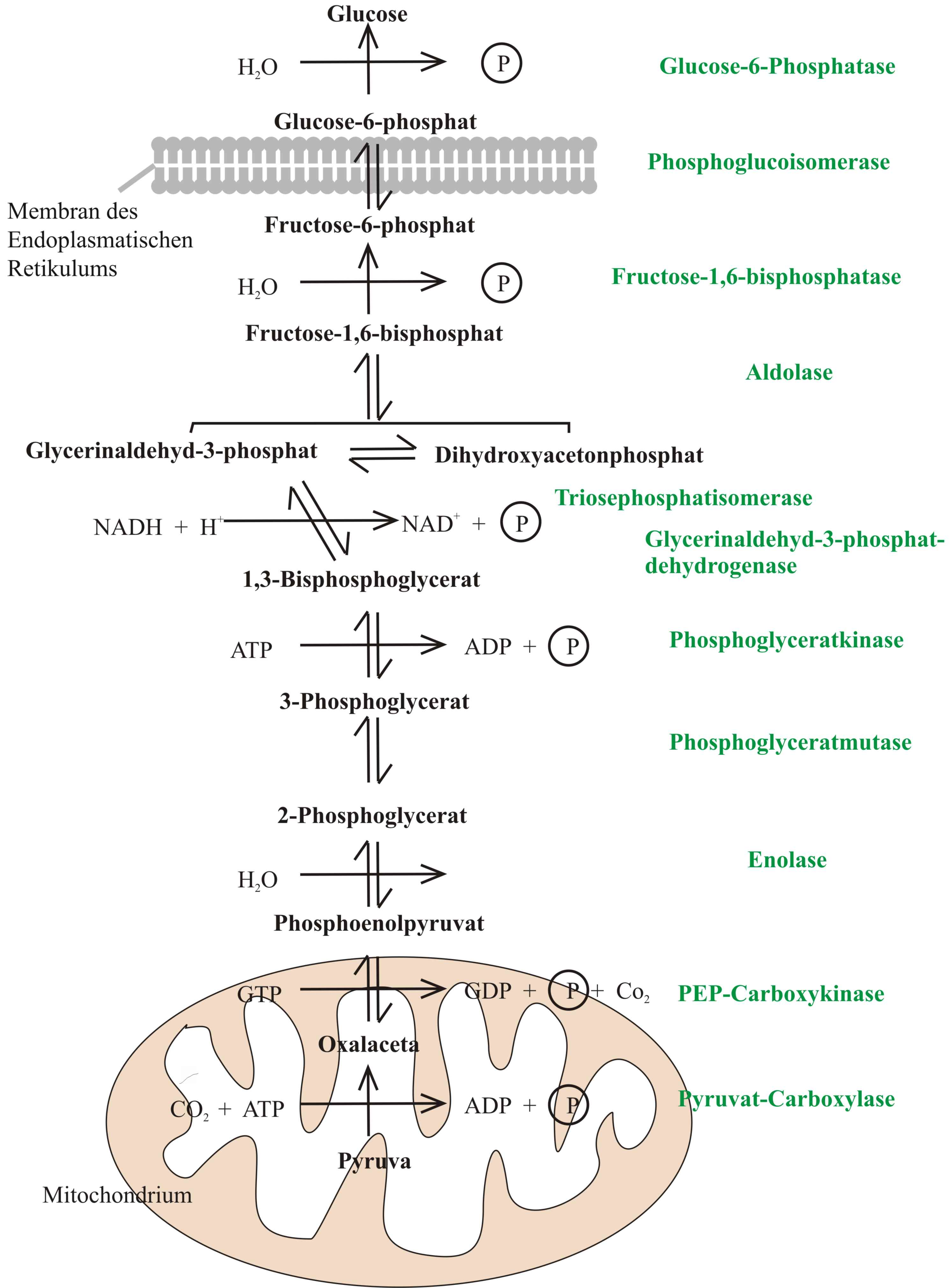
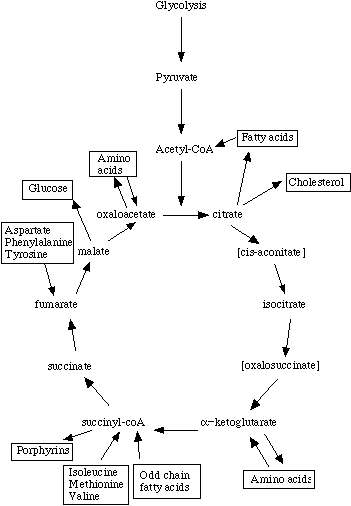
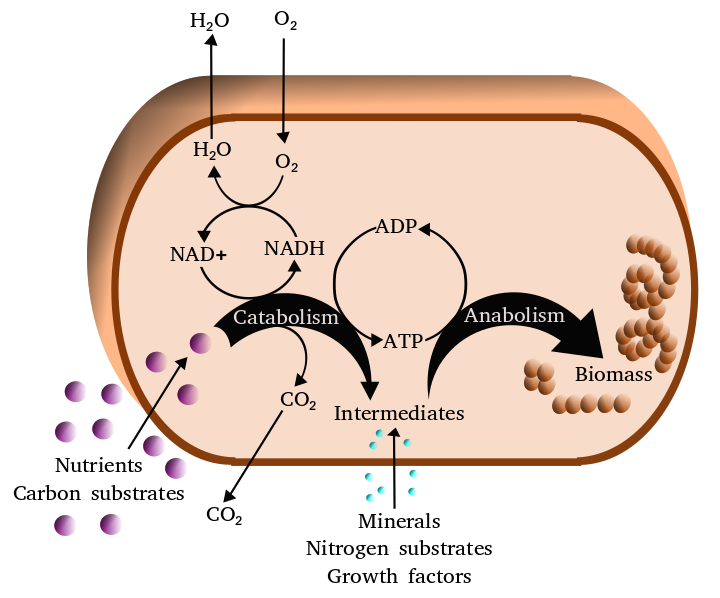
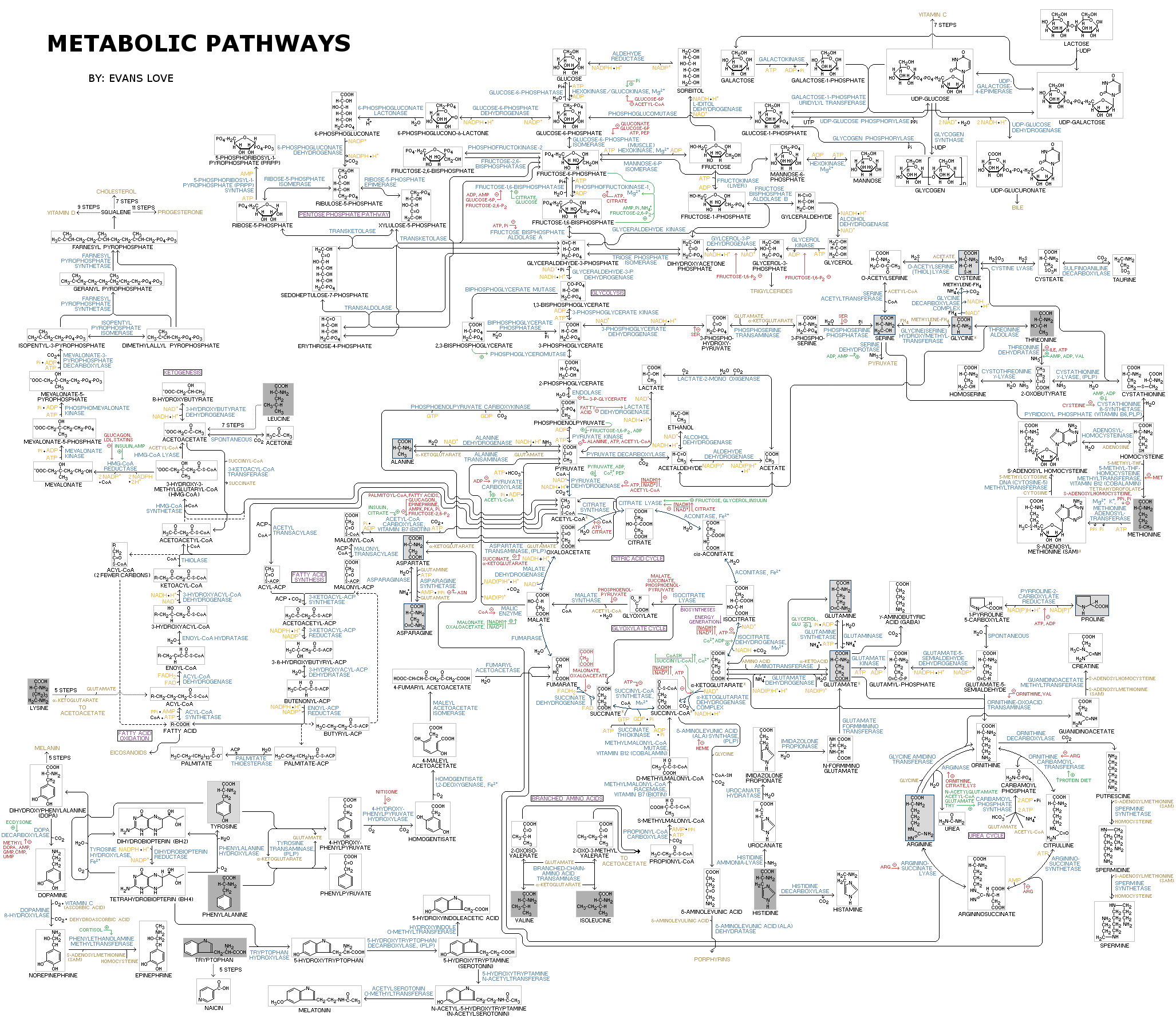
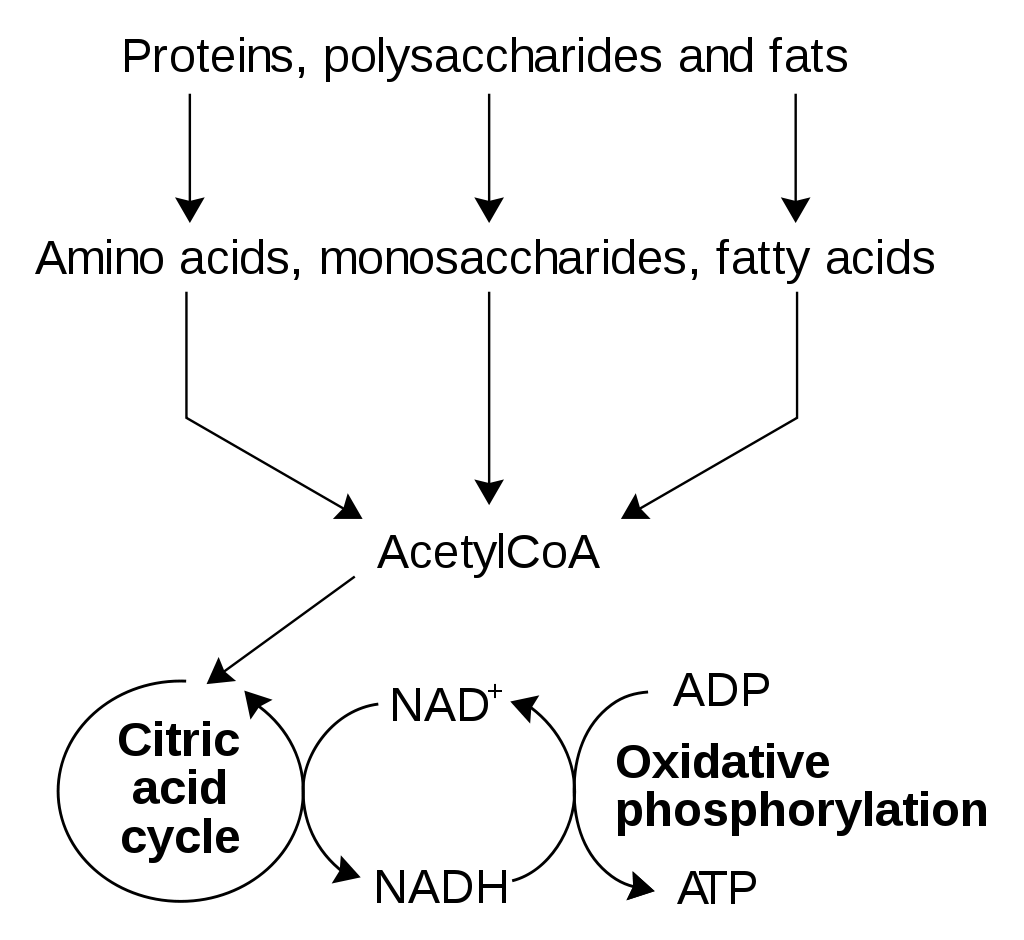
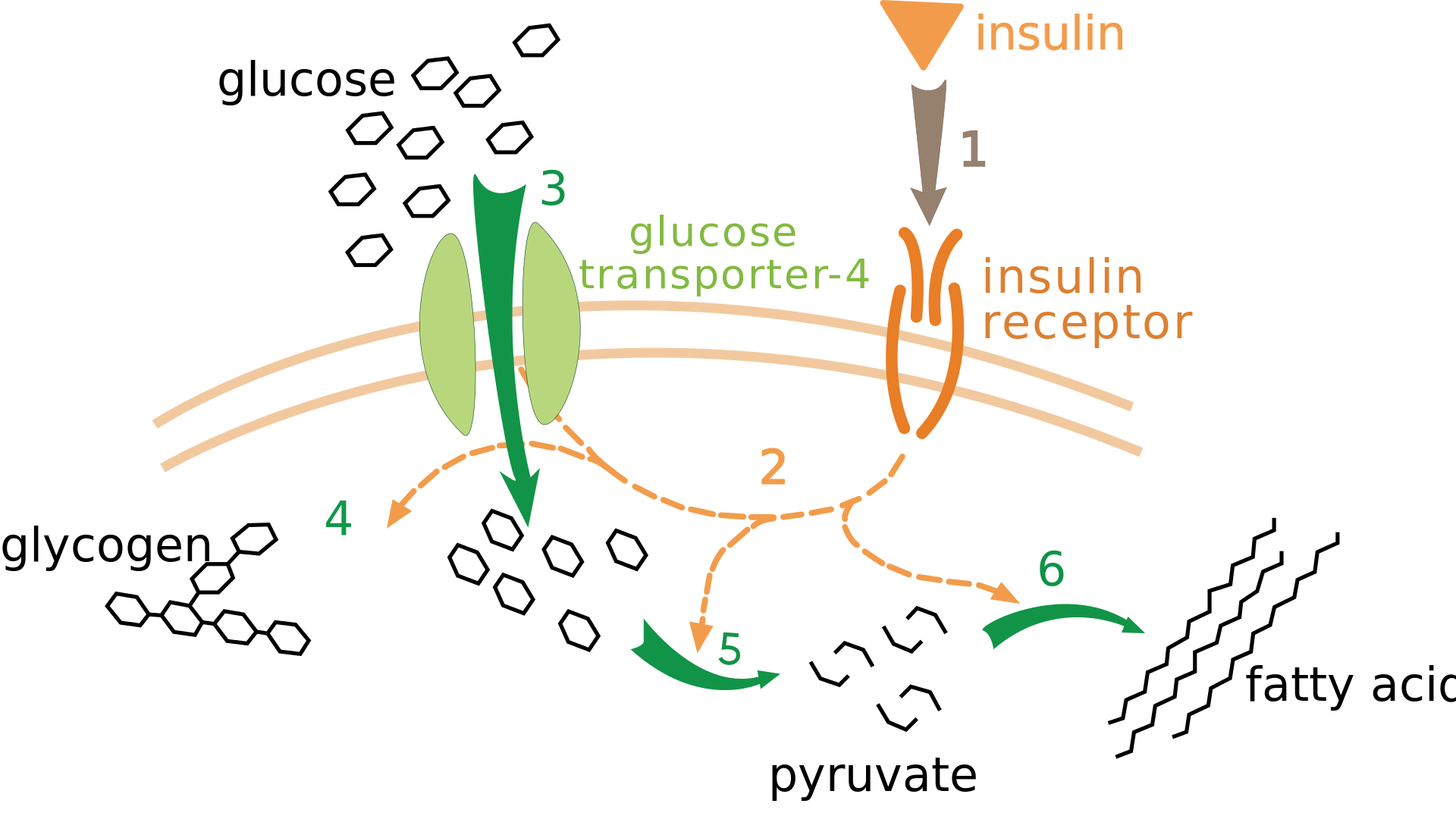
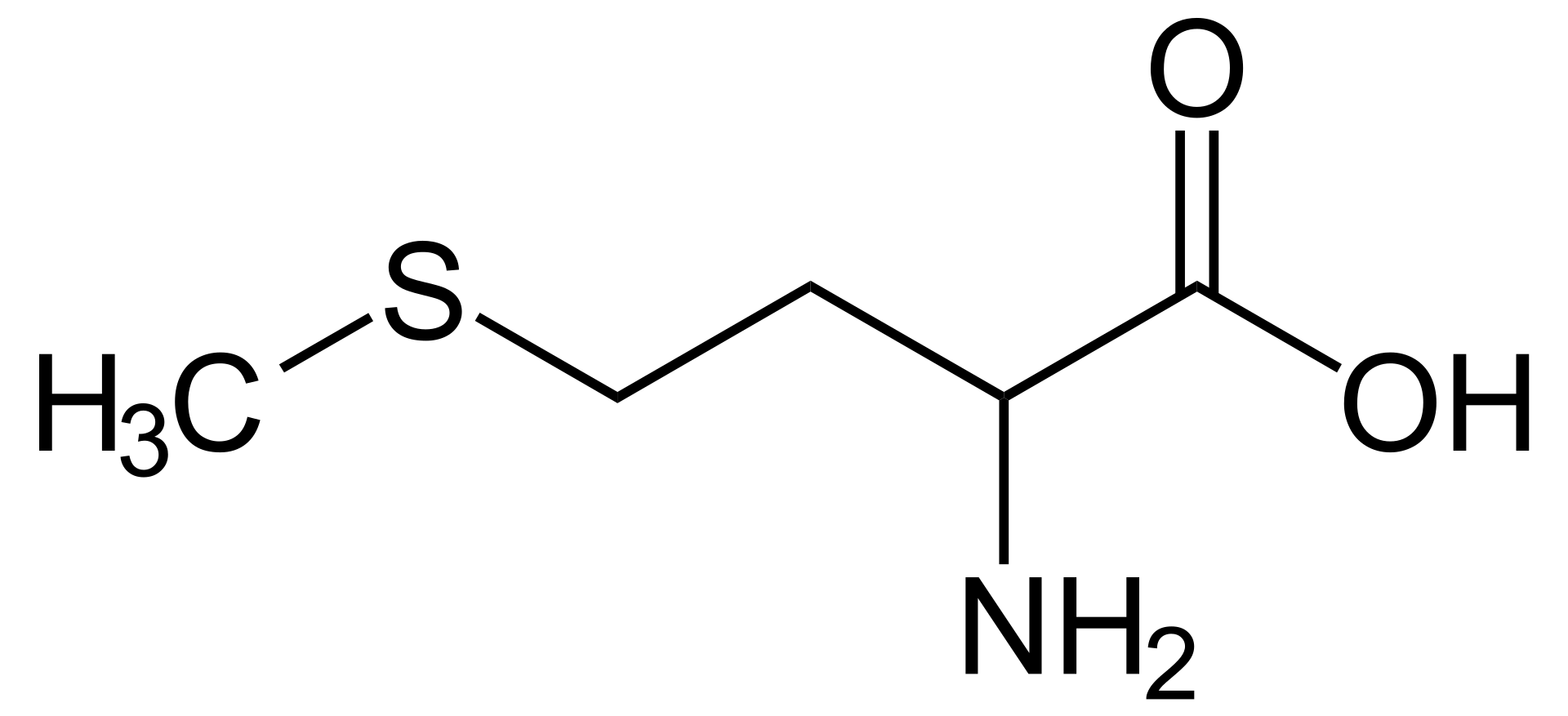
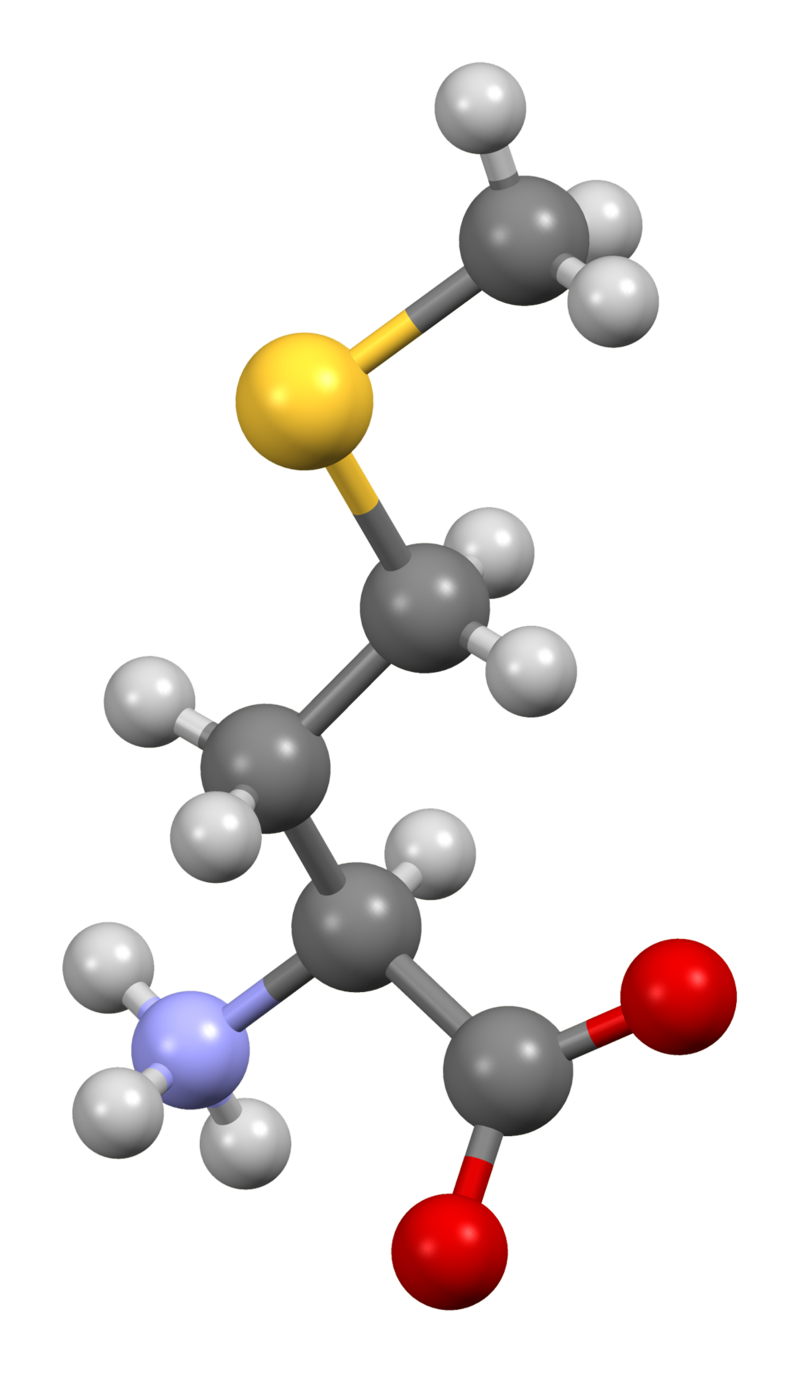
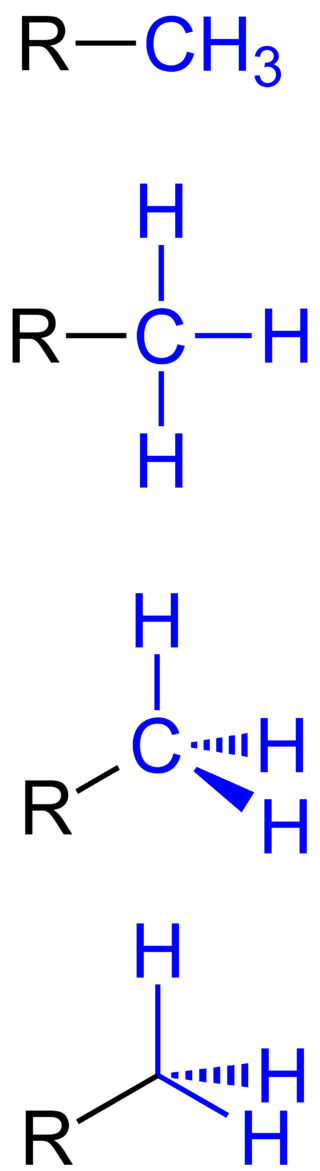
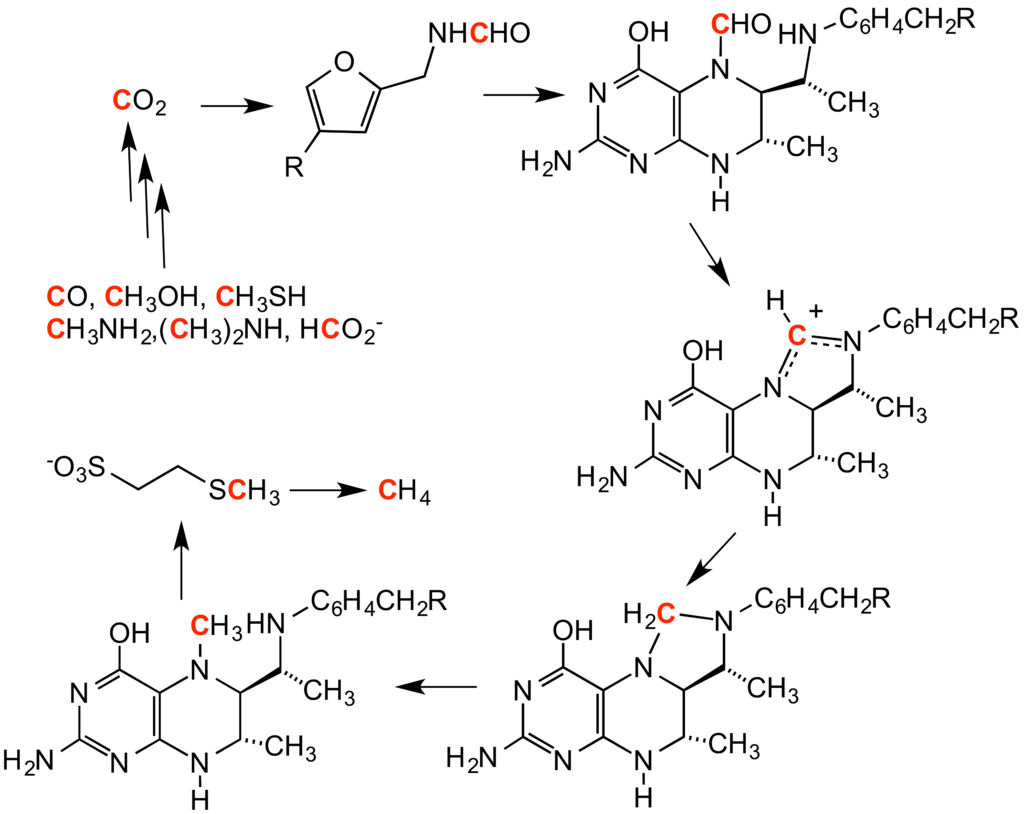
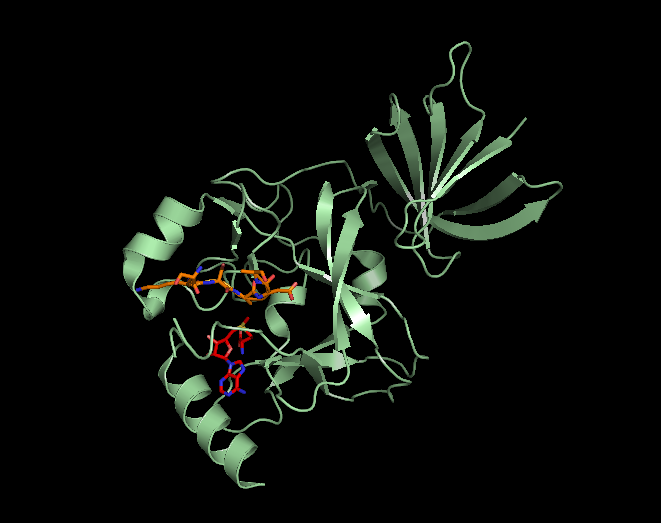
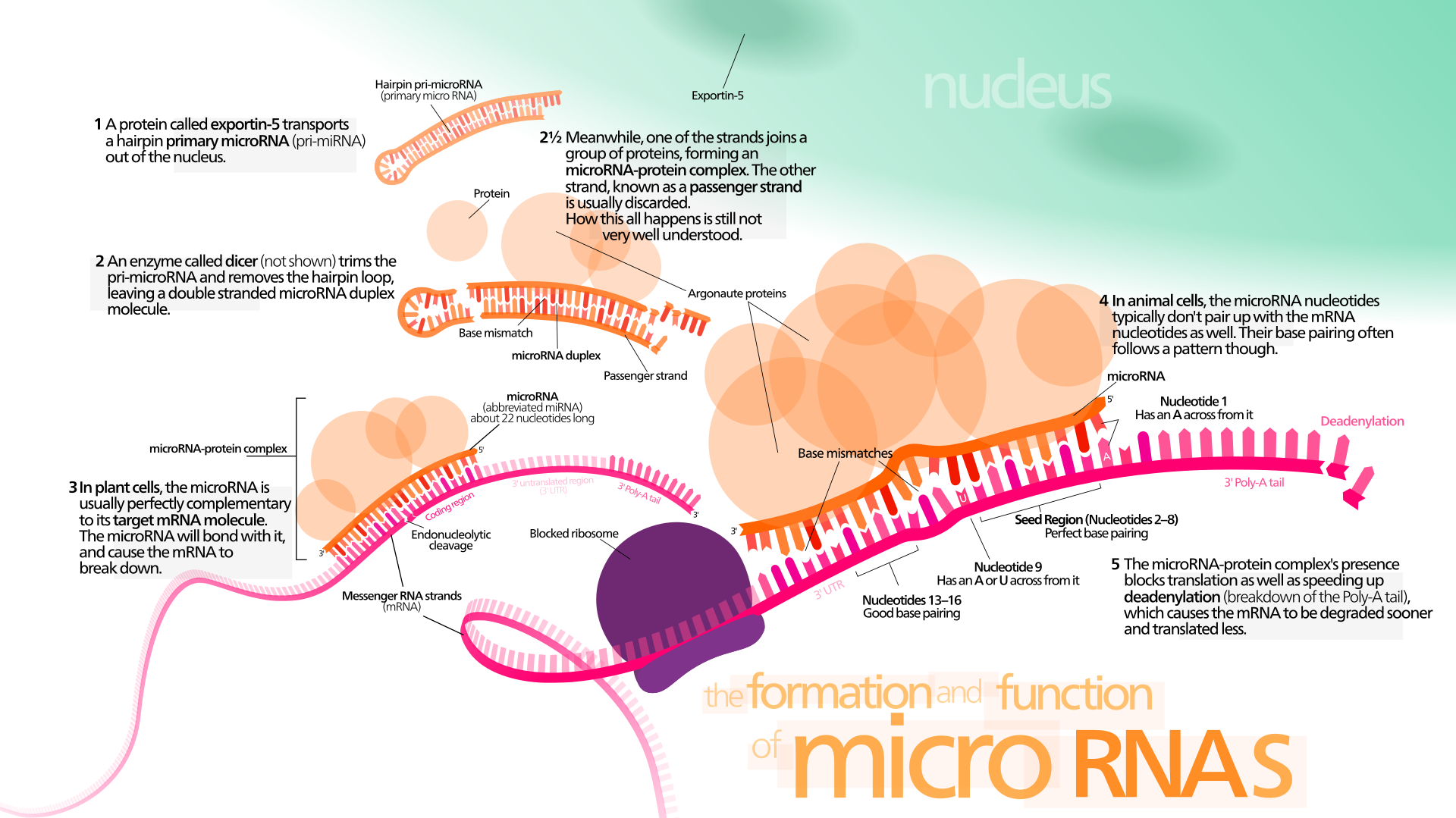
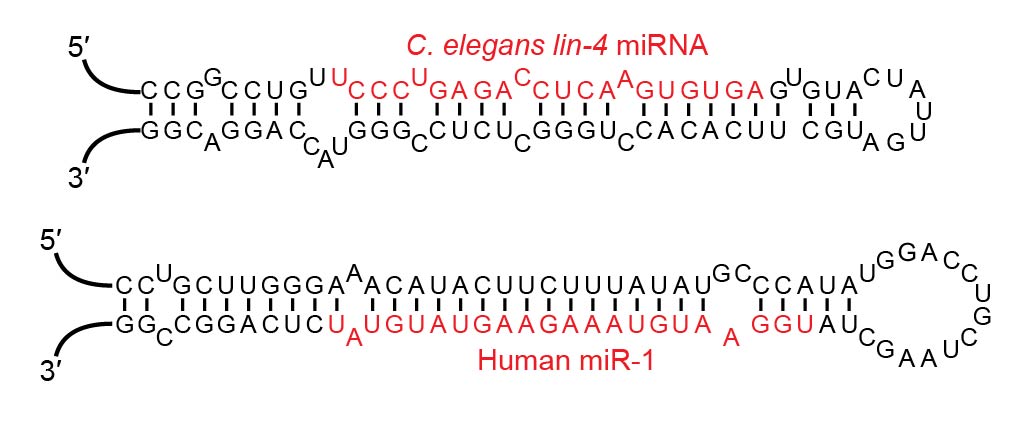
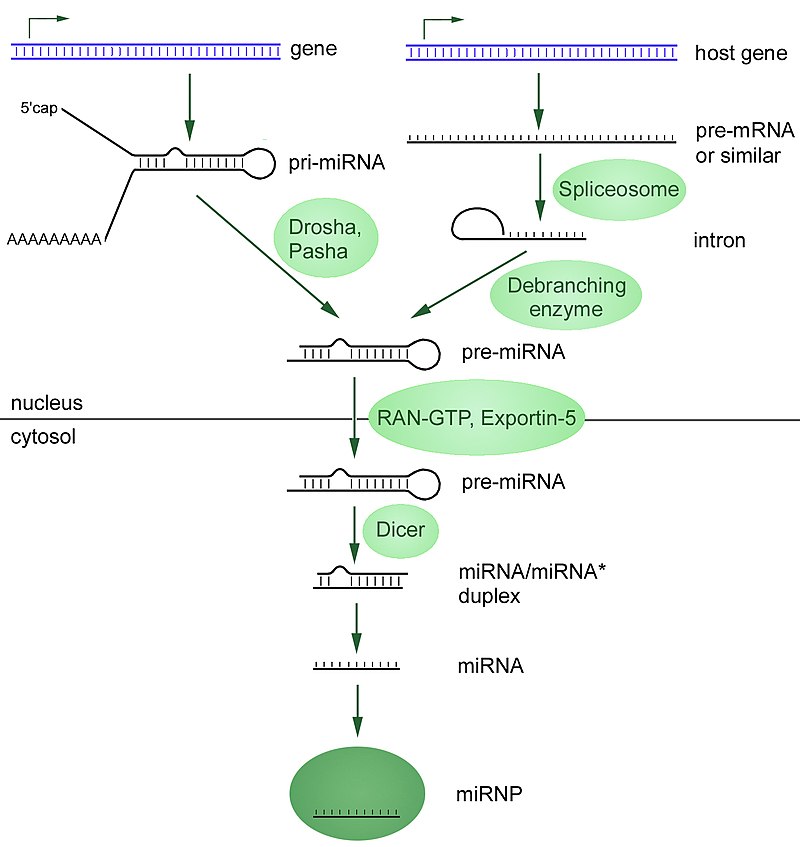
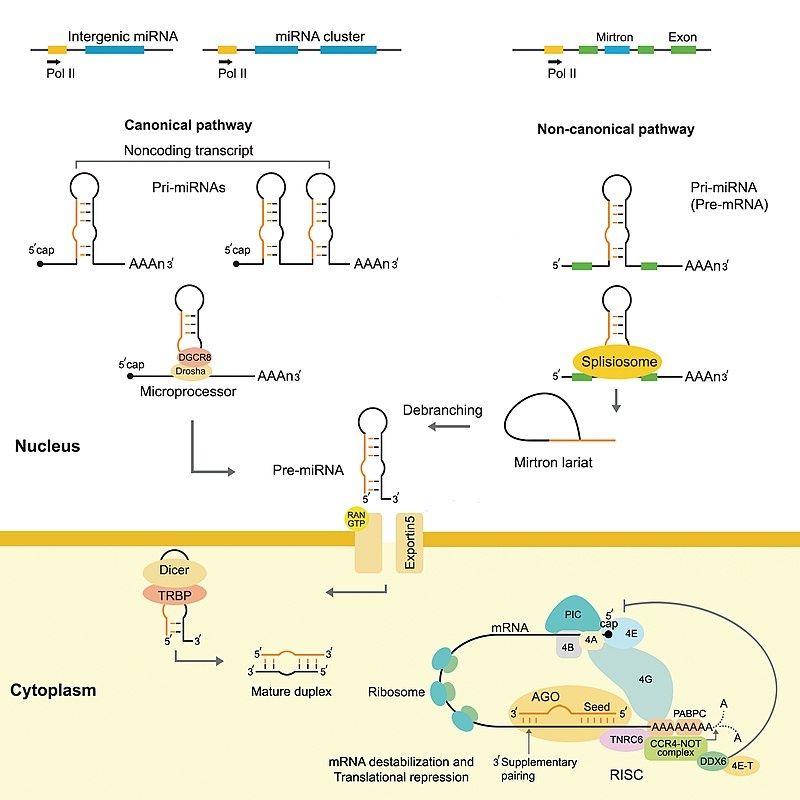
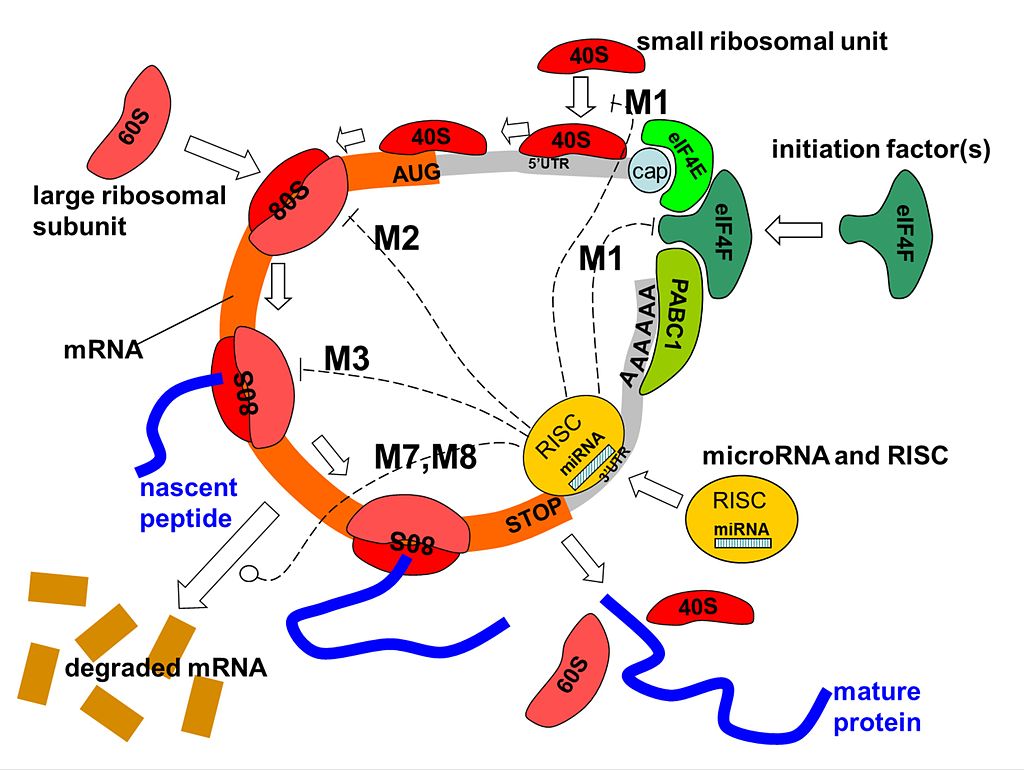
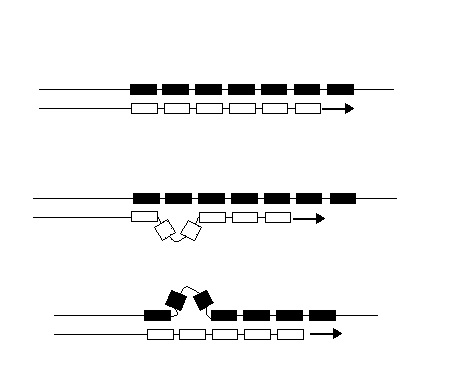

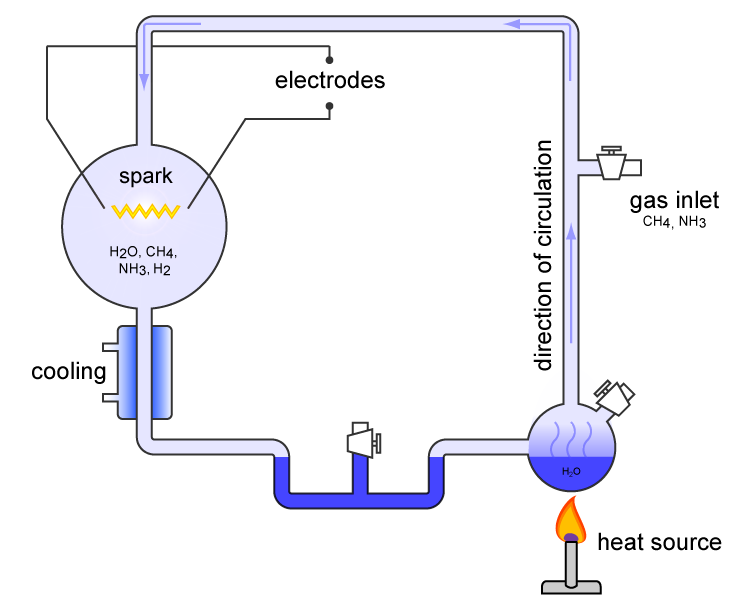
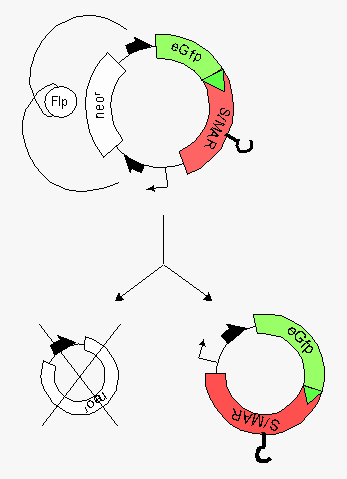
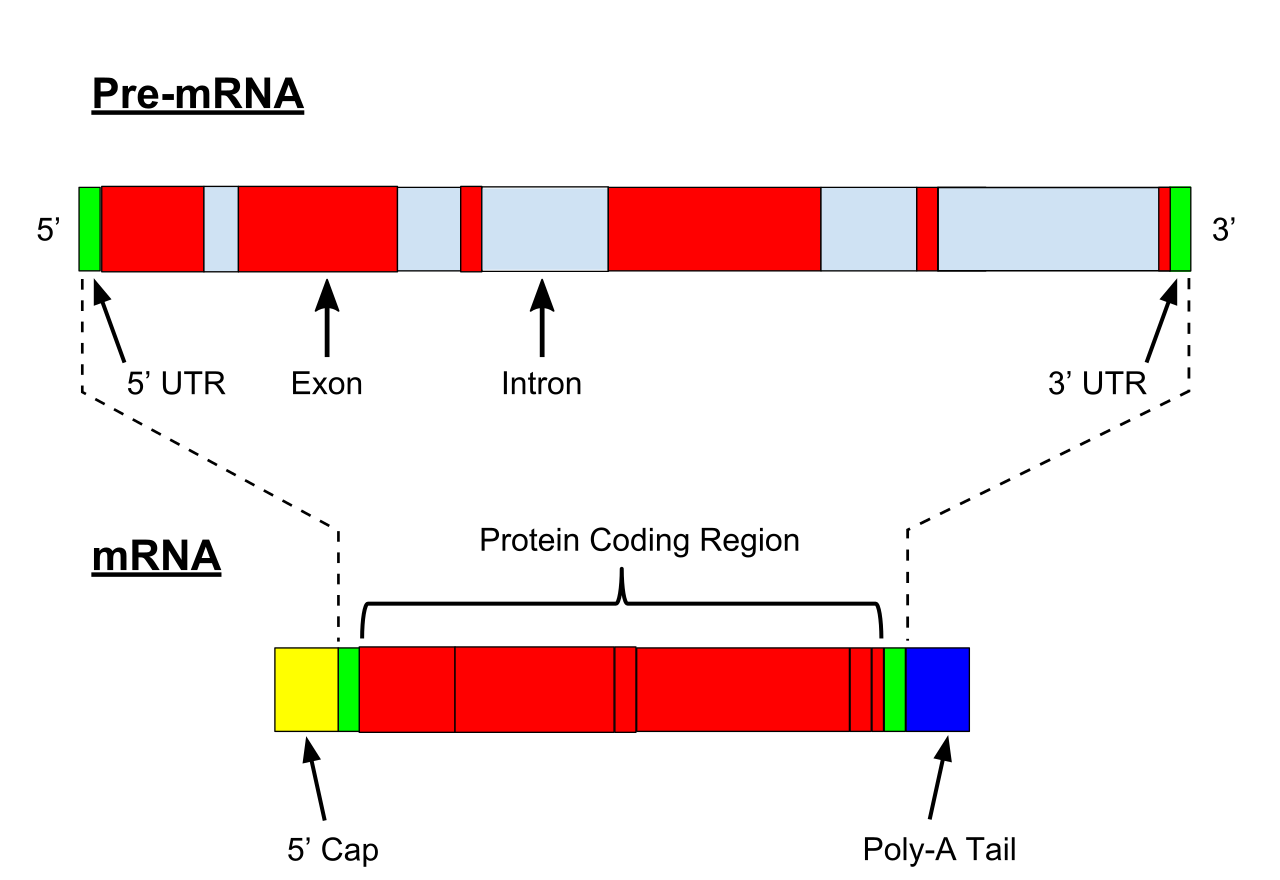
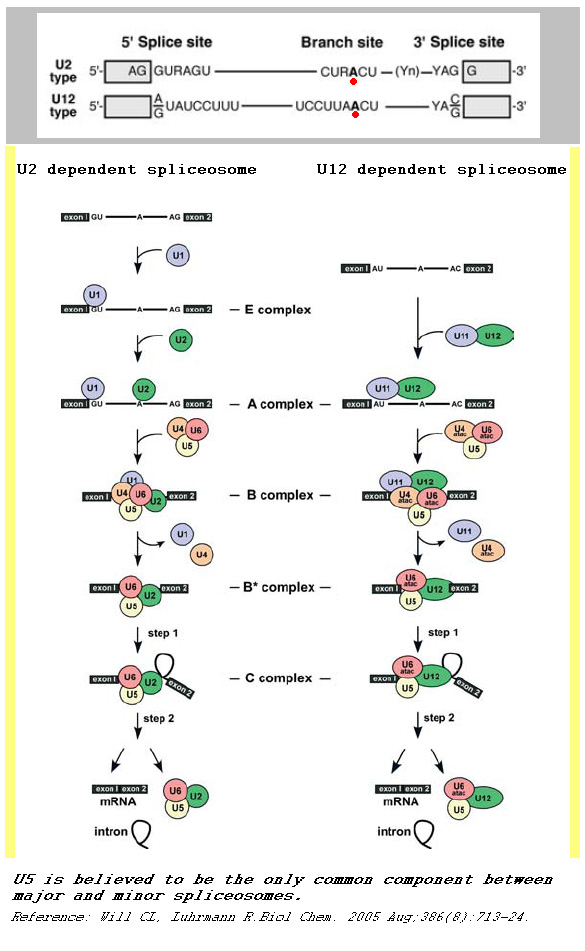
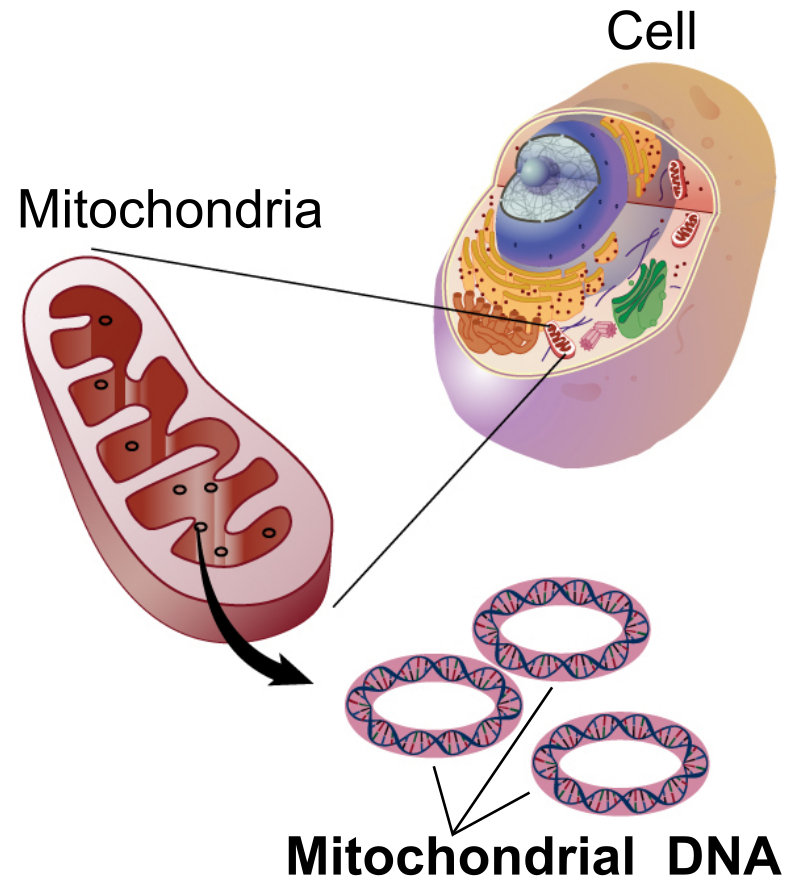
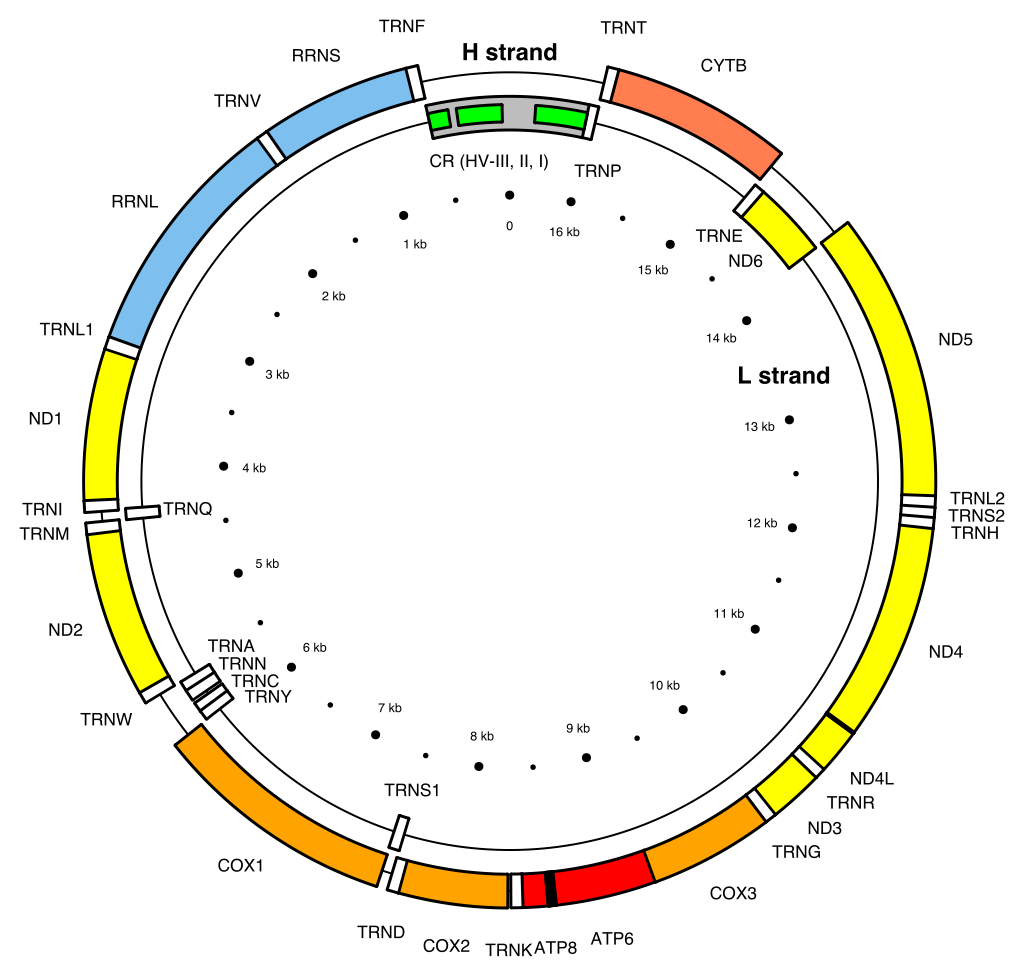
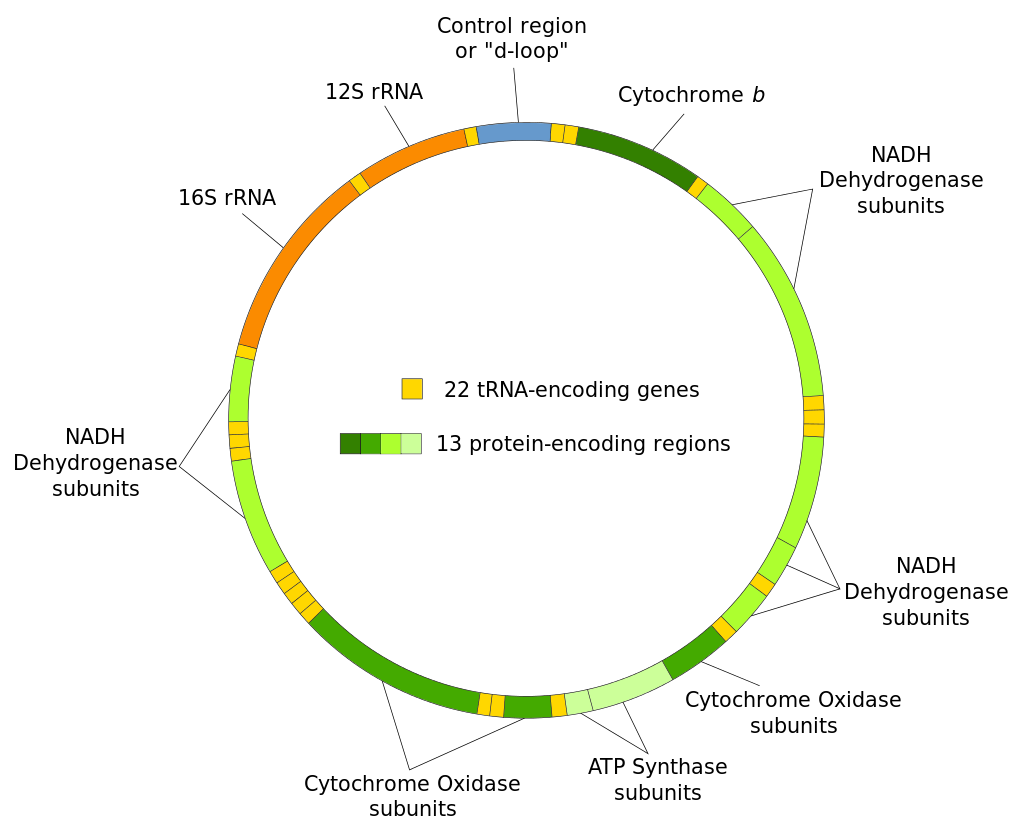
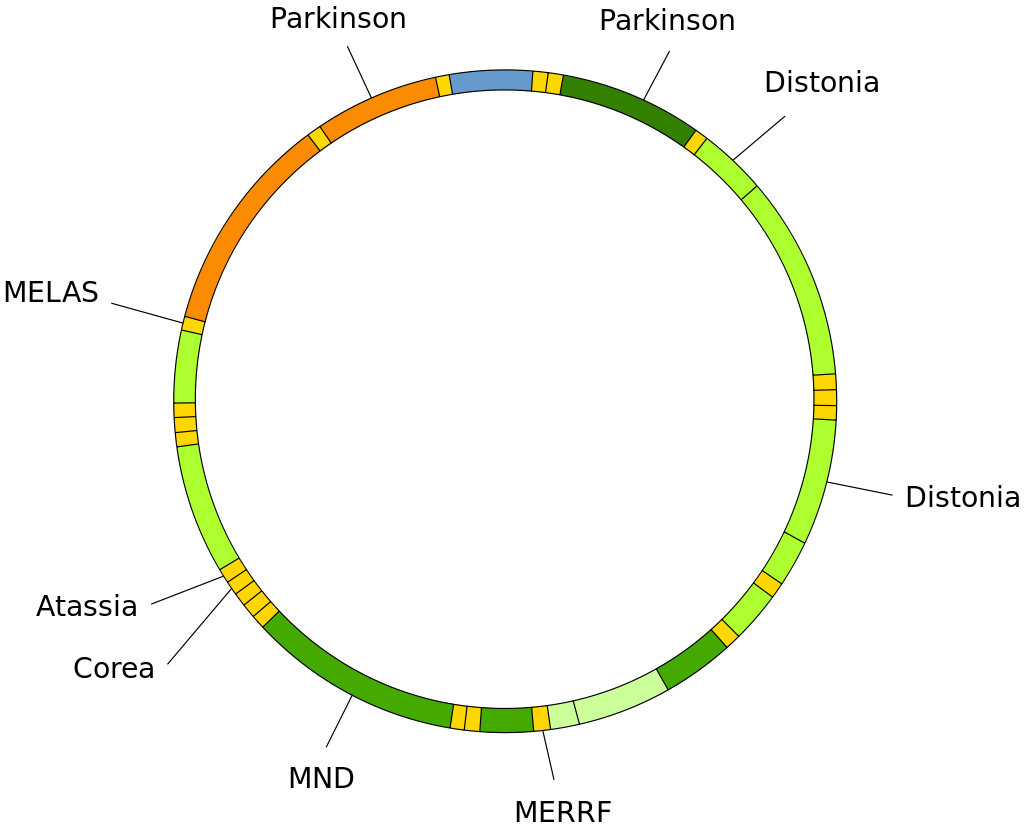

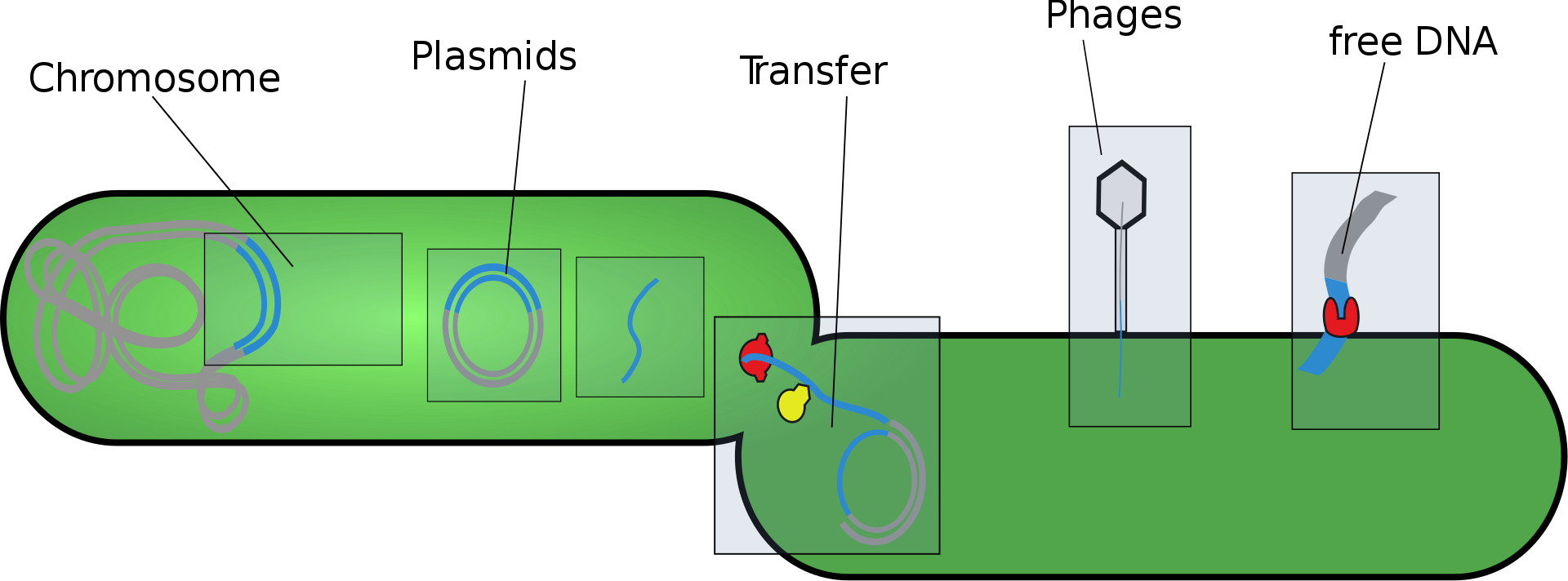
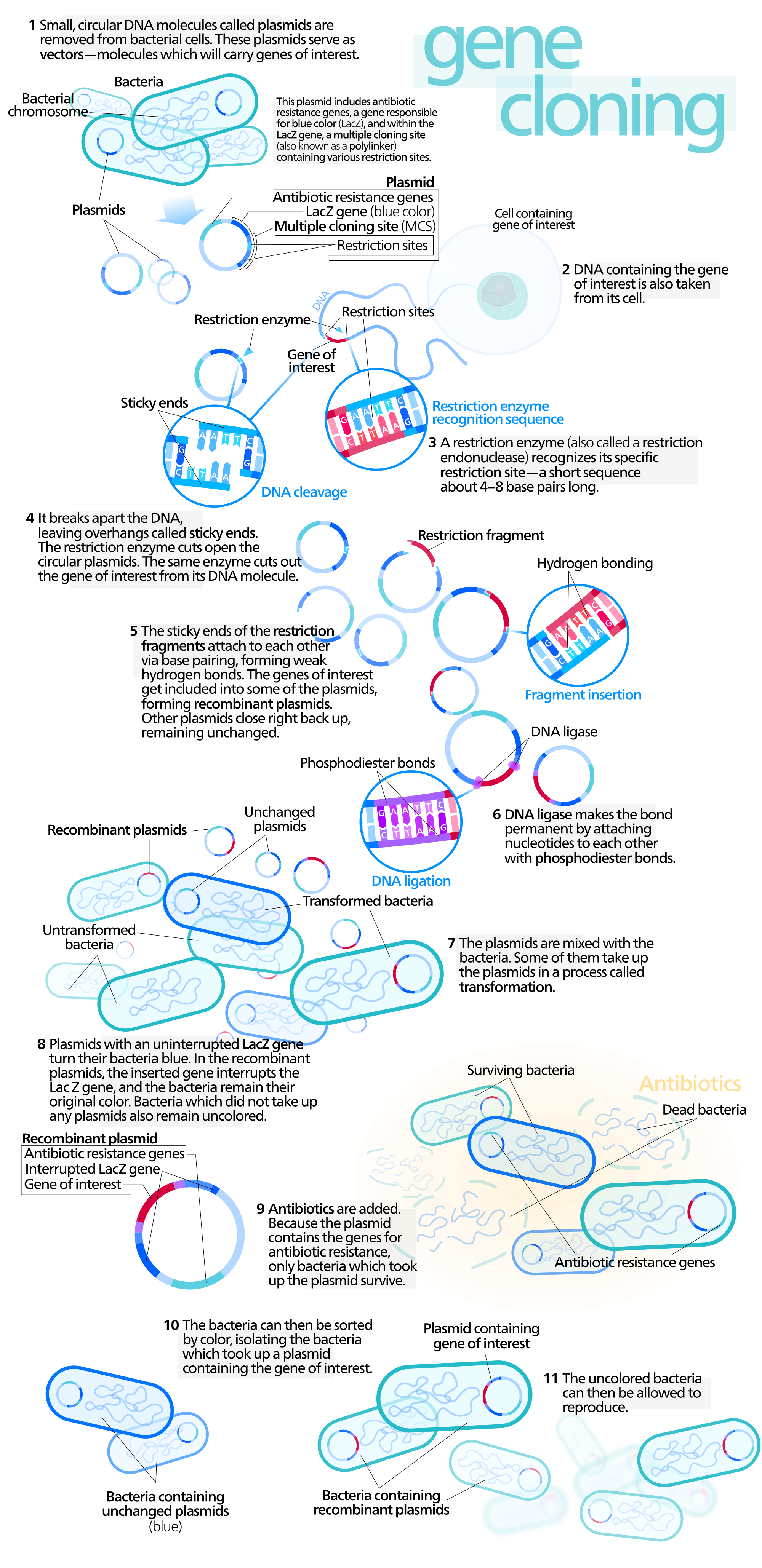
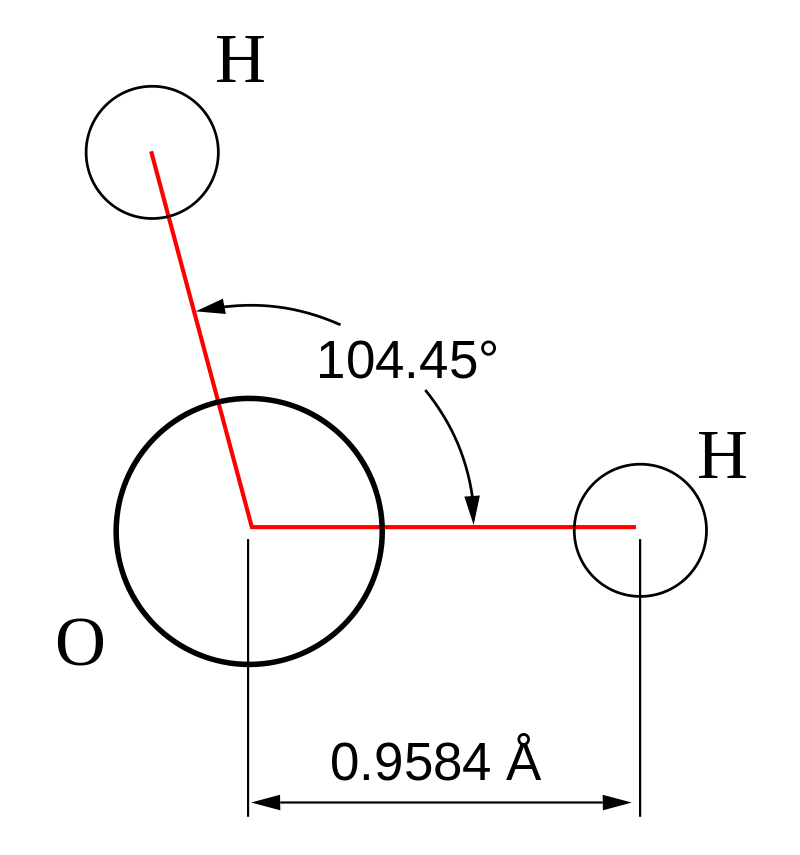


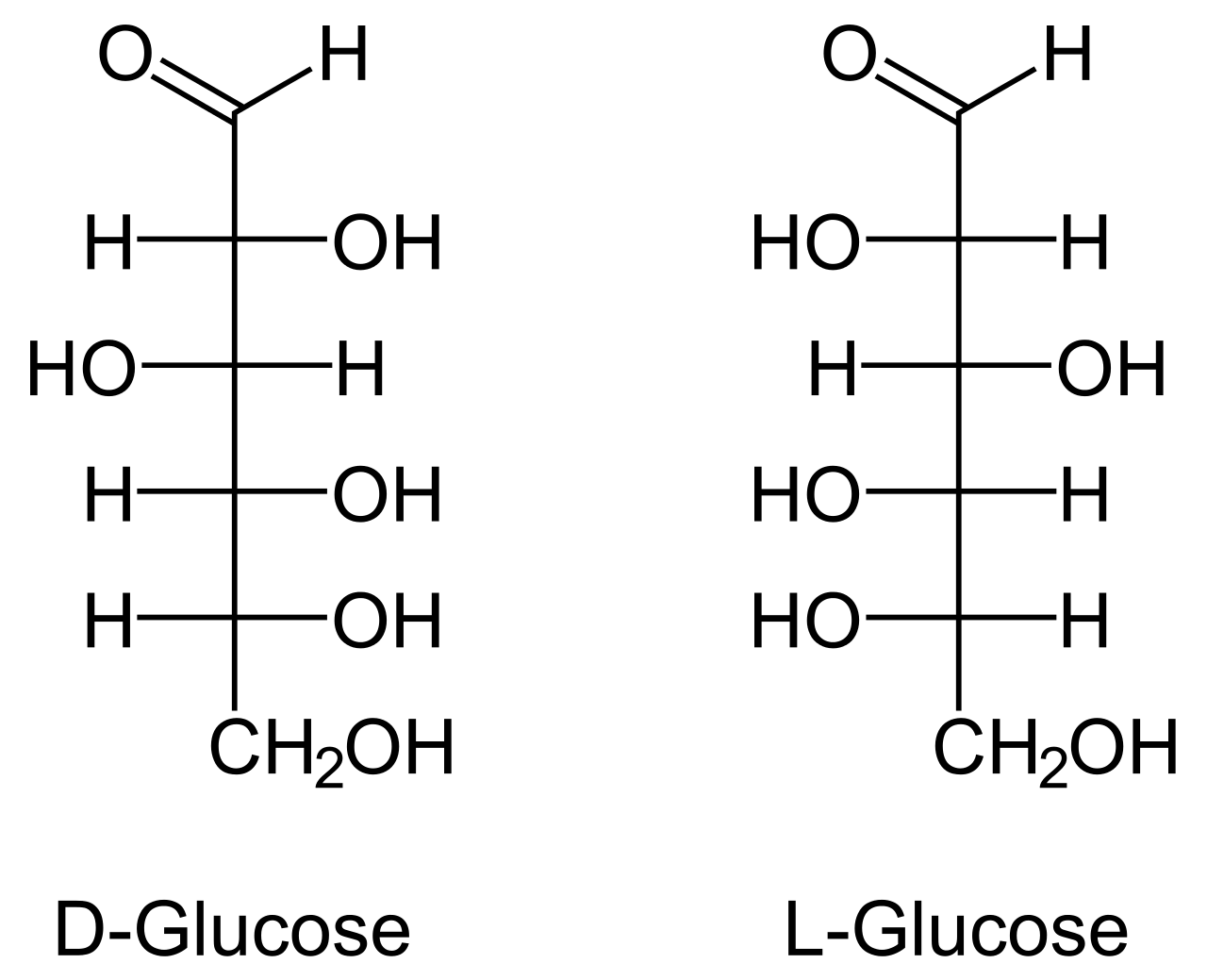
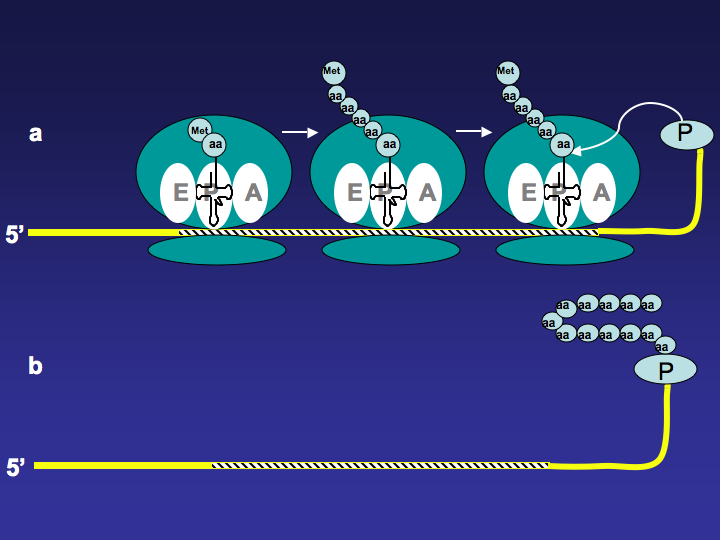
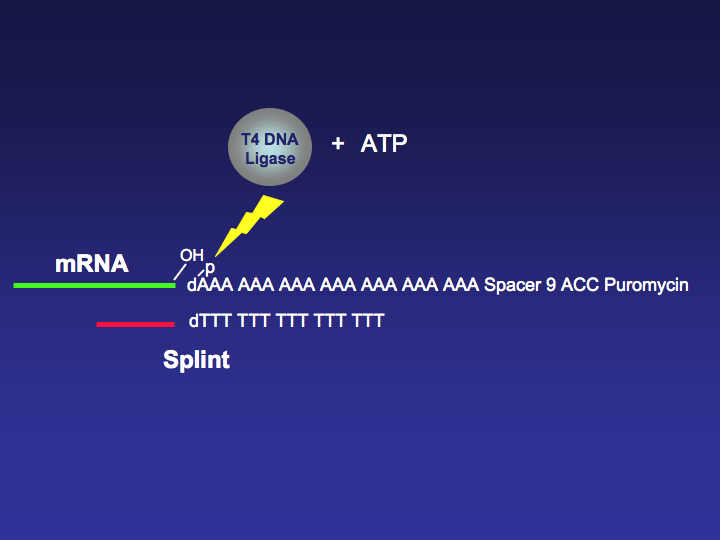
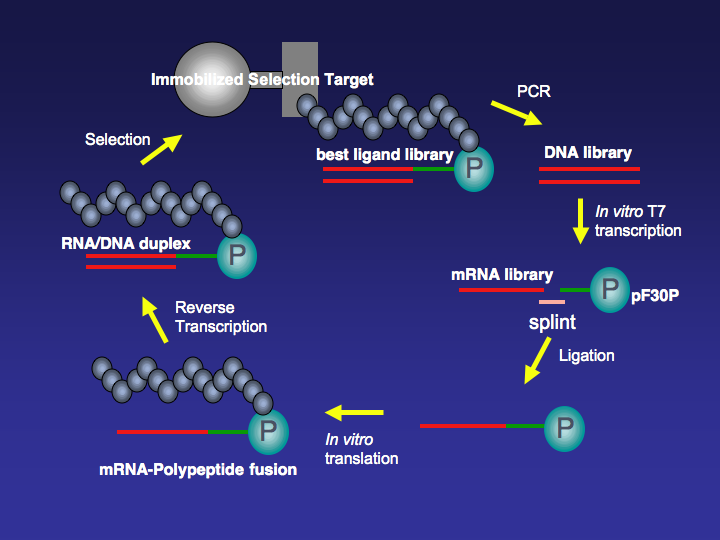
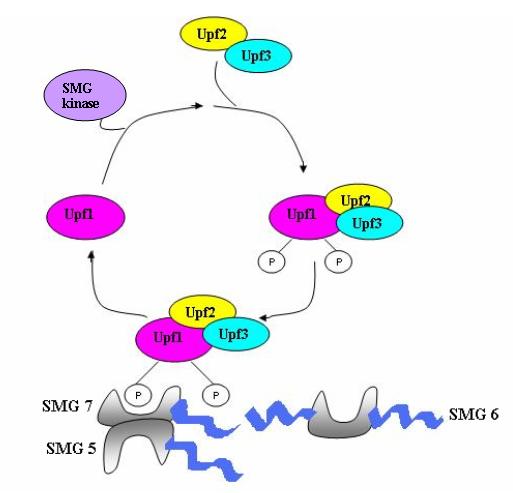
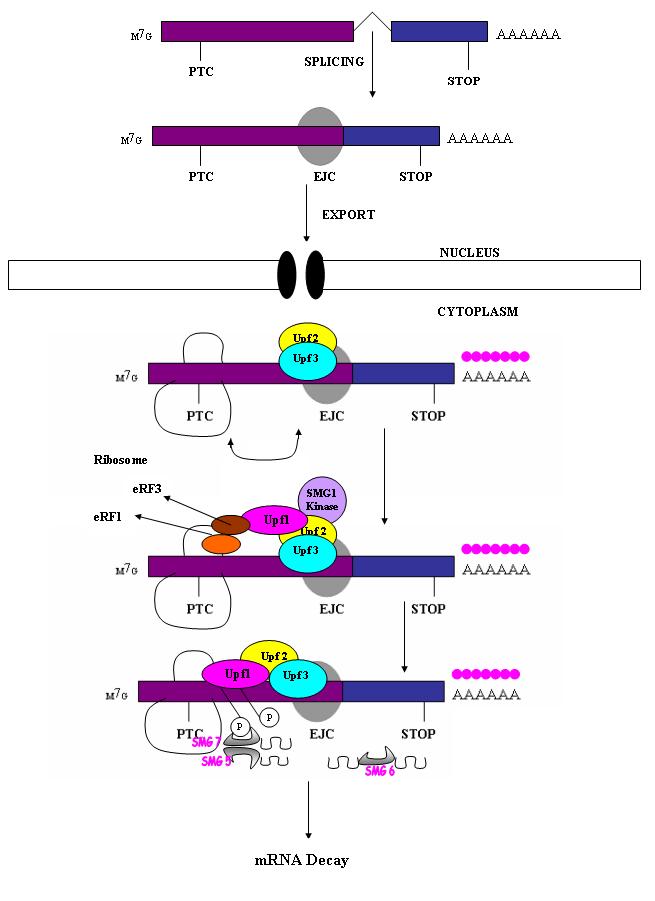
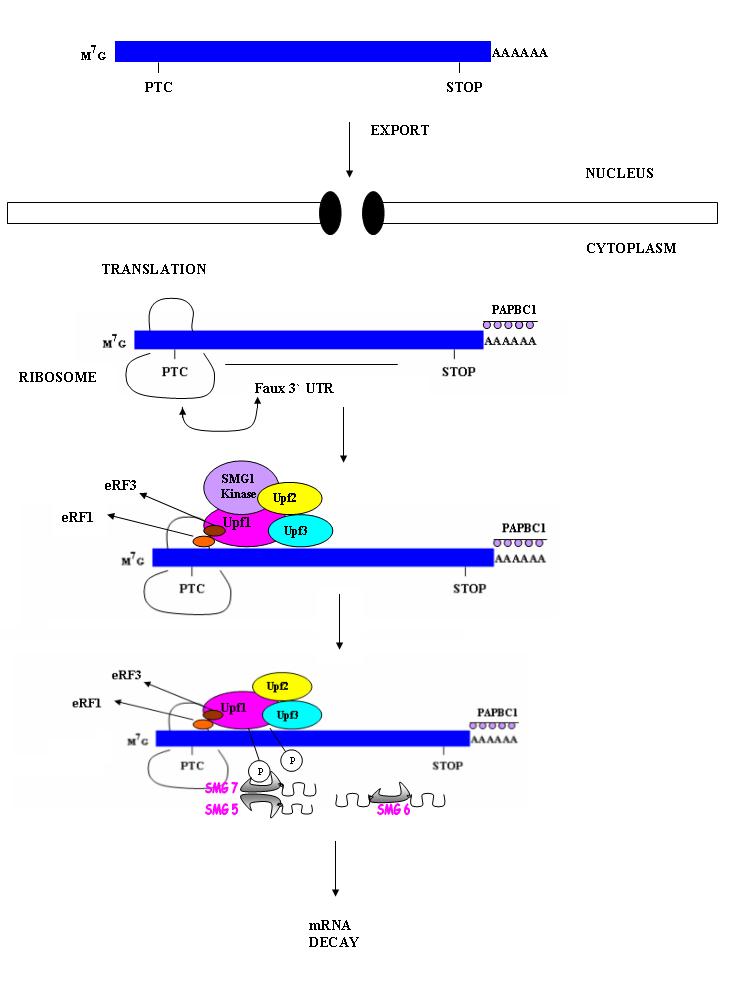
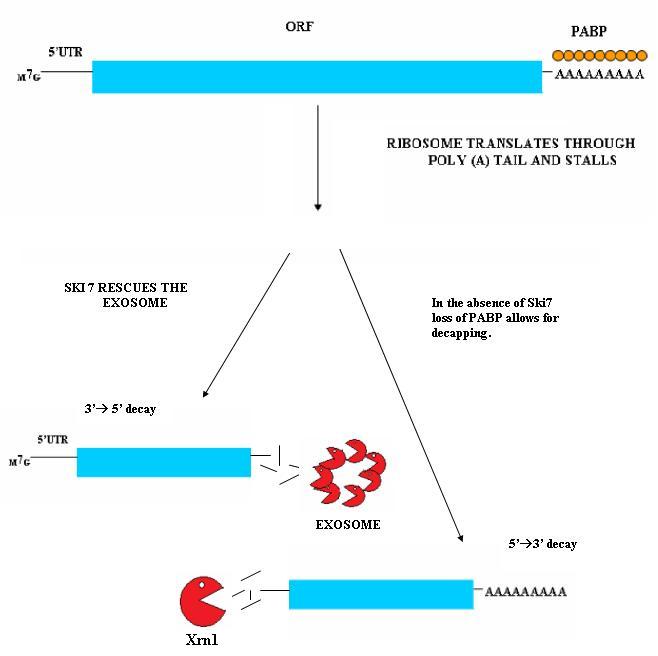
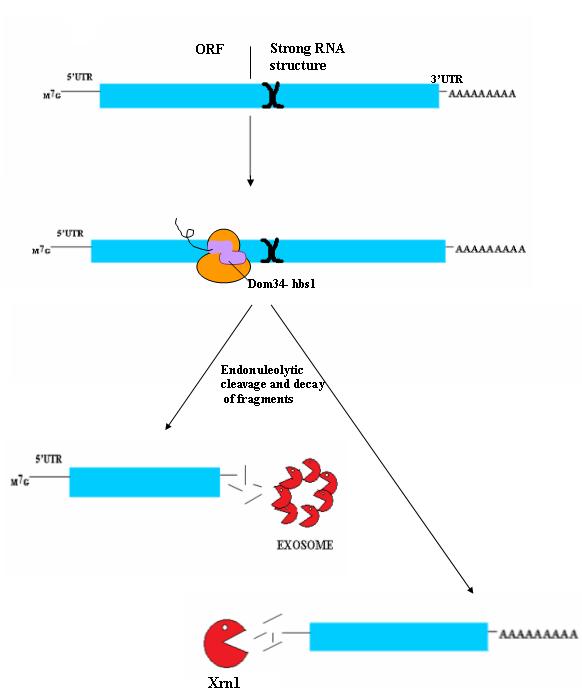
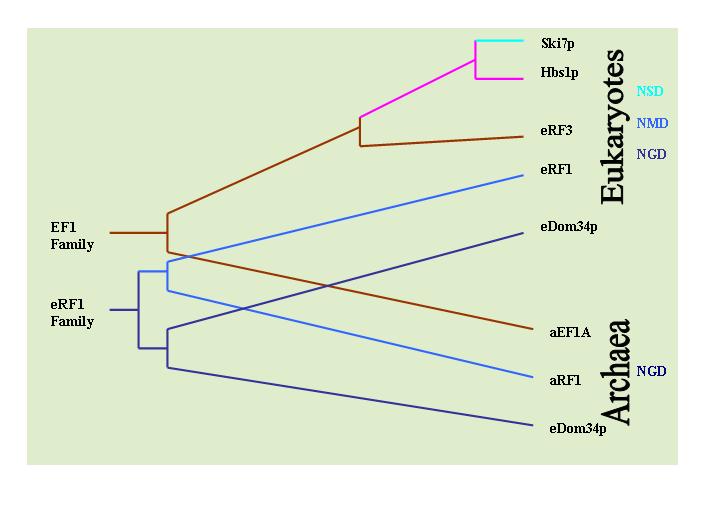
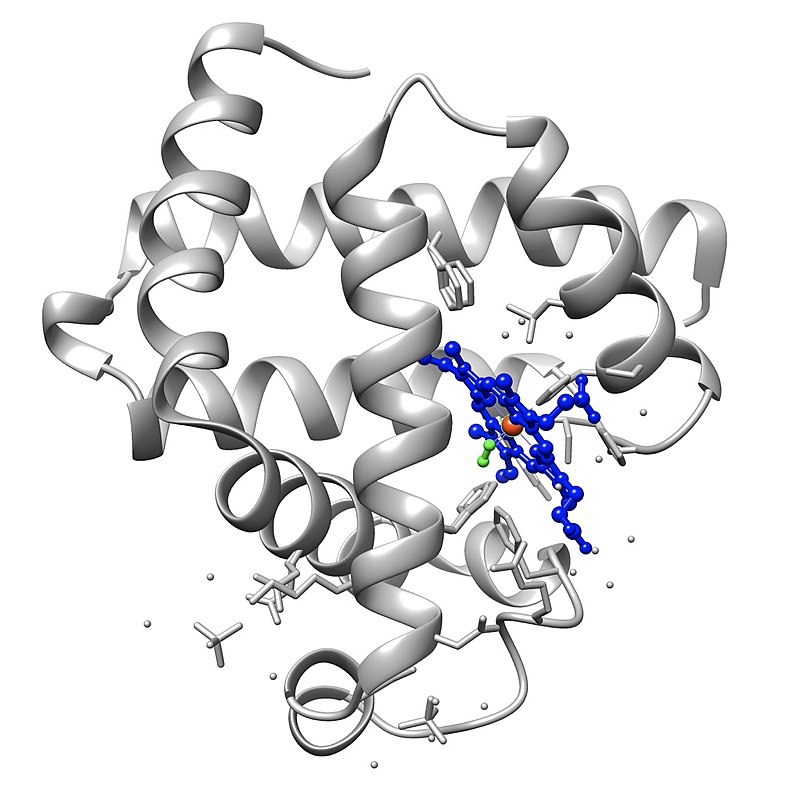
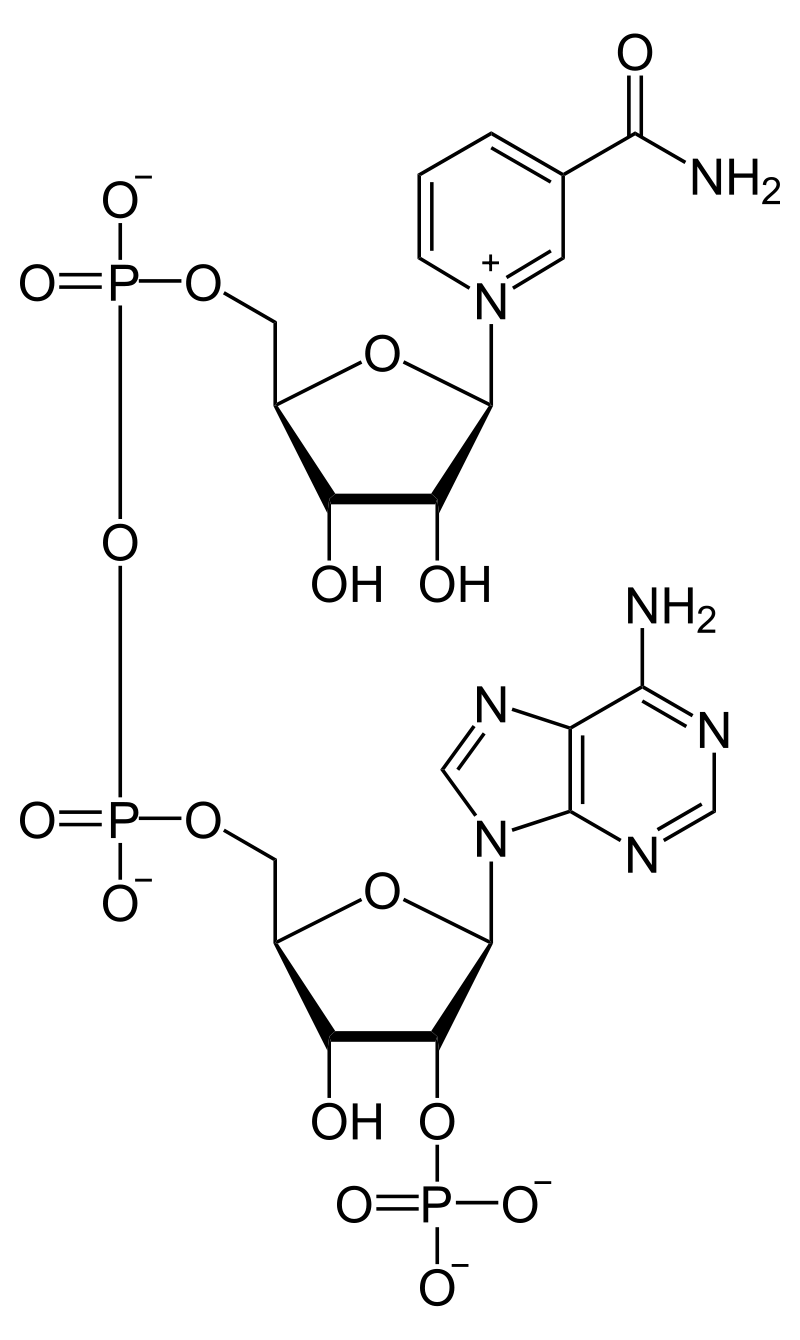
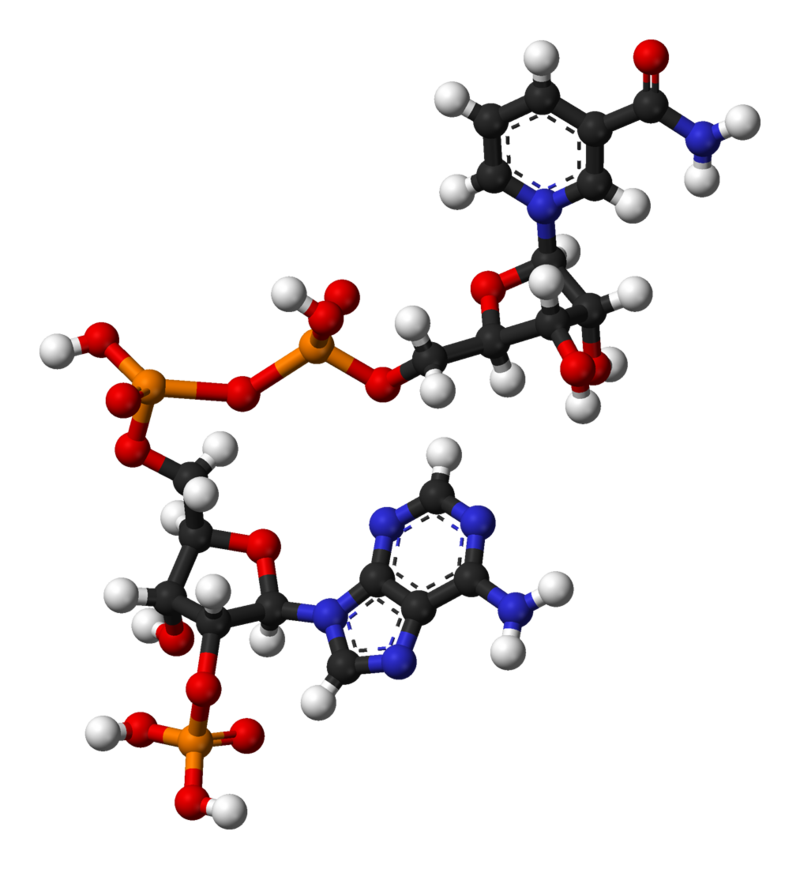
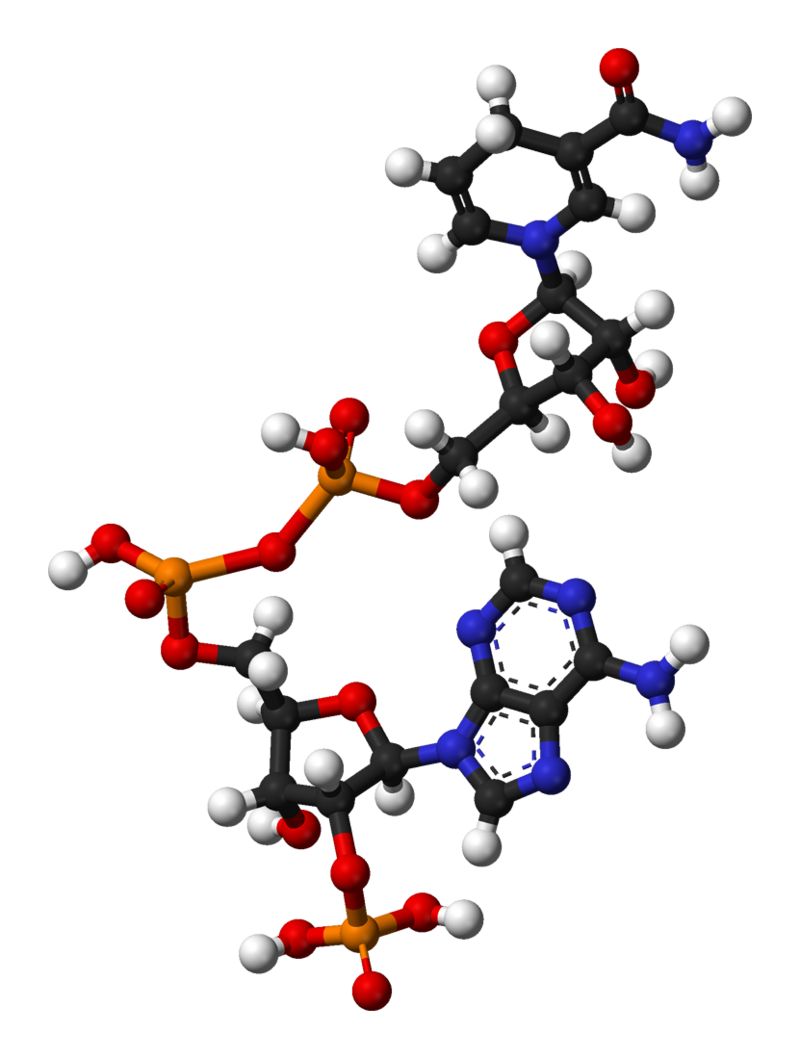
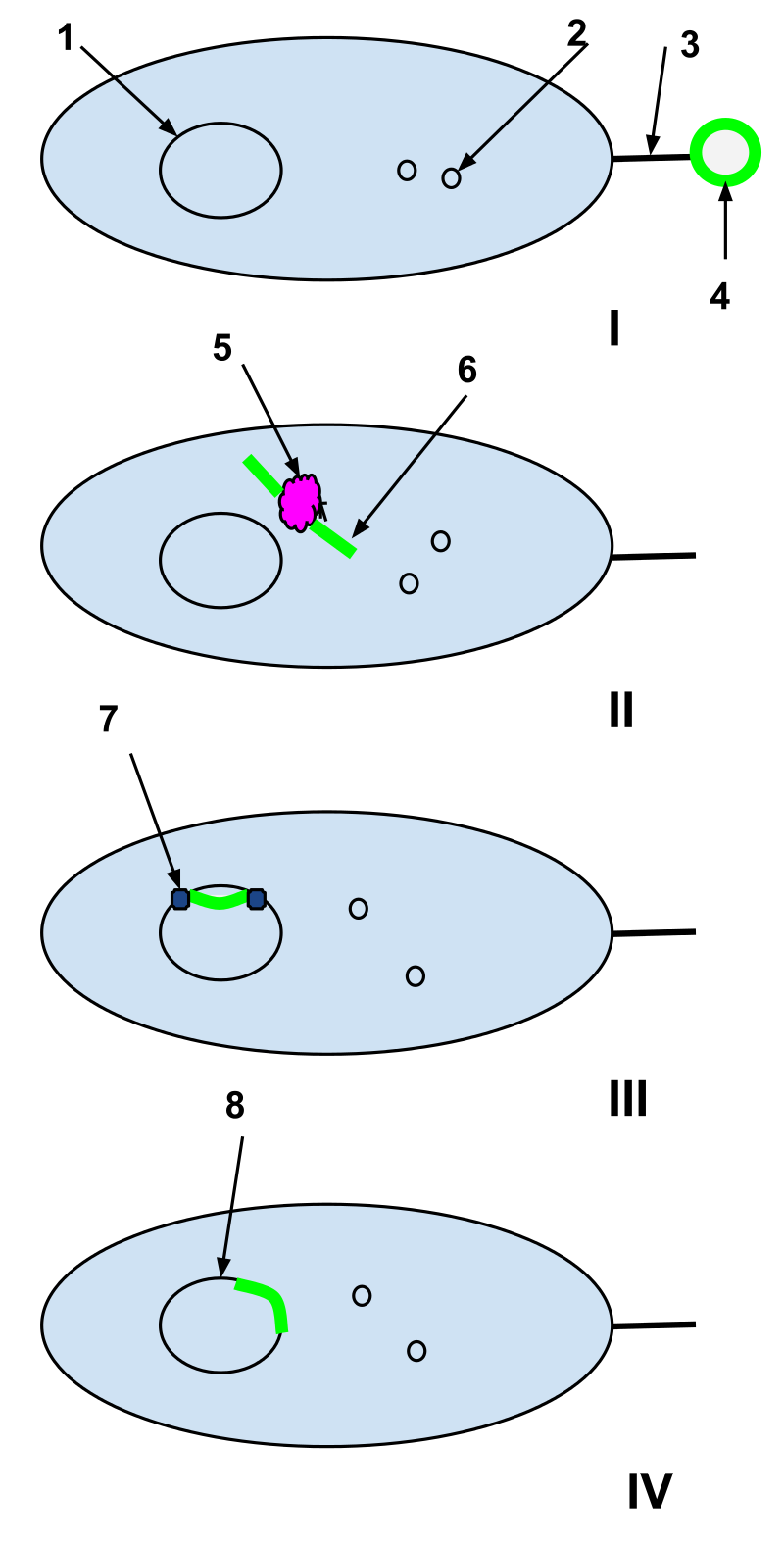
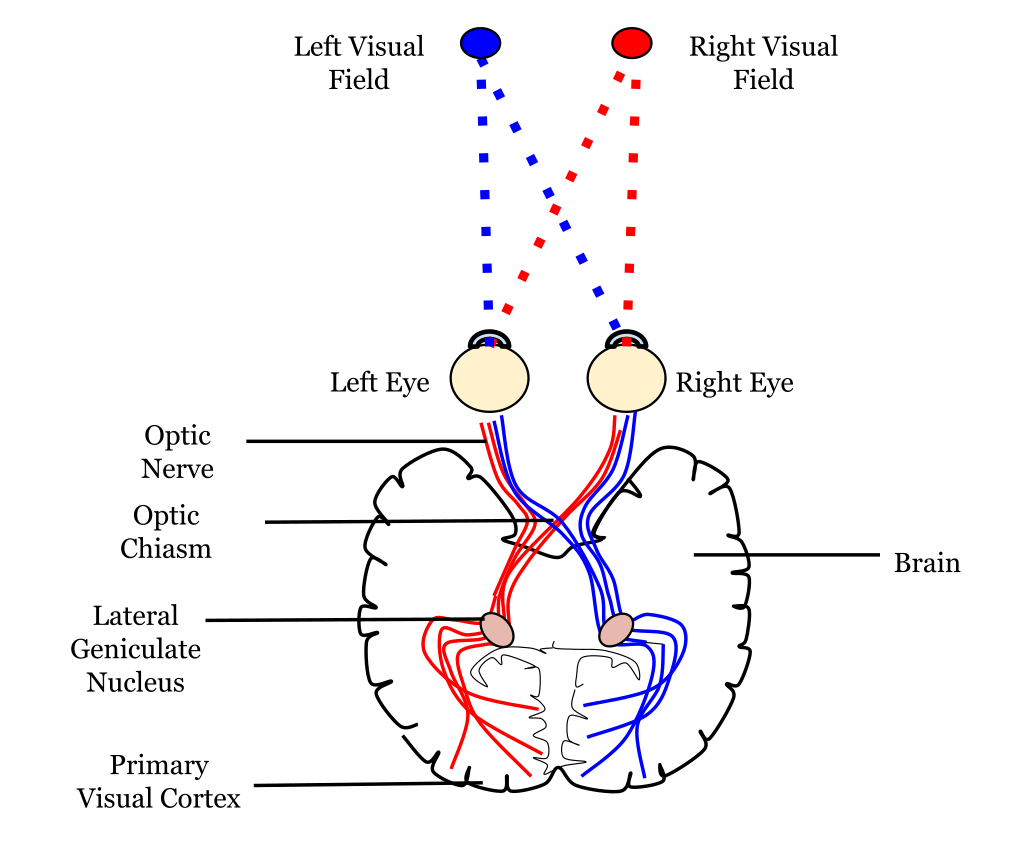
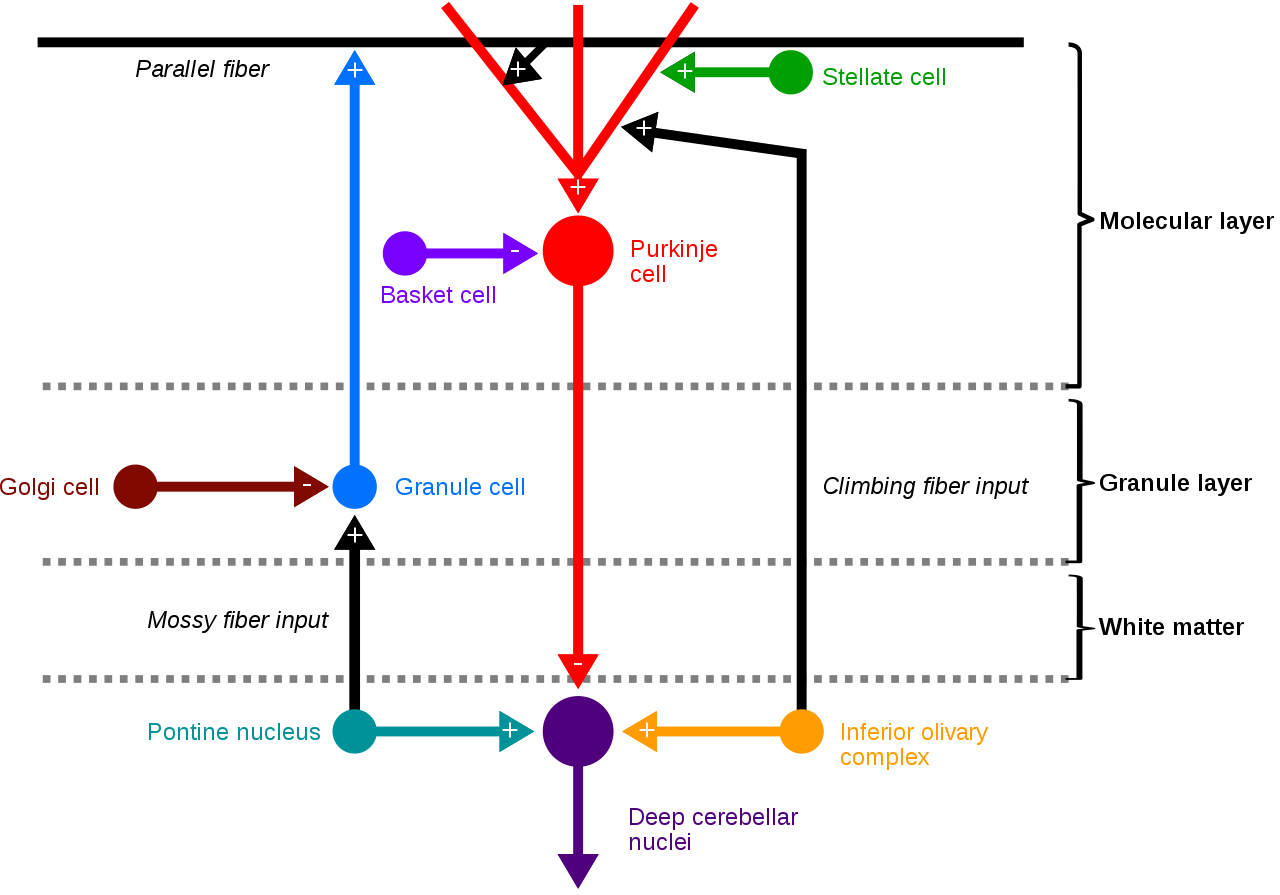
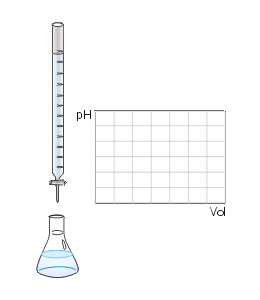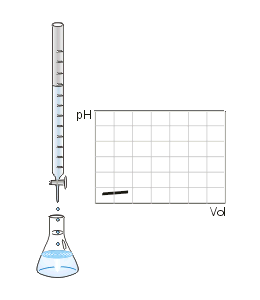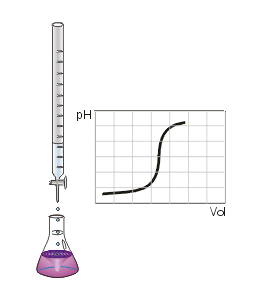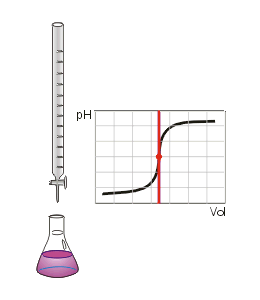
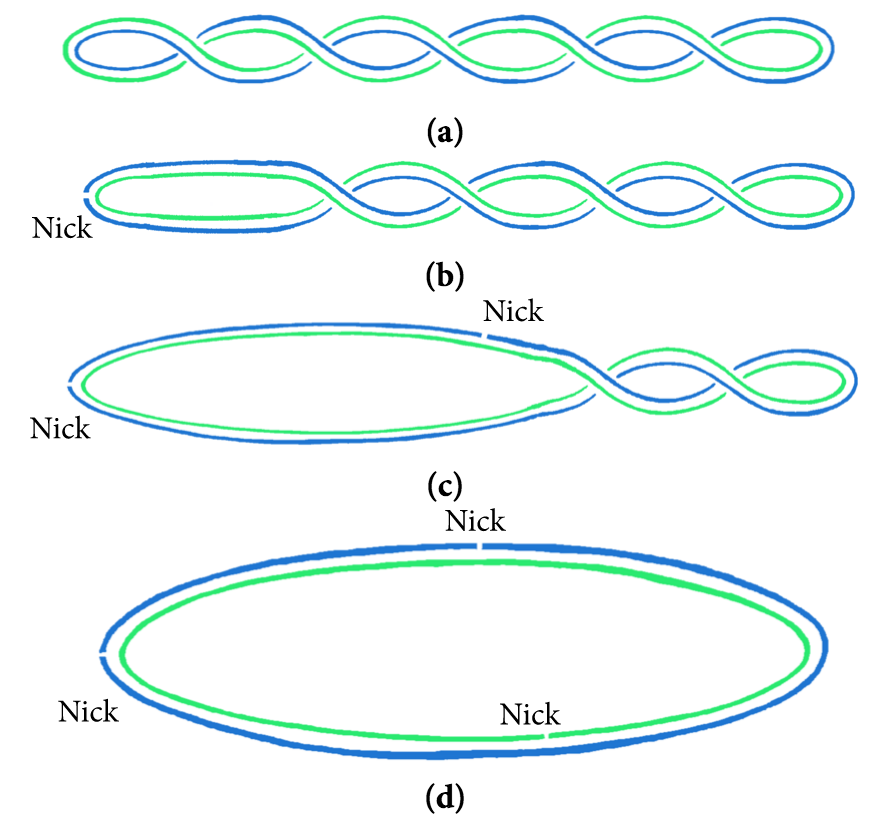
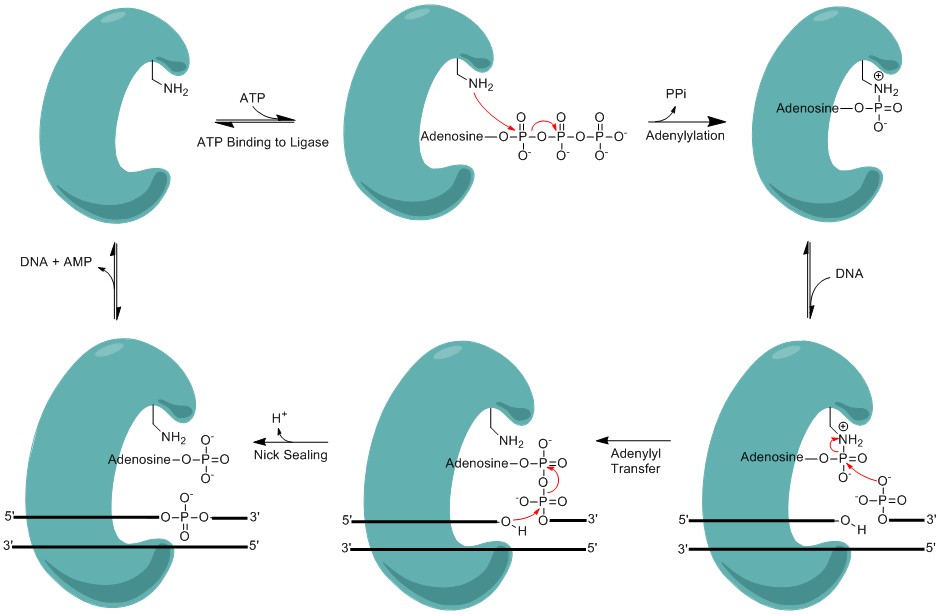
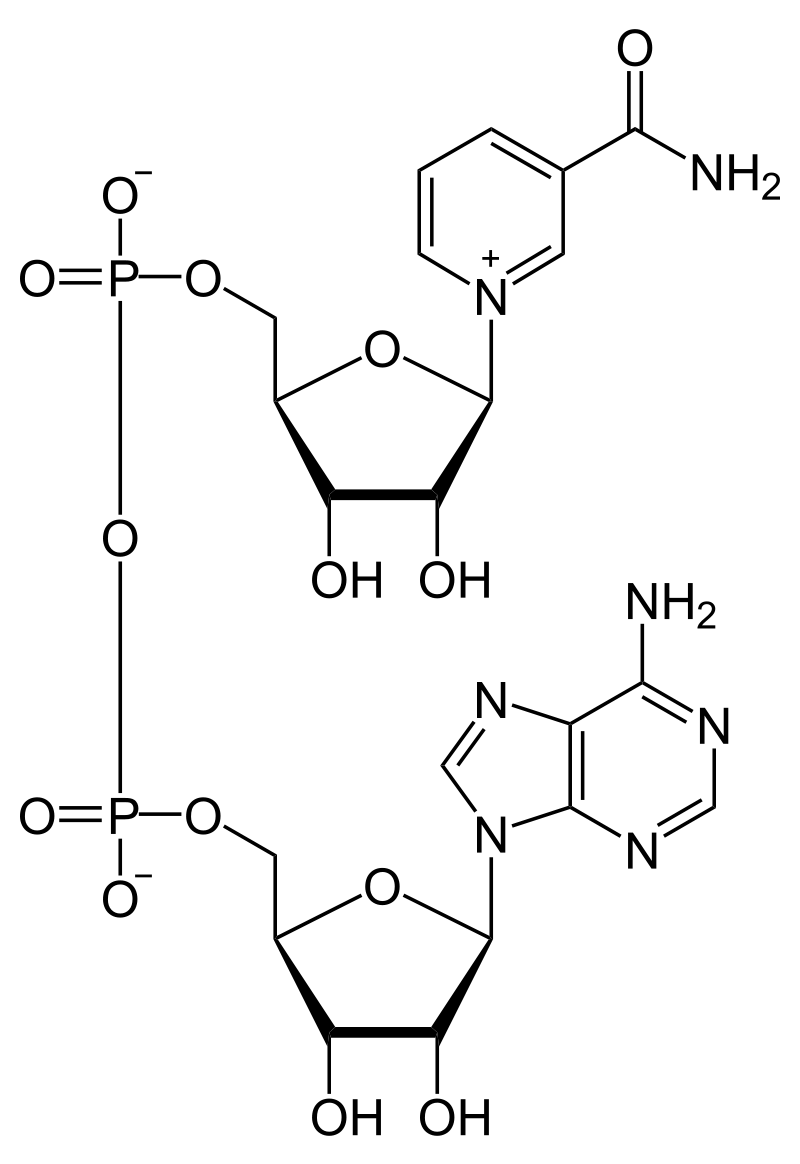
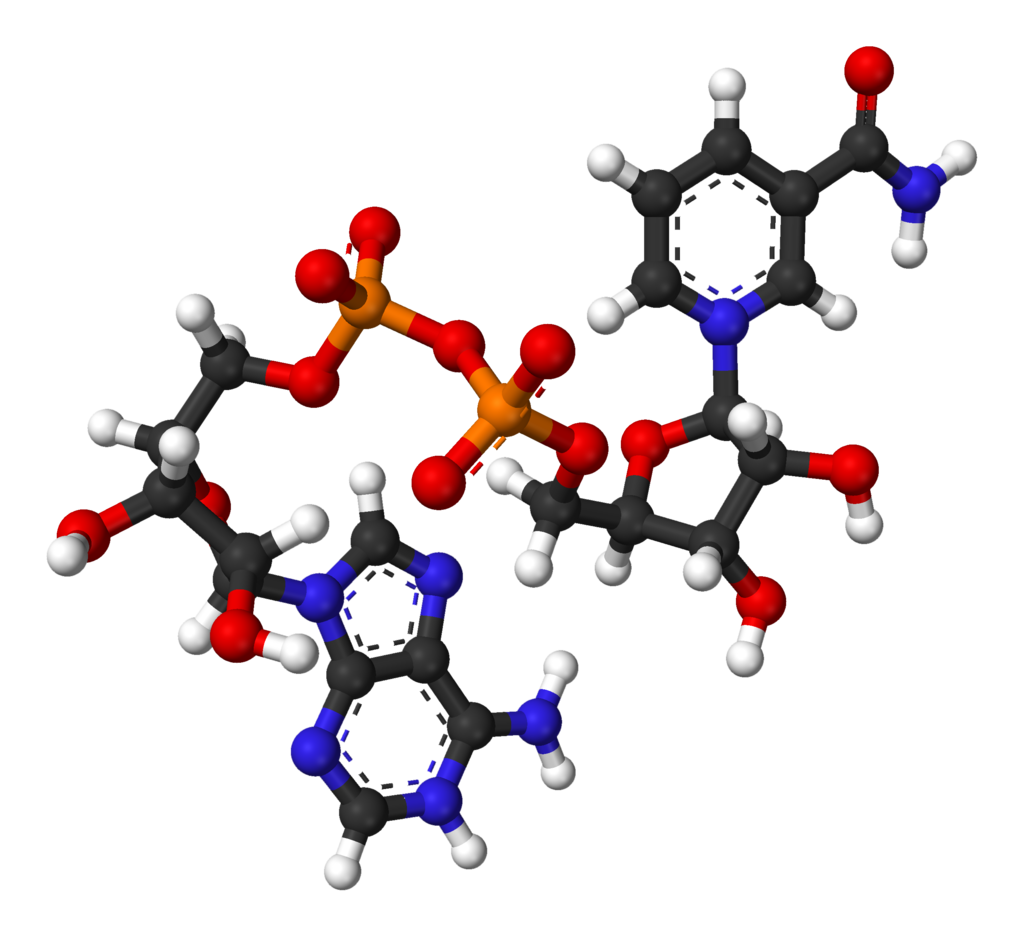
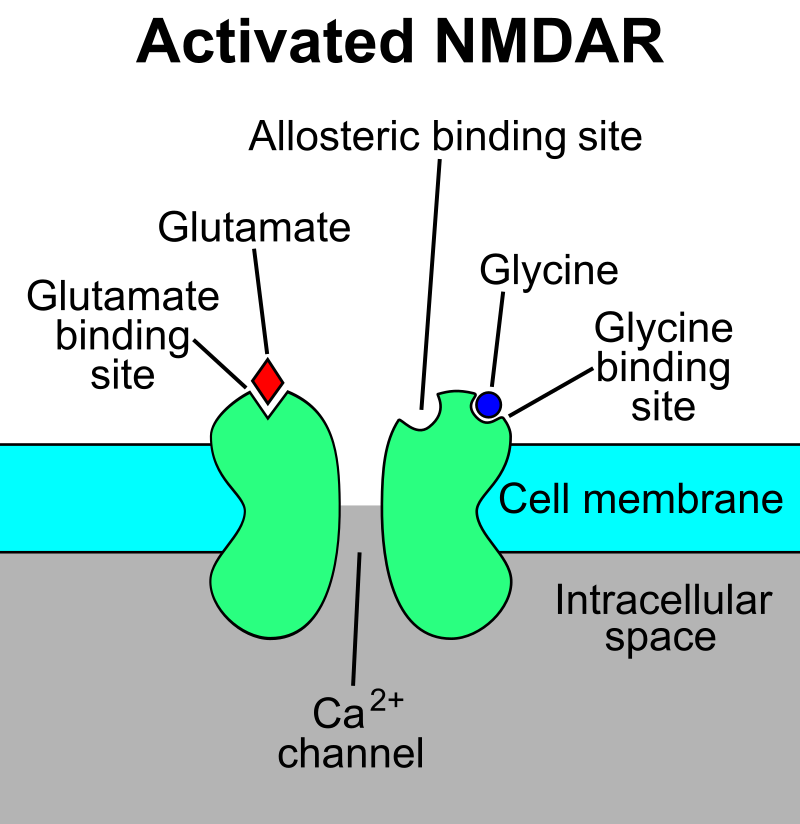
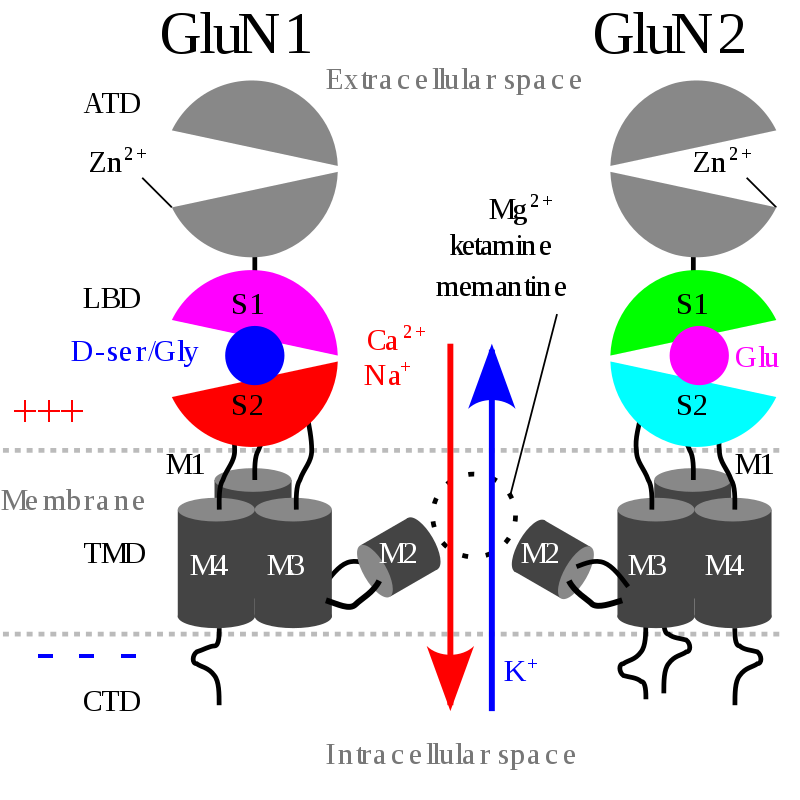
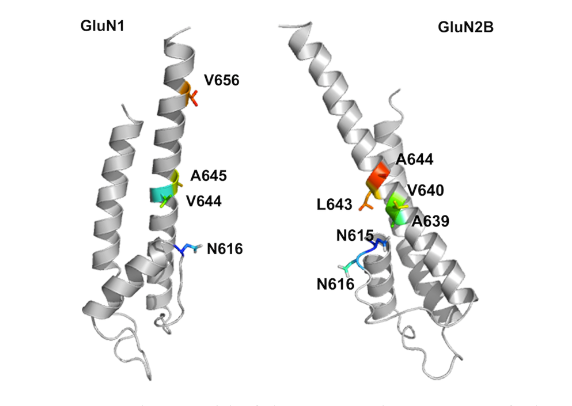
.jpg)
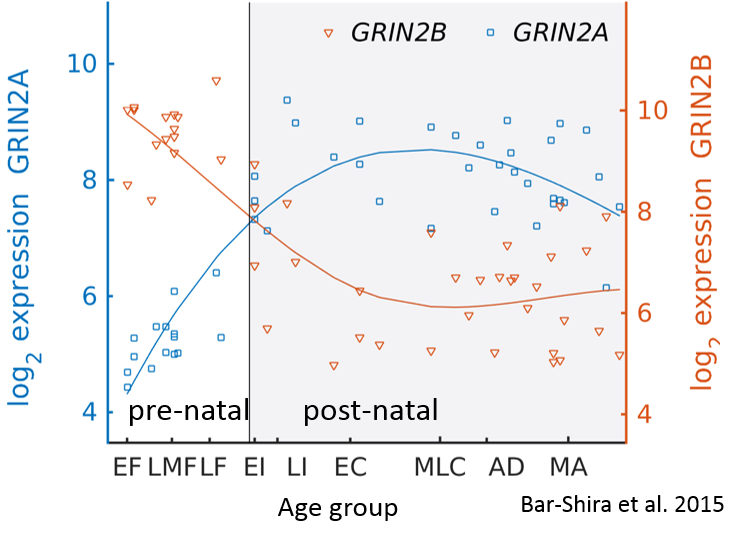
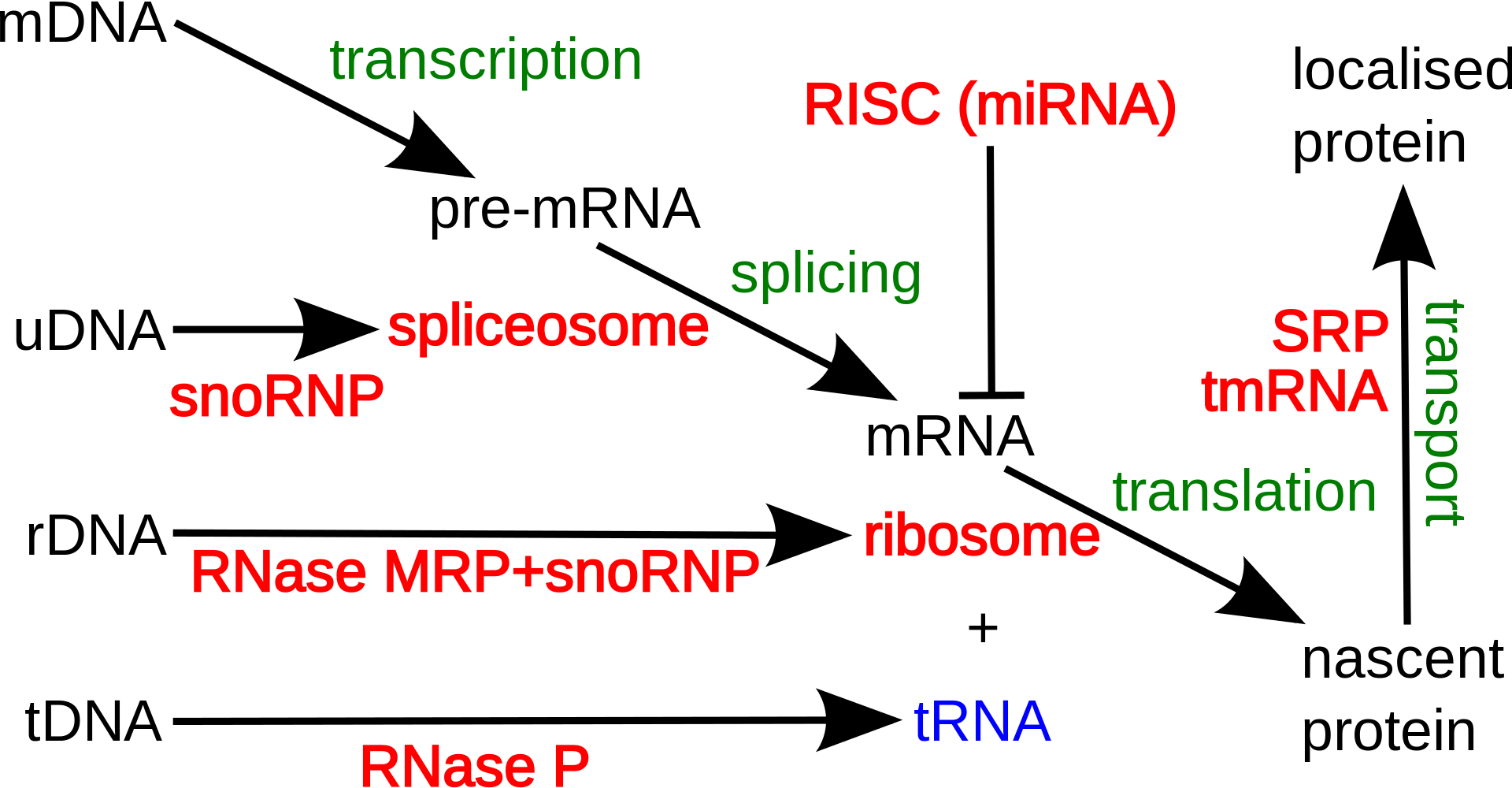
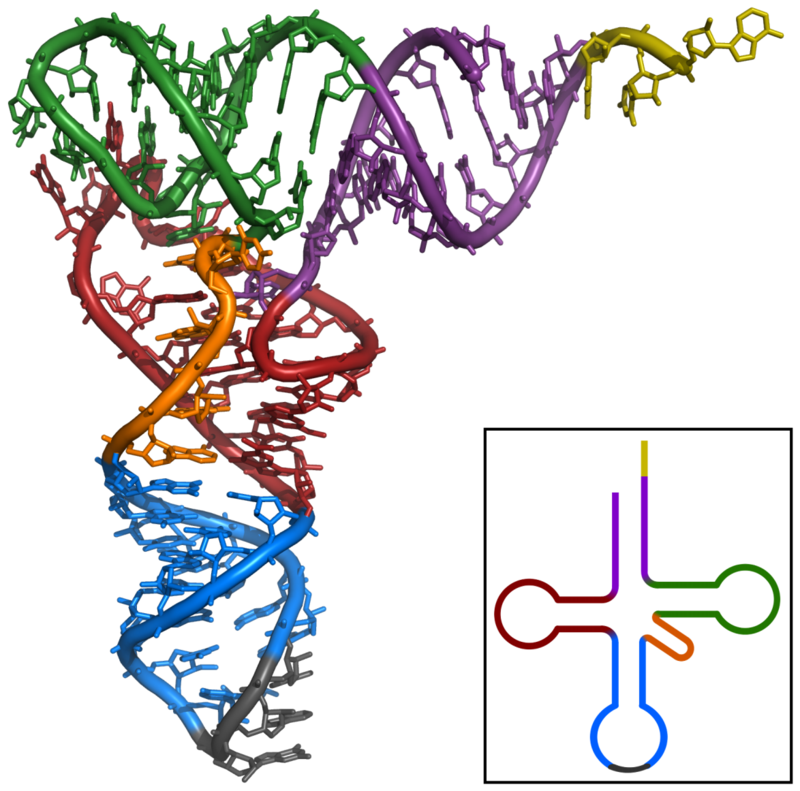
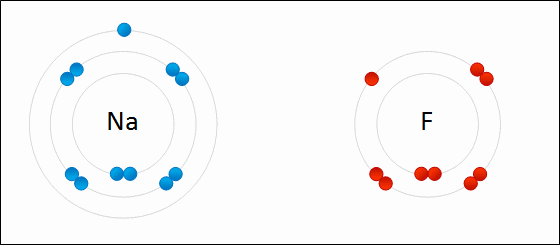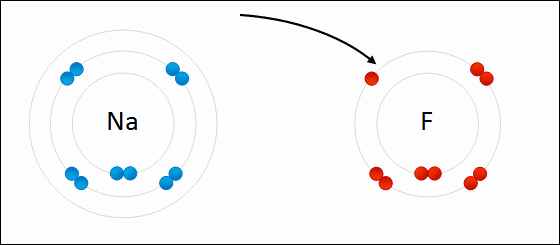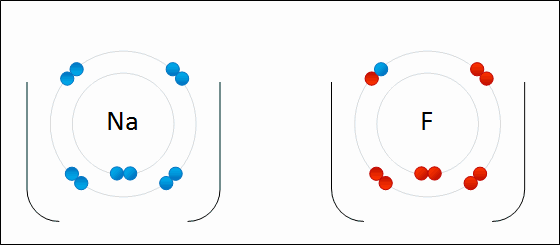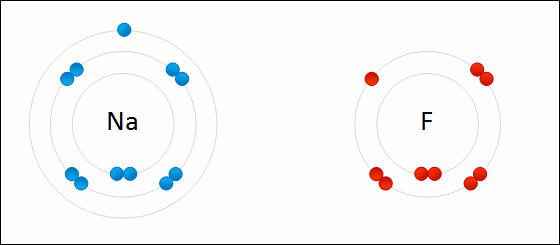
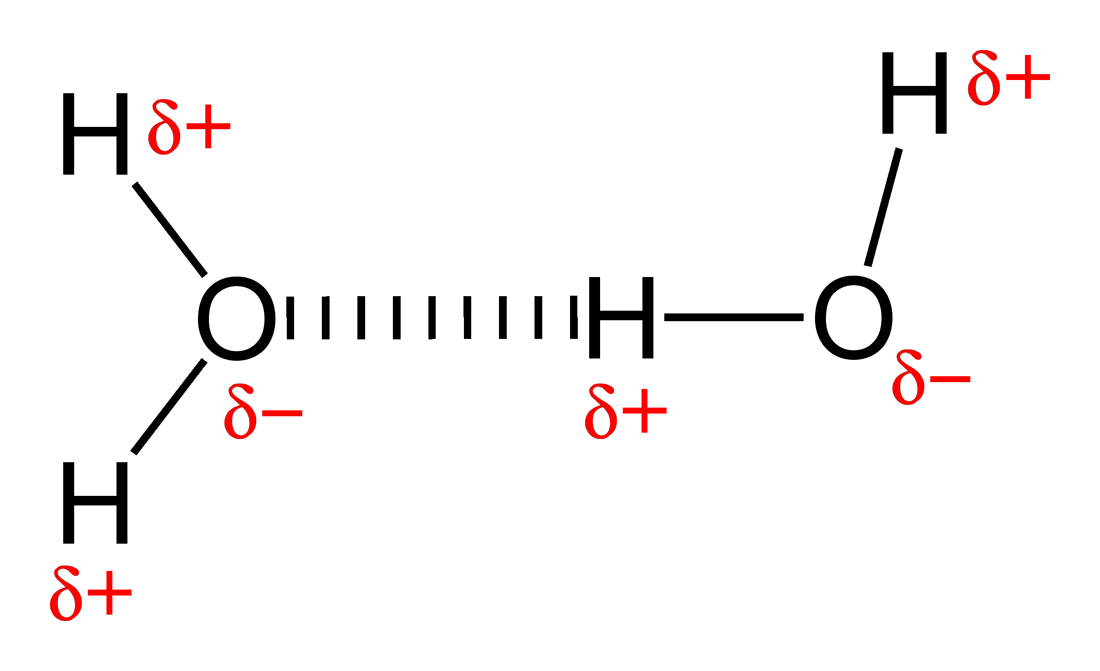
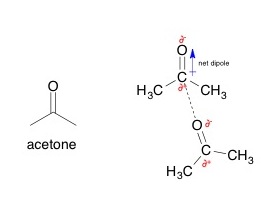
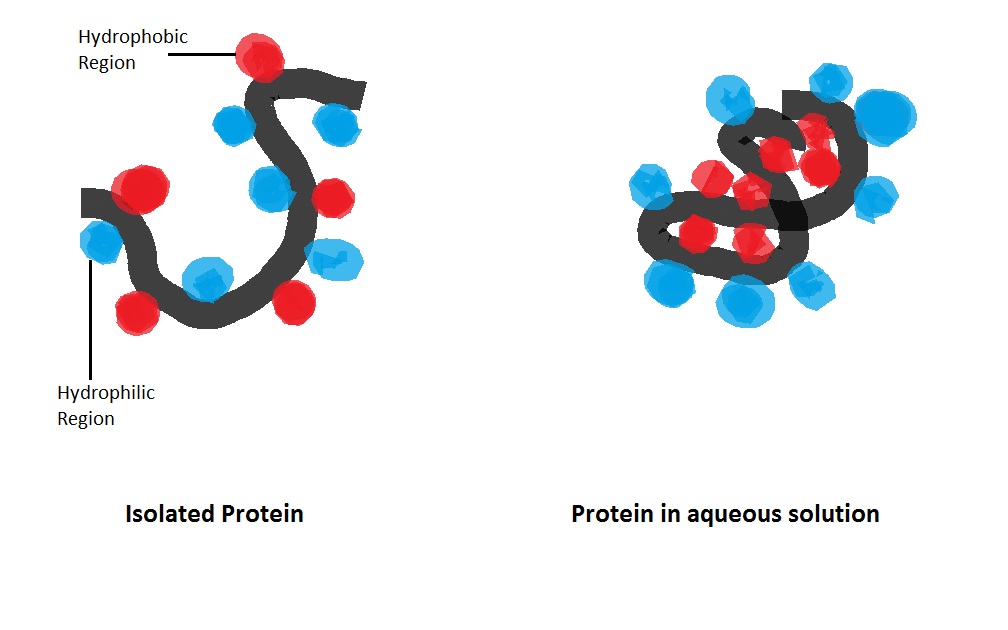
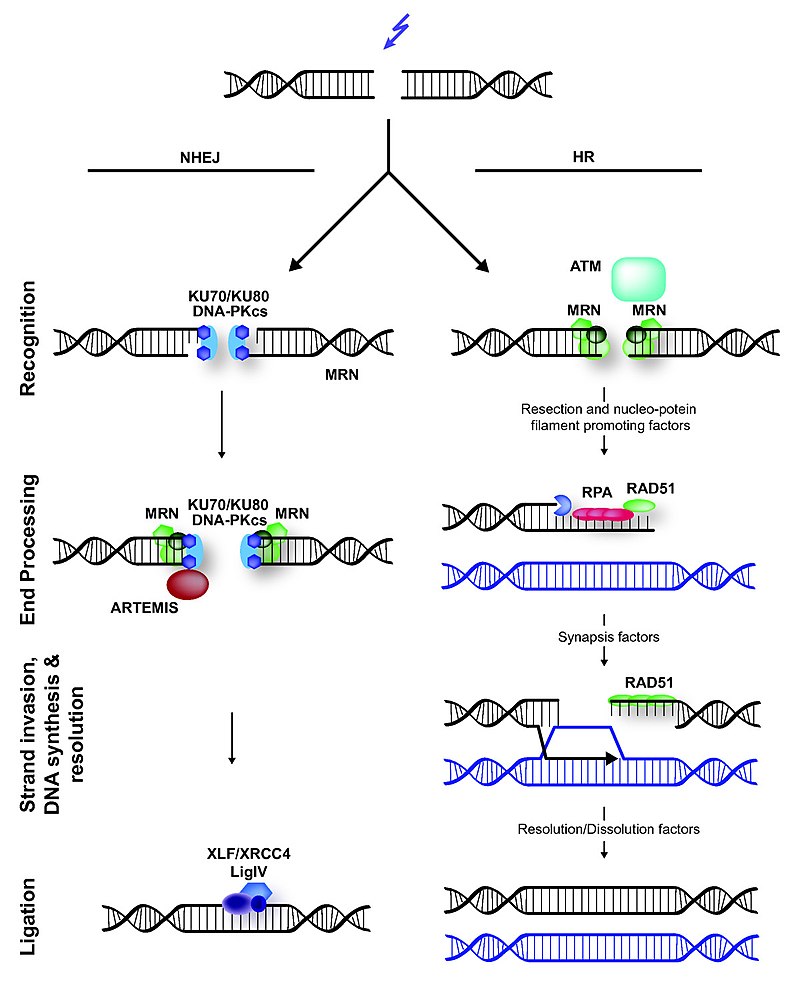
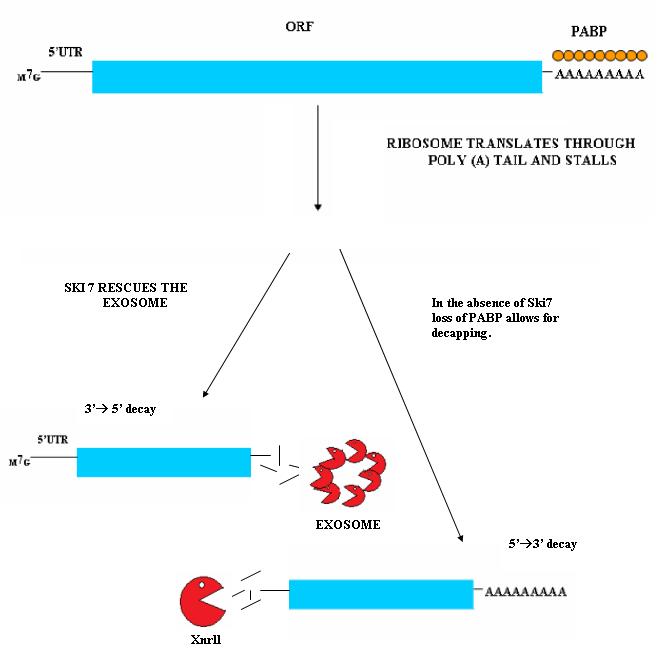
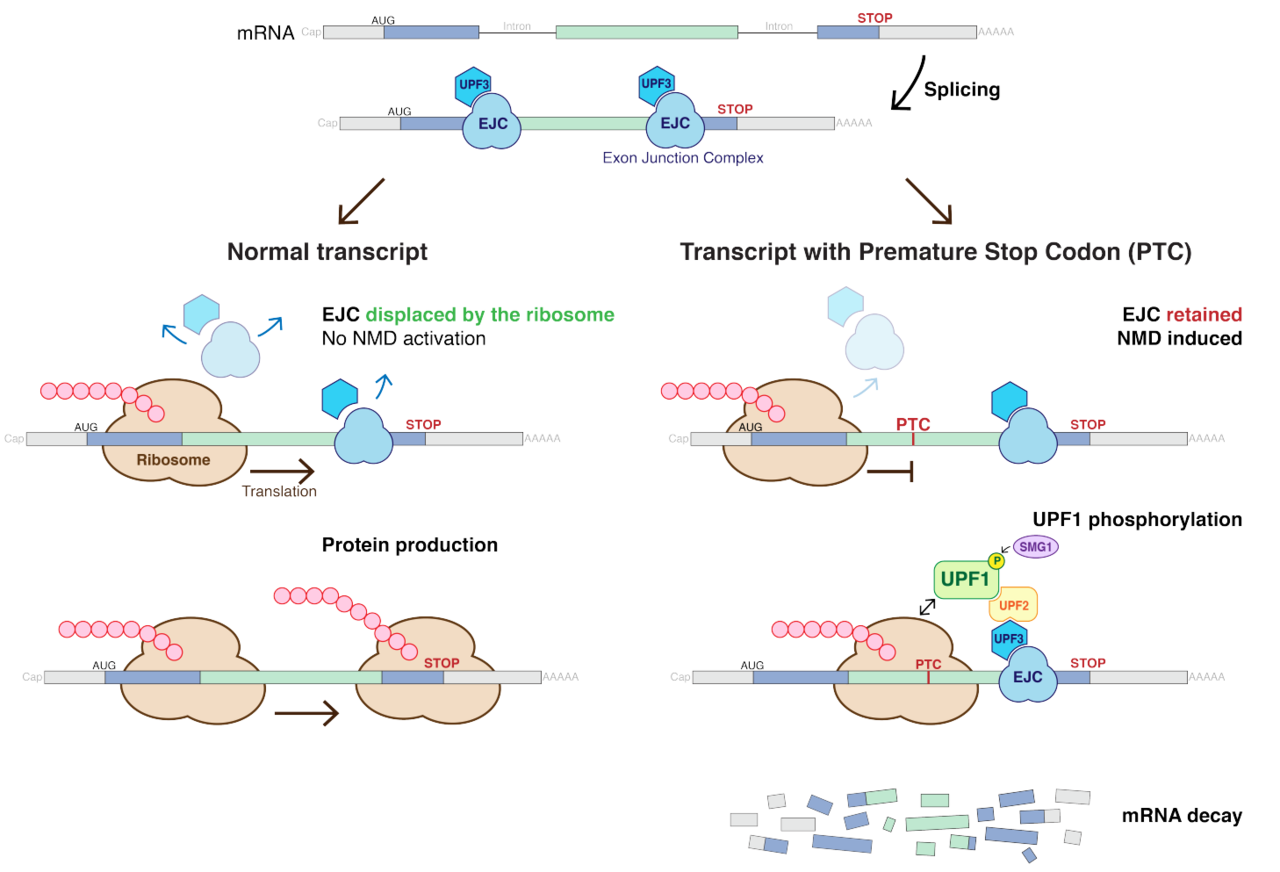
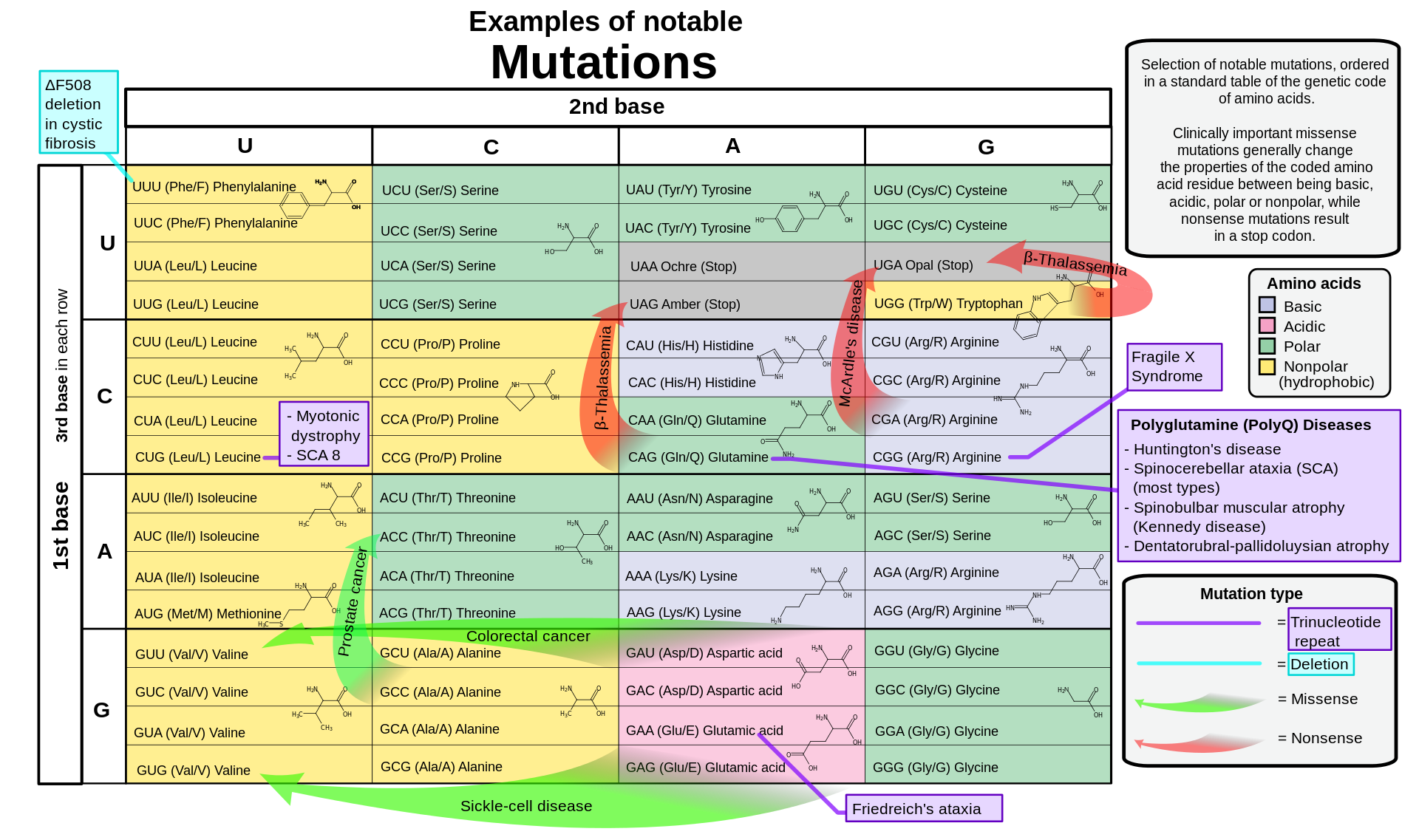
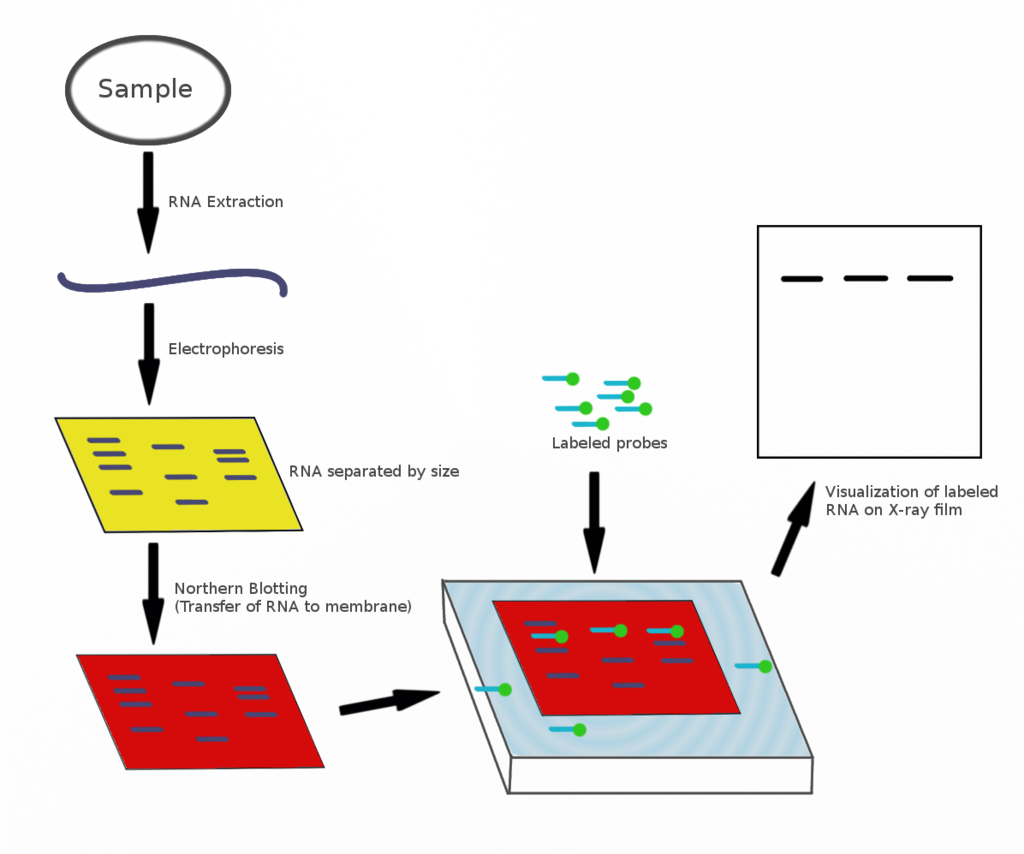

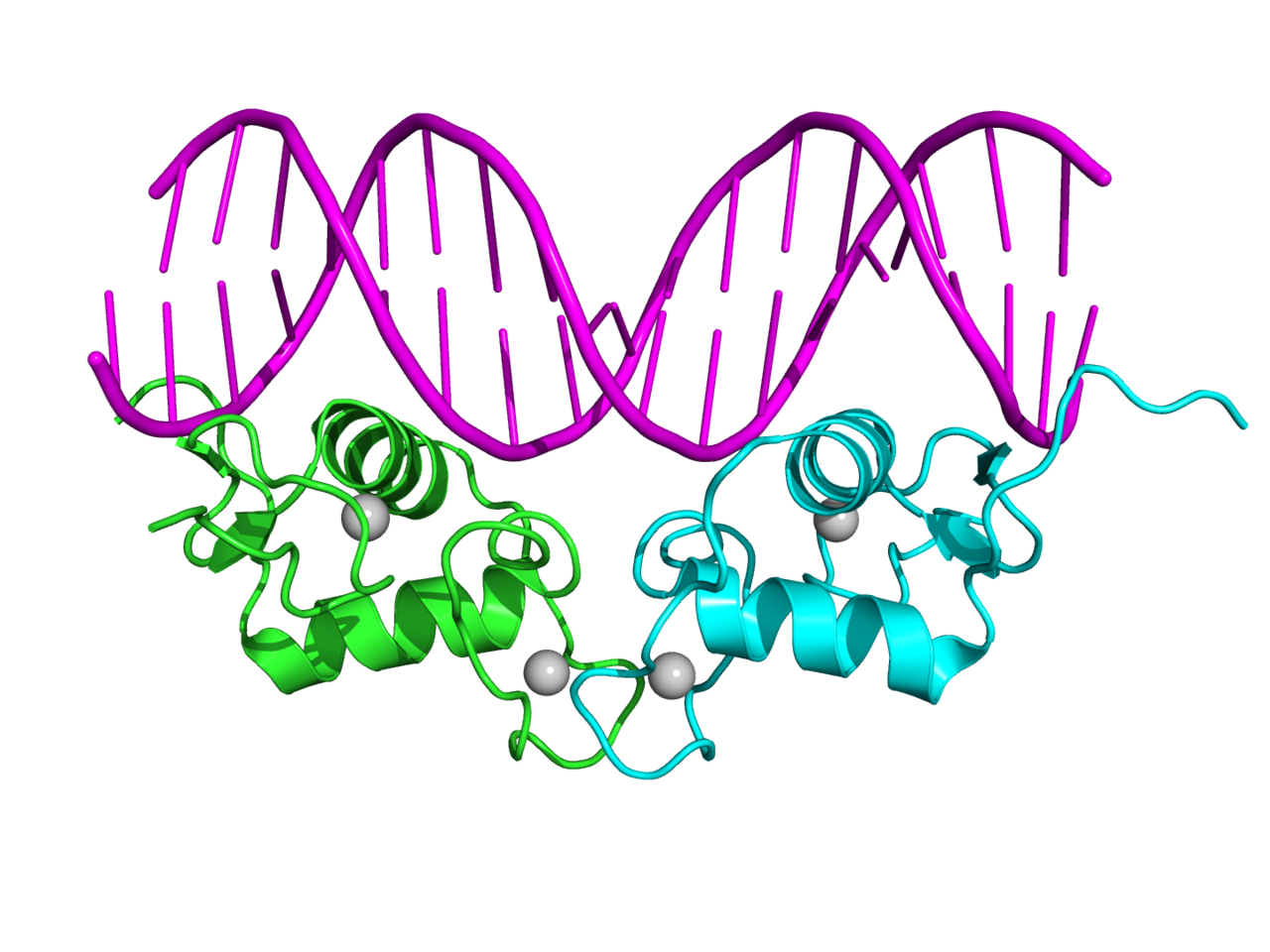
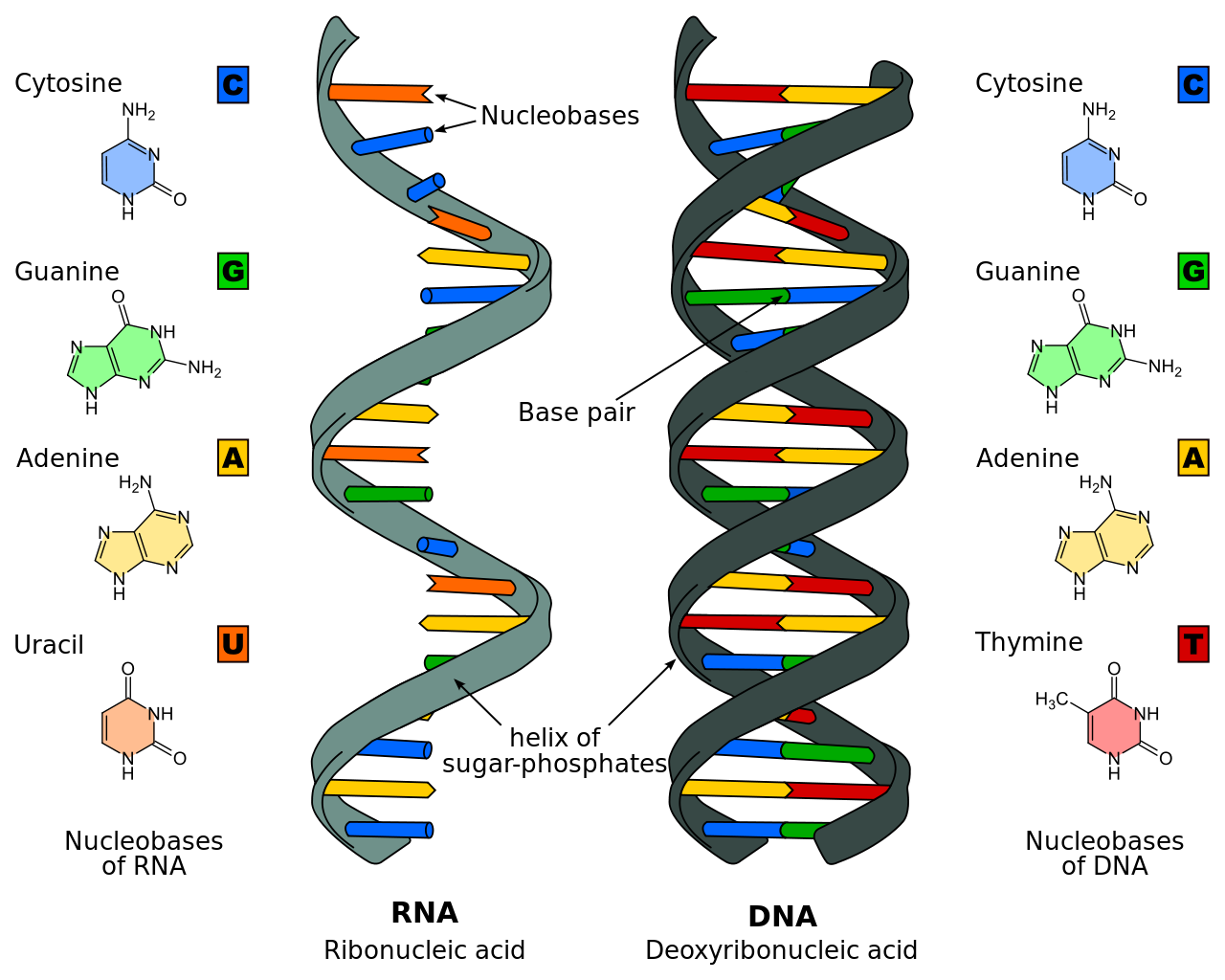


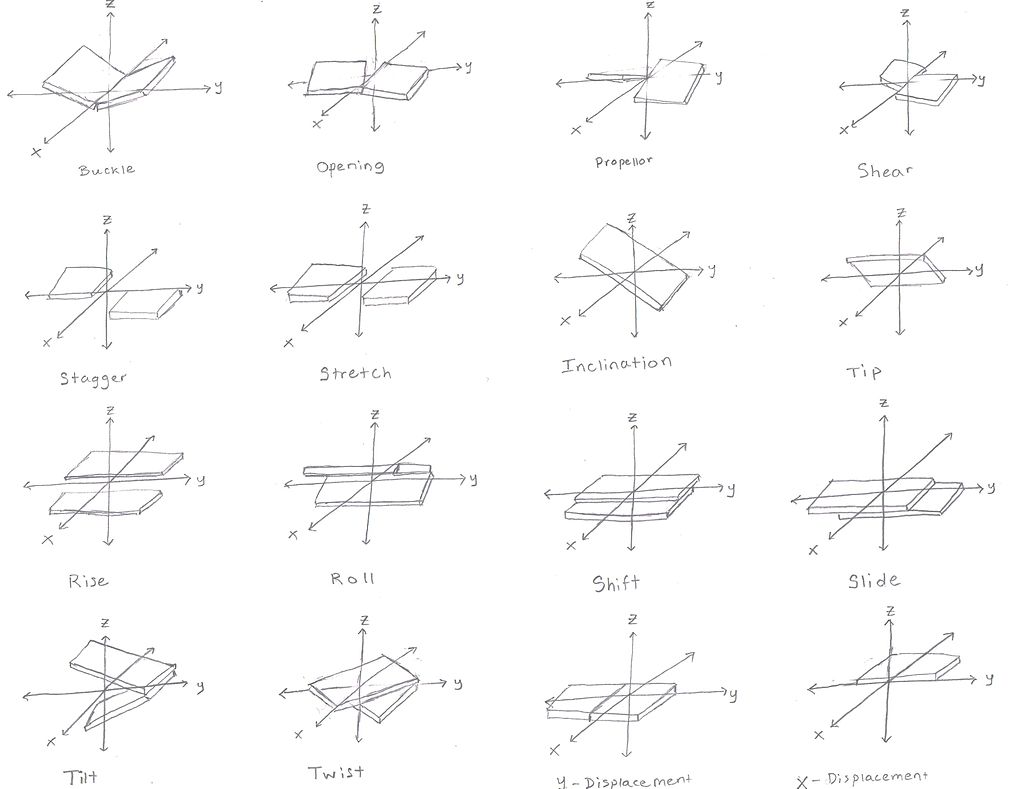
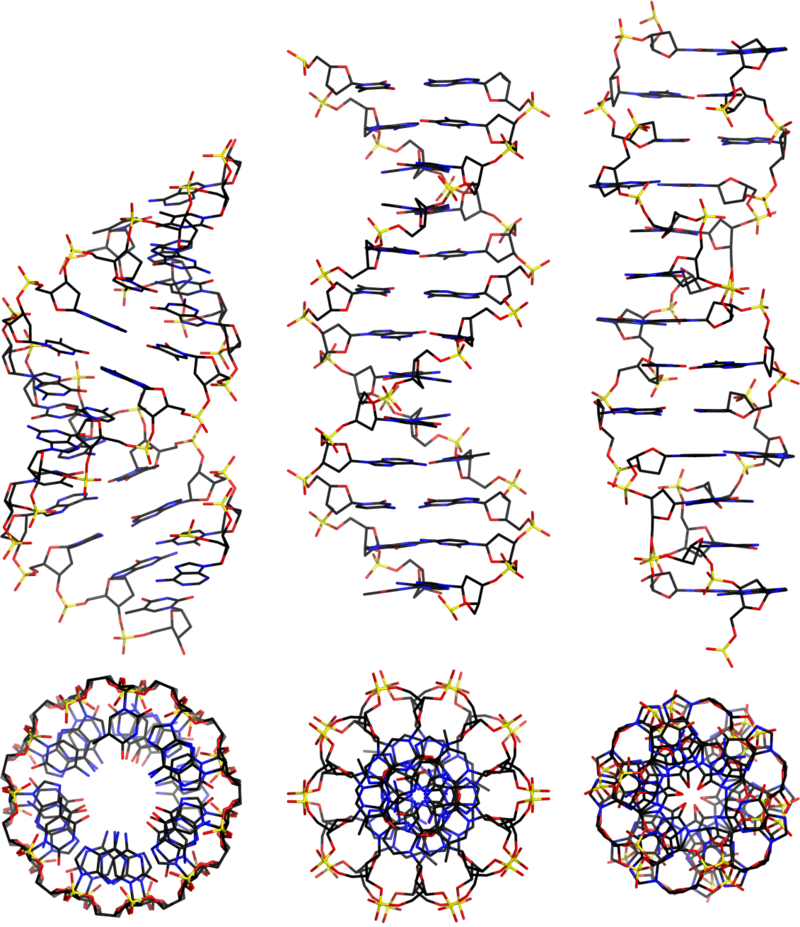
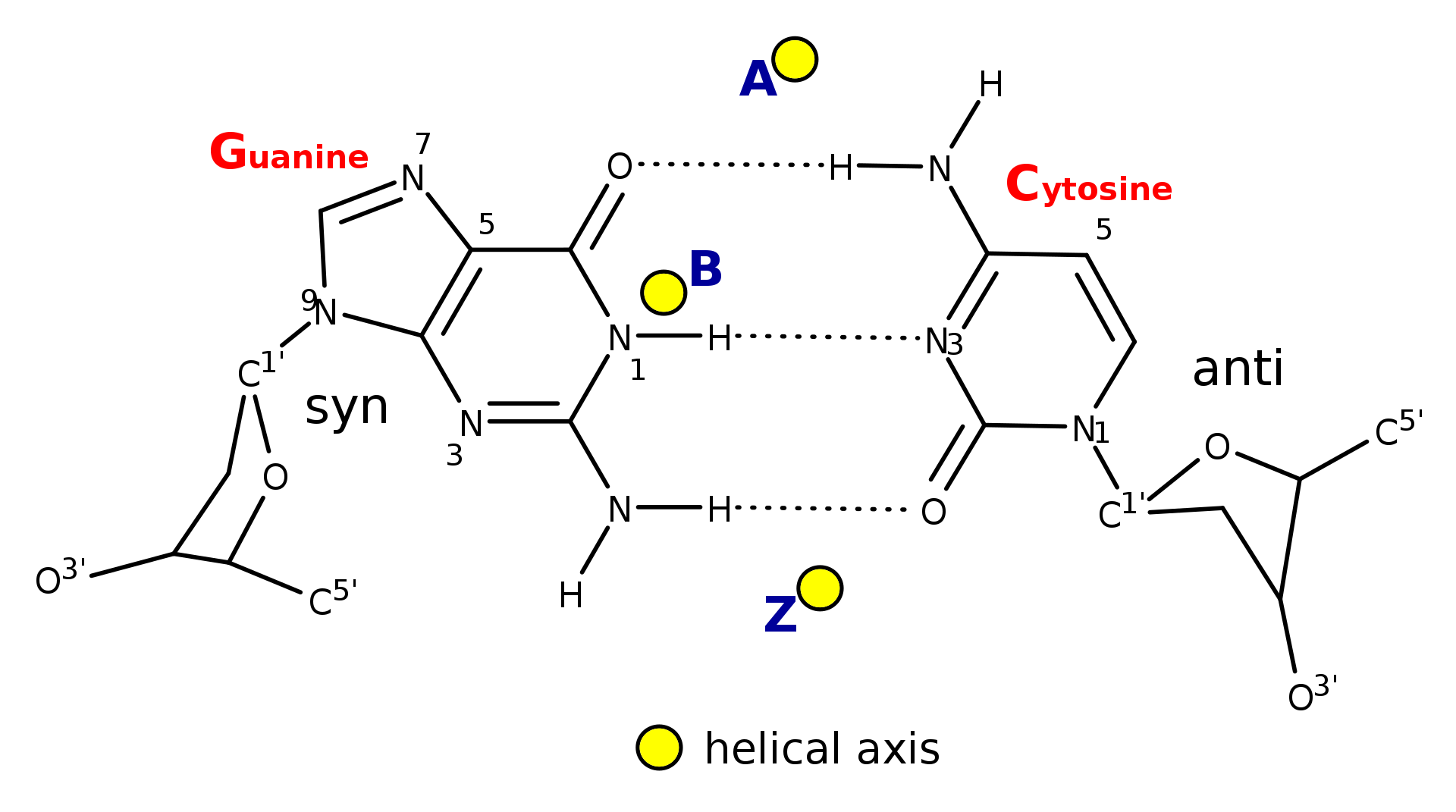
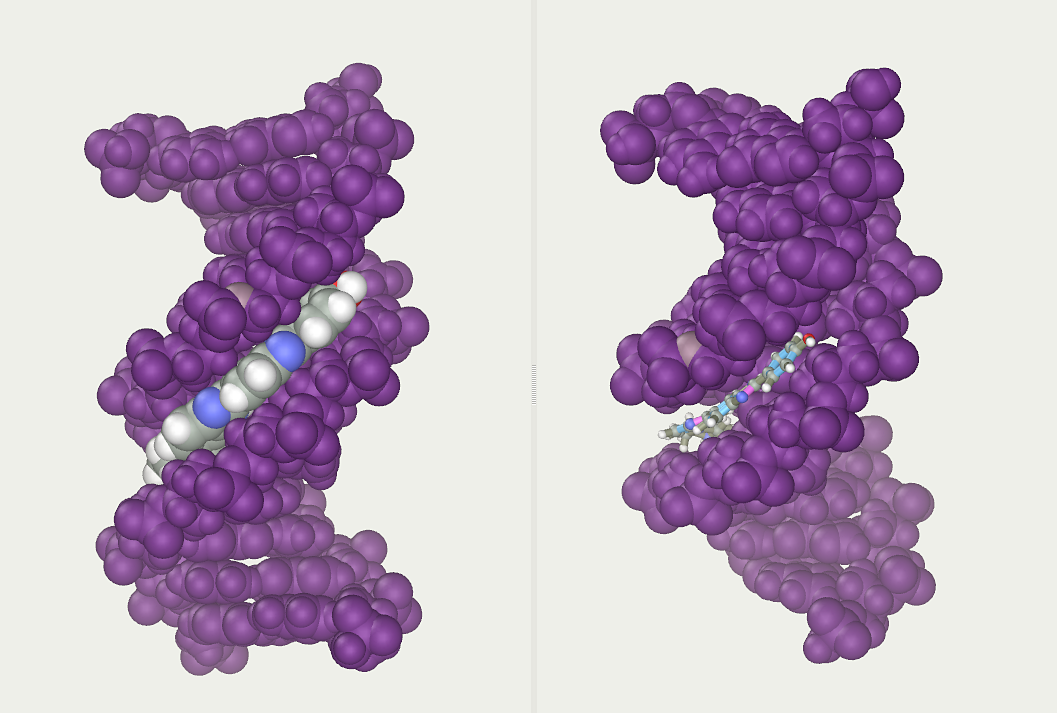
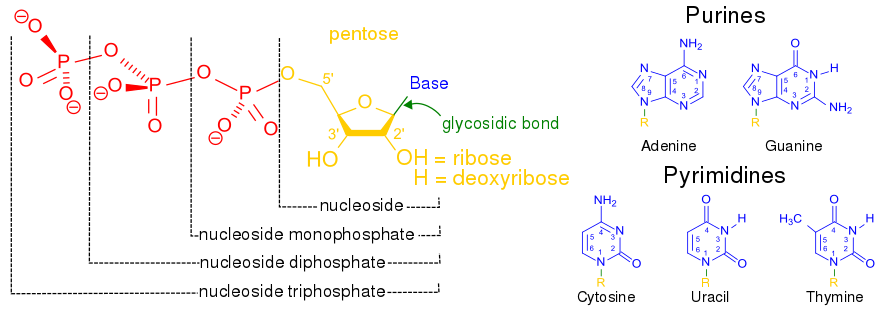
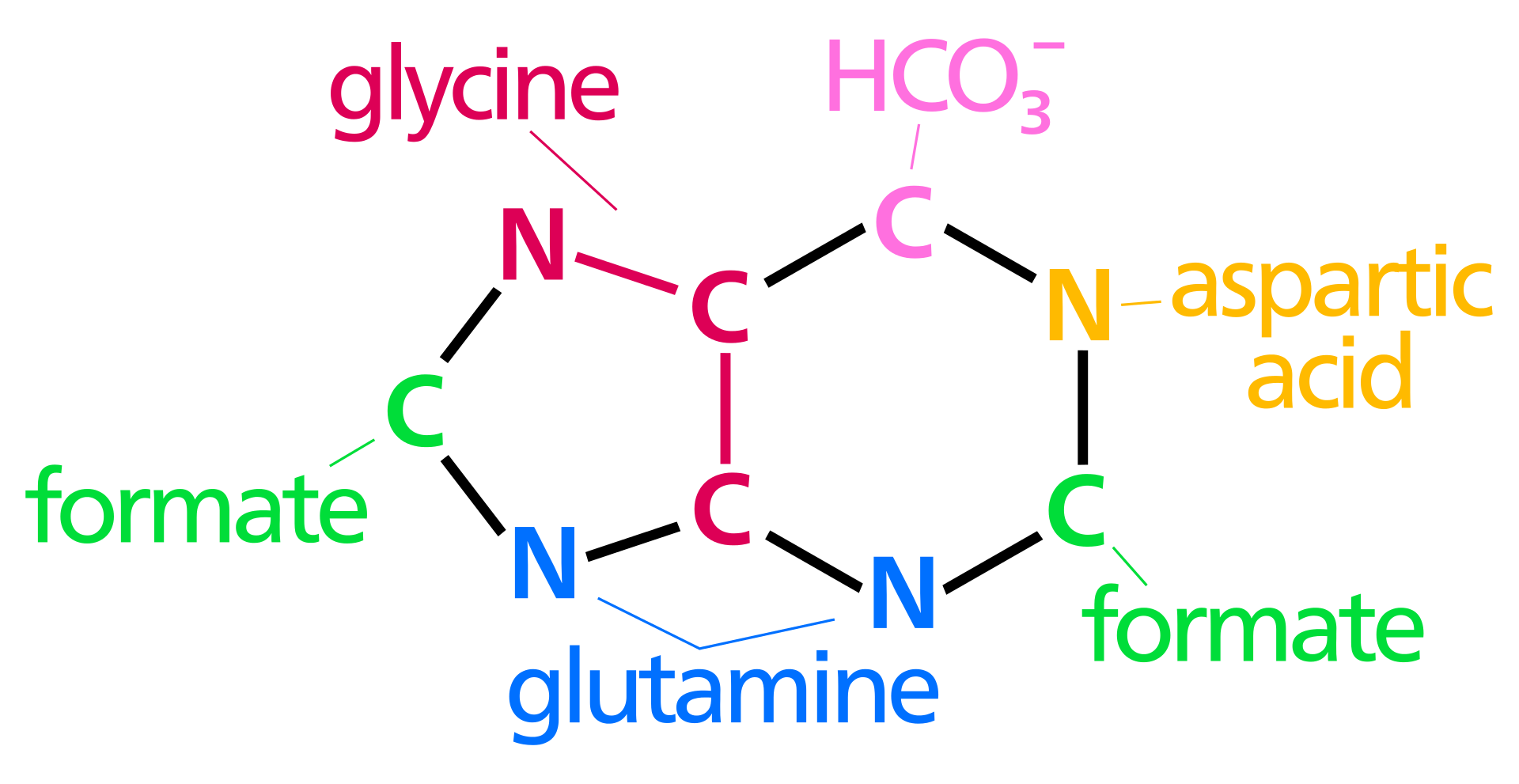
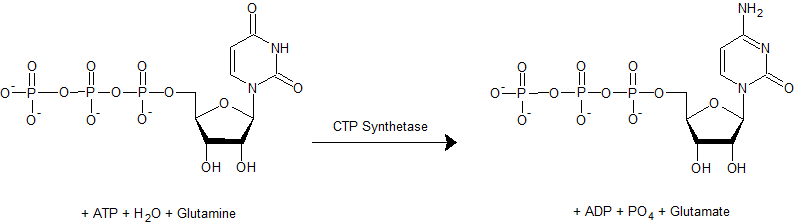
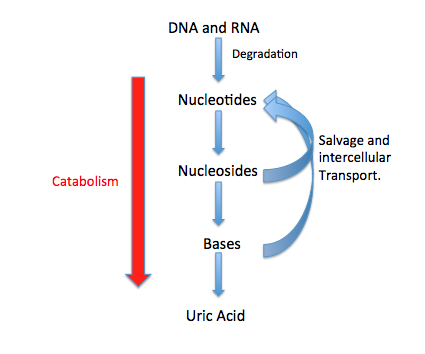
.png)
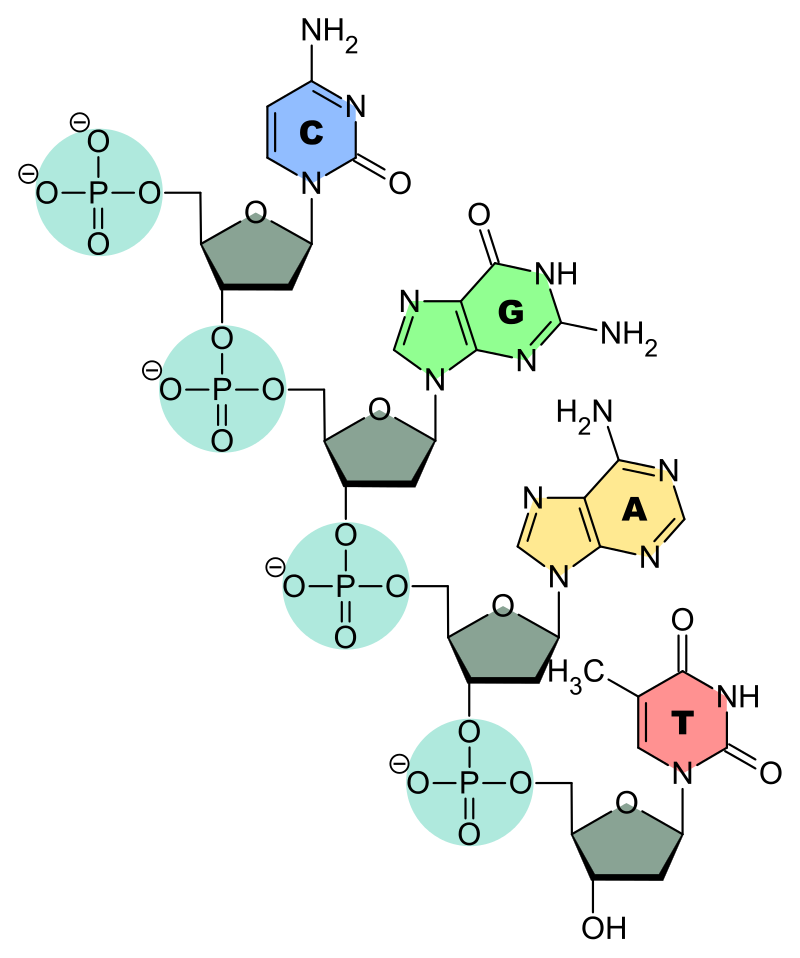
.png)
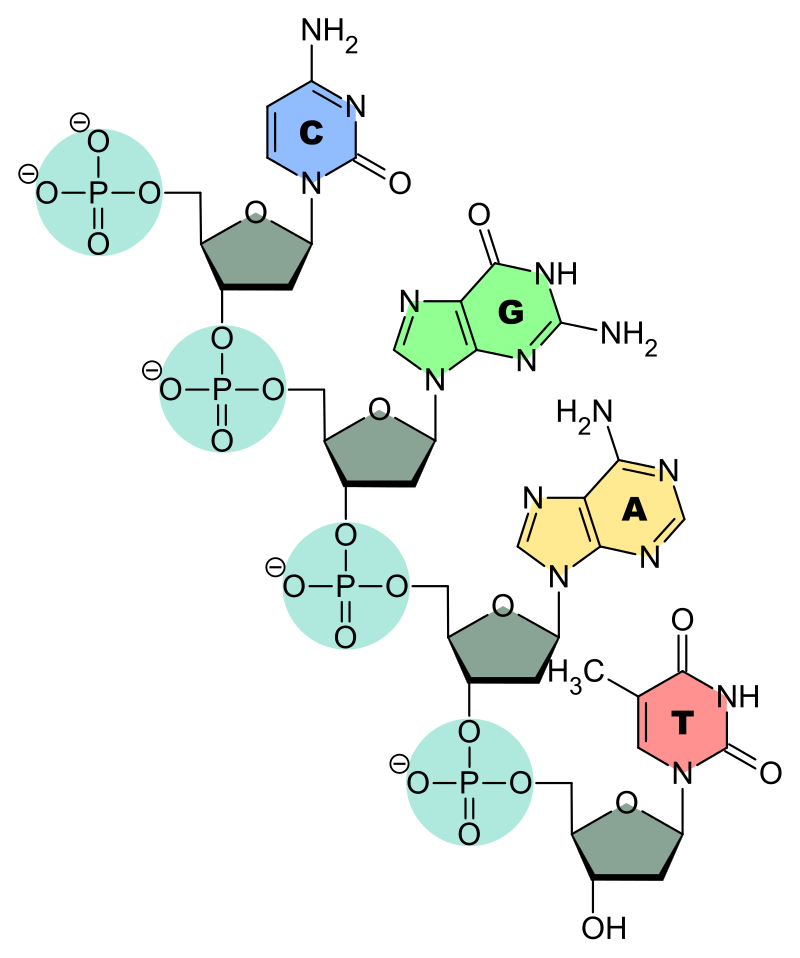
.png)